



Digital tools and technologies help organizations generate large amounts of data daily, requiring efficient governance and management. This is where the AWS data lake comes in. With the AWS data lake, organizations and businesses can store, analyze, and process structured and unstructured data of any size.
This article will focus on how businesses and organizations can improve decision-making using AWS’s scalable infrastructure and services.
Table of Contents
Overview of AWS Data Lake
AWS Data Lake is an integrated and centralized data platform that you can use to store structured and unstructured data of any size and scale. You can store your data in any format you want without having to structure the data and run different types of analytics, from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions. It can be integrated with services like Athena, Glue, and QuickSight.
Key Features of AWS Data Lake
- Scalability: With data lakes built on Amazon S3, you and your organizations can use critical AWS services to run big data analytics and even artificial intelligence (AI) ML applications to gain insights from your unstructured datasets.
- Seamless Integrations: it can handle the ingestion of any data size in real-time or batch seamlessly
- Ease of Use: It is easy for every member of the team, from the data analyst to the developer, to access data with their preferred choice of analytical tools and frameworks
- Data Governance: With its built-in data security and compliance tools, it ensures accurate data governance.
- Quick Innovation: Data lakes on AWS allow you and your organization to innovate faster with the most comprehensive set of AI and ML services.
Why Do You Need a Data Lake?
Data lakes provide a cost-effective cloud-based storage platform that allows you to ingest, transform, analyze, and visualize all forms of data. It can also be used to break down data silos to maximize end-to-end data insights. The main reasons why you should consider having a data lake are as follows:
- Data Management: Data lakes can efficiently manage structured, semi-structured, and unstructured data in one storage.
- Cost-Effective Storage: Data lakes are very cost-efficient, especially with their tiered pricing for cold and hot storage, including predictive analytics and machine learning.
- Collaboration: Allows multiple teams to access shared datasets for various use cases.
- Enhanced Analytics: Data lakes can also support advanced tools for deeper insights.
Hevo makes it simple to move your data into any data lake or warehouse. With no-code, automated pipelines, Hevo ensures seamless data migration from multiple sources to your destination, whether it’s a data lake or a data warehouse.
- Pre and post-load transformations to clean and structure your data
- Auto-schema mapping for smooth, error-free migration
- Real-time data processing with 150+ supported sources, including 60+ free sources.
Make the switch to a reliable, efficient data migration tool with Hevo and join over 2000+ customers across 45 countries who’ve streamlined their data operations with Hevo.
Get Started with Hevo for FreeHow To Deploy Data Lakes in the Cloud?
Deploying a data lake on AWS involves the following steps below:
- Log in to your AWS account
- Configure Amazon S3 as the primary storage.
- Use AWS Glue for your catalog and metadata management.
- Then, enable services like Athena to query and process the data directly.
- Afterwards, apply data governance.
Essential Elements of a Data Lake and Analytics Solution
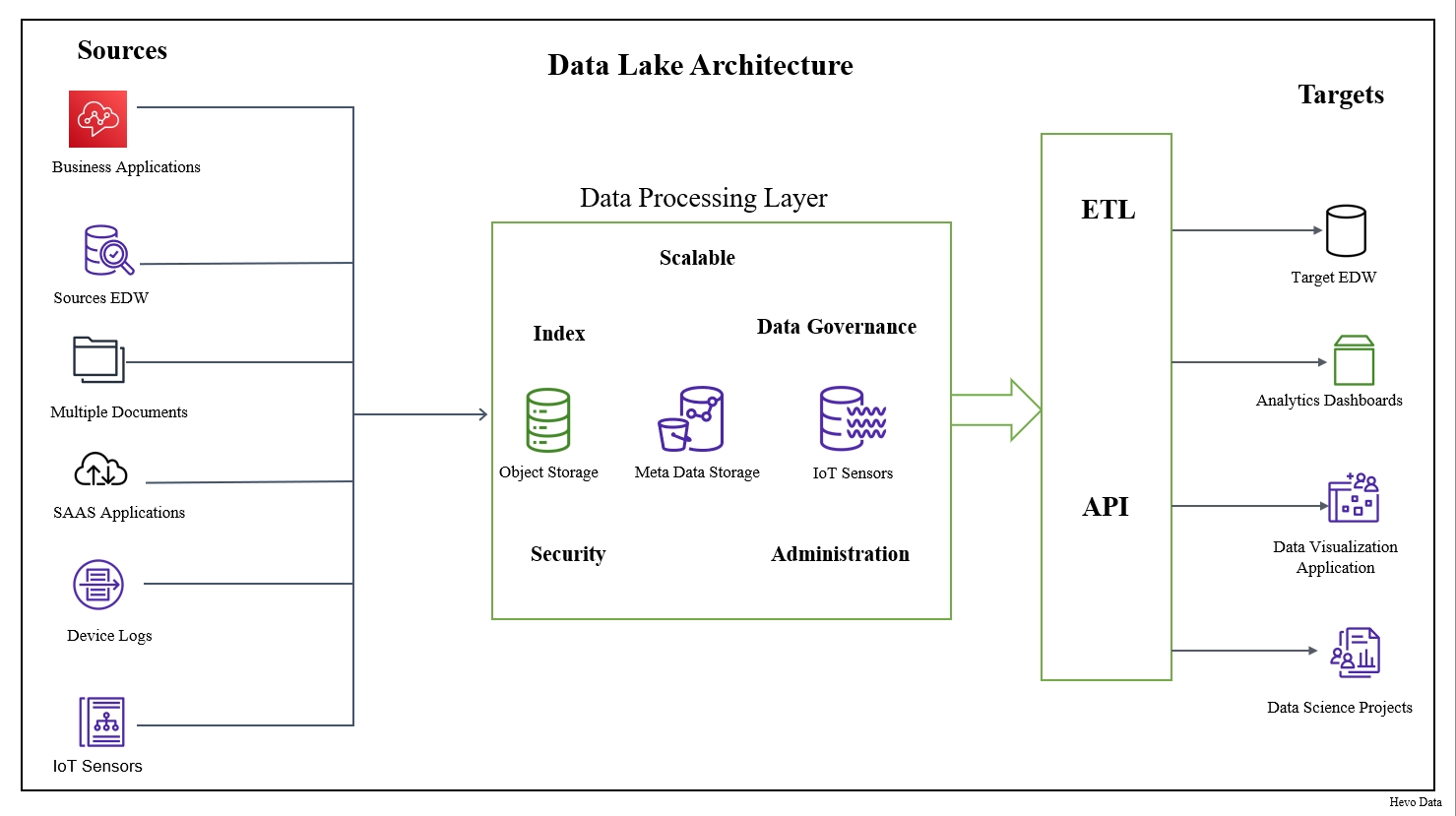
1. Data Ingestion & Storage
- Multiple Data Sources: A data lake must be accessible to any data source, such as external APIs and data storage, internal databases, and IoT devices.
- Scalable Storage: A data lake must be robust and have scalable storage layers (AWS S3, Azure Blob Storage, or Google Cloud Storage) to handle large volumes of data in various formats (structured, semi-structured, unstructured).
- Data Formats: A data lake must be able to process data in different formats, such as CSV, JSON, Parquet, Avro, and others.
2. Data Processing and Transformation
- Data Transformation: A data lake should be able to perform data cleaning, transformation, enrichment, and feature engineering on ingested datasets using tools like Apache Spark, Hadoop, and cloud-native services.
- Data Wrangling: It must support data discovery, profiling, and cleaning to prepare data for analysis and further use.
3. Data Management and Governance
- Metadata Management: A data lake must be able to record and manage the metadata of the various datasets that pass through it. Data lake is essential for data discoverability and traceability.
- Data Quality: A data lake can implement data quality checks and initiate the tools to ensure data accuracy and reliability.
- Data Security: A data lake has robust security measures in place to protect sensitive data.
- Data Governance: It has established data governance policies that organizations can use to ensure data quality, security, and compliance.
4. Data Analytics & Exploration
- Data Discovery: Tools and techniques for data exploration and discovery, such as data profiling, visualization, and exploratory analysis.
- Analytical Tools: Supports various analytical tools and frameworks, including SQL, Python (with libraries like Pandas, NumPy, and scikit-learn), machine learning libraries, and data visualization tools.
- Interactive Analysis: A data lake should support interactive data exploration and analysis through tools like Jupyter Notebooks, data visualization dashboards, and interactive SQL queries.
5. Data Consumption
- Business Intelligence & Reporting: Integration with business intelligence tools for reporting, dashboarding, and data visualization.
- Machine Learning & AI: Support for machine learning model training, deployment, and monitoring.
- Data Science & Research: Enable data scientists to conduct advanced research and analysis.
Data lakes allow organizations to generate insights, such as reporting on historical data and machine learning. Machine learning can be used to build models that forecast likely outcomes and suggest actions to achieve the optimal result.
How To Build a Data Lake on AWS?
Here is a step-by-step guide below on how to build a data lake system on AWS platform:
1. Identify the Purpose of Building the Data Lake: For instance, data analytics, machine learning, and even archiving.
2. Set Up Your AWS Environment: Ensure you have an active AWS account with the necessary permissions to access and create the required services, such as the IAM roles and policies.
3. Create an S3 Bucket: This will serve as the primary storage layer for your data lake. Define a folder structure for raw, transformed, and curated data.
4. Set Up AWS Glue for ETL: Use AWS Glue to extract, transform, and load (ETL) data into a structured format.
5. Enable Querying With AWS Athena: Query the data directly from S3 using Athena SQL.
6. Automate Data Ingestion: Amazon Kinesis Data Streams can be used for streaming data, AWS Lambda for serverless data ingestion and transformation, and AWS Database Migration Service (DMS) for migrating database content.
7. Data Governance and Security: Use the AWS Glue Data Catalog to manage metadata and track data lineage while enabling data encryption in transit and at rest. Cloud trails should also be used to monitor data access and implement fine-grained access with lake formation.
8. Visualize and Analyze Data: Take advantage of AWS QuickSight for visualization and SageMaker for machine learning.
9. Test and Monitor: Test the entire workflow for query performance and use CloudWatch for monitoring and alerts.
10. Scale and Optimize: Optimise and scale with S3 intelligent and Redshift for performing complex analysis
Best Practices for Building a Data Lake on AWS
Below are some of the best practices for building a data lake on AWS:
- Always Begin With a Clear Data Lake Plan: Always have a clear strategy before designing your data lake. These strategies include the data that will be stored in the data lake and the tools and services that will be used to manage the data lake.
- Use a Consistent Data Model: This will make it easier to manage and analyze your data.
- Use Data Lake Management Tools: Take advantage of the data management tools to automate tasks and manage the entire workflow.
- Monitor Your Data Lake: Use AWS Cloudwatch to monitor your data lake in real-time and ensure it performs as expected.
- Data Partitioning: Organize data by partitions to enhance query performance.
AWS Data Lake vs. Data Warehouse
| Feature | AWS Data Lake | AWS Data Warehouse |
| Data Type | Structured, Semi-structured Unstructured | Structured and Semi-structured |
| Storage | Low-cost S3 storage | High-performance columnar storage |
| Processing | Batch and real-time | Optimized for analytics queries |
| Scalability | Highly Scalable | Scalable but optimized for structured data |
| Use Case | Machine learning, Exploratory Analysis | Business Intelligence Reporting |
Take a look at Data Lake vs Data Warehouse in detail to help you decide which platform you should choose.
Benefits of Using AWS Data Lake
- Store All of Your Datasets: You can store all of your datasets in a cost-effective environment without any limit.
- Innovative Benchmark: Having all your data in one place is critical to machine learning and predictive analytics, which can increase your performance and accelerate your team’s innovation.
- The Better Tool: The built-in AWS analytics services allow organizations to extract insights using the most appropriate tool. It is optimized to give organizations the best performance at scale and an affordable cost.
- Serverless: It provides the most serverless option and easy-to-use data analytics services in the cloud.
Challenges of Implementing AWS Data Lakes
- Complexity: Setting up the data lakes at first can be very complex, and its maintenance requires expertise
- Cost Management: Over-provisioning can lead to increased costs.
- Data Governance: Ensuring data quality and compliance demands additional effort.
- Integration: Connecting legacy systems with AWS services may require additional tools.
Use Cases of AWS Data Lakes
- Customer Analytics: Centralized customer data enables personalized marketing campaigns.
- IoT Data Management: Ingests and processes IoT device data in real-time using Kinesis.
- Machine Learning: AWS SageMaker trains models on curated datasets stored in the lake.
- Healthcare: Stores electronic health records for advanced analytics and reporting.
- Log Analytics: Analyzes log data using AWS EMR or Athena.
Learn more
Conclusion
AWS Data Lake is an integrated and centralized data platform that combines data storage, governance, analytics, machine learning, and visualization services for businesses and organizations. It allows organizations to store structured and unstructured data, analyze it, and perform machine learning activities, empowering them to gain actionable insights from their data and make informed decisions.
Loading data from your data sources into a Data Lake can become much easier, more convenient, and cost-effective when using third-party ETL/ELT platforms like Hevo Data. Try a 14-day free trial to explore all features, and check out our unbeatable pricing for the best plan for your needs.
FAQs
1. What is an AWS data lake?
An AWS Data Lake is a centralized repository on Amazon S3 for storing, processing, and analyzing diverse datasets using AWS analytics services.
2. Is AWS S3 a data lake or data warehouse?
AWS S3 serves as the storage foundation for a data lake but is not a data warehouse.
3. What is the AWS equivalent of a data lake?
Amazon S3, combined with AWS Glue and analytics tools, forms AWS’s equivalent of a data lake.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





