

AWS Glue is a fully managed serverless ETL service that simplifies preparing and loading data for analytics. But how does it work? To answer that question, we need to understand its architecture. In this blog, we will discuss the AWS Glue architecture so you can fully understand how it works and optimize your data better.
Table of Contents
What is AWS Glue?
AWS Glue is a fully managed data integration service by Amazon Web Services. AWS Glue makes it easy to discover, prepare, move, and integrate your data across many sources for analytics, machine learning, and application development. If your data resides in the Amazon Ecosystem, such as in Amazon S3, RDS, or Redshift, AWS Glue makes getting your data ready for use far easier. You can run your own notebook or run your Python or Scala scripts for data ingestion. You can also use Glue’s drag-and-drop workflows to simplify data migration.
Hevo is an automated data pipeline solution that facilitates loading data from over 150 sources into your chosen destination. It converts data into an analysis-ready format without the need for any coding.
Here are some compelling reasons to try Hevo:
- Data Transformation: Hevo offers an intuitive interface to refine, alter, and enhance your data for transfer.
- Schema Management: Hevo automatically identifies the schema of incoming data and aligns it with the destination schema.
- Scalable Infrastructure: Hevo scales horizontally as your data sources and volume increase, efficiently handling millions of records per minute with minimal latency.
- Accelerated Insight Generation: Hevo enables near real-time data replication, allowing you to derive insights promptly and make quicker decisions.
AWS Glue Architecture: An Overview

The AWS Glue architecture comprises several key components; each component plays a vital role in the data processing pipeline. Here’s a breakdown of these components based on the architecture diagram:
- Data Source
- Crawler
- Data Catalog
- Transform (Script)
- AWS Management Console
- Schedule or Event
- Data Target
Each of these components is designed to streamline the ETL process. Let’s explore them in detail.
1. Data Source
The data source is the starting point of your data journey. In AWS Glue, the data source could be any form of storage holding your data. It could be relational or NoSQL databases, a data lake like Amazon S3, or local on-premises.
Now, consider that customer data is incoming from various databases, such as MySQL, PostgreSQL, and Amazon S3. You could think of these as sources for your data. AWS Glue will connect to such sources, extract the data, and prepare it for transformation.
How it works:
- AWS Glue supports multiple data formats like JSON, CSV, Parquet, ORC, and Avro.
- It uses JDBC or other data connectors to fetch data from databases.
- Data is extracted in its raw form and then processed for additional analysis.
2. Crawler
Once you’ve defined your data sources, the Crawler comes into play. The Crawler crawls through your data source, analyzing the data and gathering metadata to understand the schema and structure of the data.
What the Crawler does:
- It automatically infers the schema and properties of the data, like data types, partition keys, and table names.
- The crawler populates the AWS Glue Data Catalog with metadata, making it easier to query and manage the data.
Example: Suppose your data source is a directory in Amazon S3 containing thousands of JSON files. The crawler will scan these files, identify their structure, and create metadata entries in the Data Catalog, including table definitions and schema information.
3. Data Catalog
The Data Catalog is the core component of AWS Glue. It’s like a repository where all the metadata about your data sources is stored. This catalog acts as a central metadata store, helping you manage and organize your data assets efficiently.
Key features:
- Stores table definitions, job scripts, and connection information.
- Acts as a metadata store that’s accessible from other AWS services like Amazon Athena and Amazon Redshift.
- Keeps track of versions so that you can manage schema evolution over time.
Why it’s important: The Data Catalog enables you to run queries on your data without worrying about the underlying data formats or locations. You simply query the catalog using SQL-like syntax, and AWS Glue handles the rest.
4. Transform (Script)
Once your data is cataloged, it’s time to transform it. In the Transform step, you write the ETL logic to clean, enrich, and prepare your data for analysis. AWS Glue provides a built-in editor where you can write scripts in Python or Scala.
Transformations can include:
- Filtering out unnecessary data.
- Converting data types to match the target schema.
- Joining datasets from multiple sources.
- Aggregating data for summary reports.
AWS Glue uses Apache Spark under the hood to execute these transformations, which ensures that the processing is both fast and scalable.
NOTE: AWS Glue also provides pre-built transformations that you can use, making it easier to perform common tasks without writing custom code.
5. AWS Management Console
The AWS Management Console is your gateway to managing AWS Glue. From the console, you can configure, monitor, and manage your Glue jobs, data catalog, crawlers, and more.
What you can do in the console:
- Create and schedule ETL jobs.
- Monitor job runs and check logs for errors.
- Set up triggers based on events or schedules.
The console provides a user-friendly interface that simplifies the management of your ETL workflows.
6. Schedule or Event
Scheduling is crucial in ETL processes, and AWS Glue provides multiple ways to trigger your jobs. You can either set up a Schedule or rely on an Event to kick off the job.
Options available:
- Schedule: You can define a schedule using cron expressions or fixed intervals to run your ETL jobs.
- Event-driven: You can trigger jobs based on specific events like data arrival in Amazon S3, changes in data sources, or custom events via AWS Lambda.
Example: You can schedule a job to run every night at 2 AM to pull in the latest sales data from your data sources, transform it, and load it into your data warehouse.
7. Data Target
The final step in the AWS Glue architecture is the Data Target. After transforming your data, it needs to be stored somewhere, right? This is where the data target comes in.
Possible Data Targets:
- Data Lakes like Amazon S3
- Data Warehouses like Amazon Redshift
- Relational databases like MySQL or PostgreSQL
- NoSQL databases like Amazon DynamoDB
How it works: AWS Glue loads the transformed data into your specified target, making it ready for querying, reporting, or further analytics.
Example: You could load the processed data into Amazon Redshift to be queried by business intelligence tools like Tableau or store it in Amazon S3 for long-term storage.
Putting it All Together
Now that we’ve walked through each component of the AWS Glue architecture let’s put it all together:
- Extract: You start by defining your data sources (e.g., S3, RDS, on-premises databases).
- Crawl: AWS Glue Crawler scans the data sources and gathers metadata.
- Catalog: The Crawler populates the Data Catalog with the metadata, creating a centralized repository.
- Transform: You write ETL scripts to transform the data according to your needs.
- Schedule/Manage: Use the AWS Management Console to schedule and manage your jobs.
- Load: The transformed data is loaded into your data target (e.g., S3, Redshift).
By following this architecture, you can efficiently manage the entire ETL process, from extracting raw data to loading it into your desired target for analysis.

Looking for Alternatives
Did you notice how you need to choose different tools in the AWS ecosystem itself to perform your data migration? Try out Hevo, where all this is present on one platform. With Hevo, you can:
- Select from a list of 150+ sources. If you didn’t find your source, configure it using REST APIs.
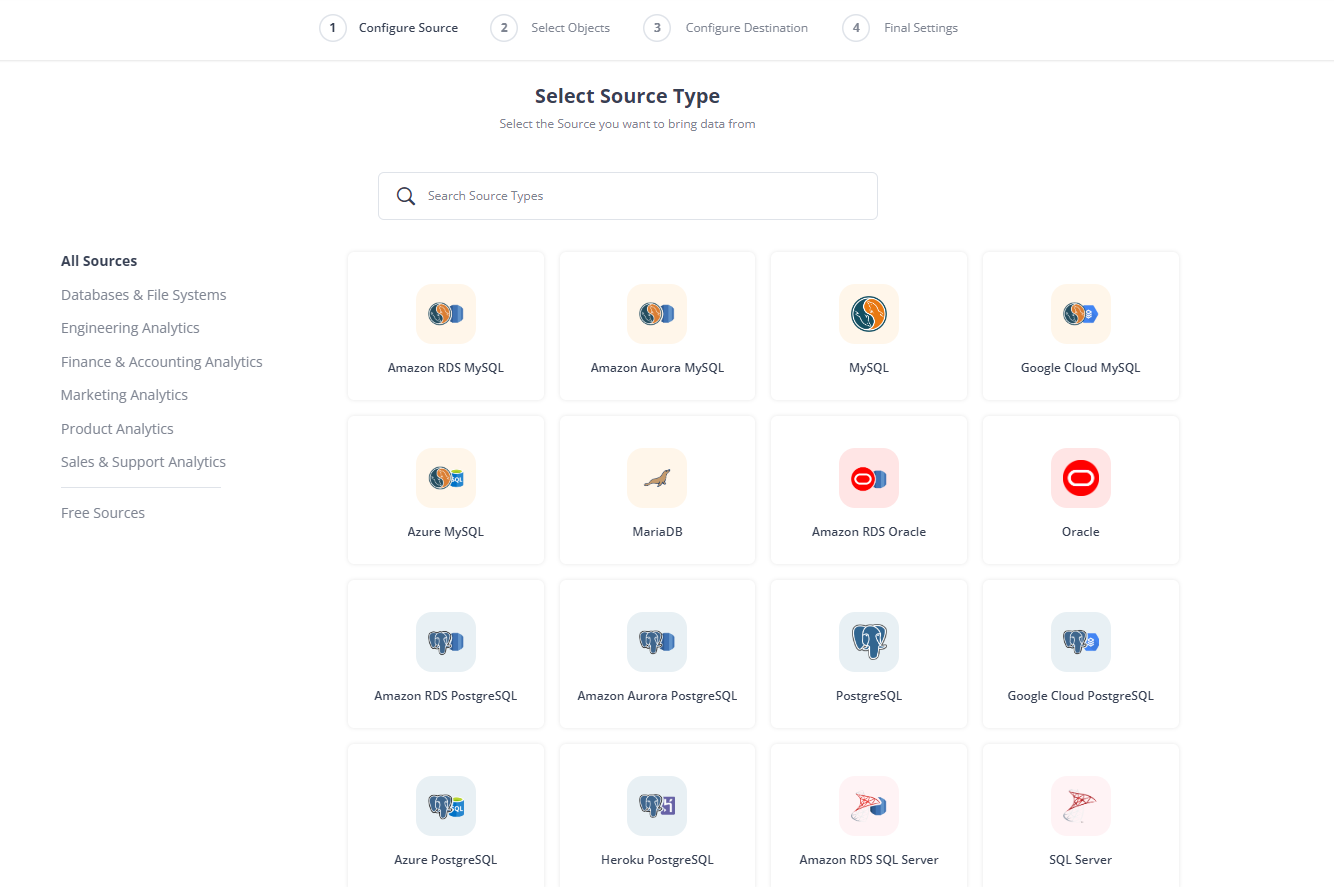
- If you don’t want to handle the schema manually, choose Auto Schema Mapper. Hevo handles the schema mapping, so you won’t have to worry about data loss or inconsistency.
- Configure your Destination.

And you are done!
Additionally, suppose you want transformations done before or even after the loading. For your convenience, Hevo has both Pre and Post-Load Transformations and a Python-based script or a simple drag-and-drop interface. You can even query the data in your destination from the Hevo platform itself. Hevo also supports real-time data ingestion with CDC capabilities.
Conclusion
Understanding the architecture of AWS Glue is crucial if you want to leverage its full potential. Whether you’re dealing with a simple ETL task or a complex data integration scenario, AWS Glue provides a scalable, flexible, and cost-effective solution. By breaking down the architecture and explaining each component, I hope this guide has made the AWS Glue architecture more approachable for you.
Considering a switch from AWS Glue? Hevo’s easy-to-use platform with real-time data processing might be what you need. Explore how AWS Glue alternatives could better meet your needs in our insightful guide.
FAQ on AWS Glue Architecture
What is the difference between AWS and AWS Glue?
AWS (Amazon Web Services) is a comprehensive cloud computing platform offering a wide range of services, including computing power, storage, and databases. AWS Glue is a specific service within AWS focused on ETL (Extract, Transform, Load) processes. While AWS is the broader ecosystem, AWS Glue is a specialized tool for automating data preparation and integration.
Is AWS Glue cloud-based?
Yes, AWS Glue is a fully managed, cloud-based ETL service provided by AWS. It runs in the cloud, allowing you to build, manage, and monitor ETL jobs without needing to manage the underlying infrastructure.
What is the difference between AWS Glue and Lambda?
AWS Glue is an ETL service designed for data preparation, transformation, and loading tasks, particularly for large-scale data processing. On the other hand, AWS Lambda is a serverless compute service that lets you run code in response to events without managing servers. While Glue is used for data workflows, Lambda executes small bits of code (functions) triggered by events like data changes or HTTP requests.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





