

Table of Contents
What is AWS Glue
AWS Glue is a serverless integration service that provides a simple, faster, and cheaper approach to discovering, preparing, and integrating data for modern ETL(Extract, Transform & Load) pipelines. Hence, data can be Extracted from the source, Transformed the way it is required, and Loaded into the data warehouse. It has a GUI to create pipelines.
AWS Glue consolidates all the data integration capabilities into a single service. These include Data cleaning, transforming, central cataloging, etc. Also, it does not require infrastructure management to run ETL jobs. It provides a visual interface where we can simply define your ETL logic. It is flexible enough to provide various kinds of workloads like ETL, ELT, and stream processing. It has integration interfaces and job-authoring tools which make it easy for all kinds of users from developers to data analysts.
AWS Glue Studio is a graphical user interface in which we can create, run, and monitor data integration workflows. We can seamlessly compose the workflow which runs on a Spark-based Serverless Engine in AWS Glue.
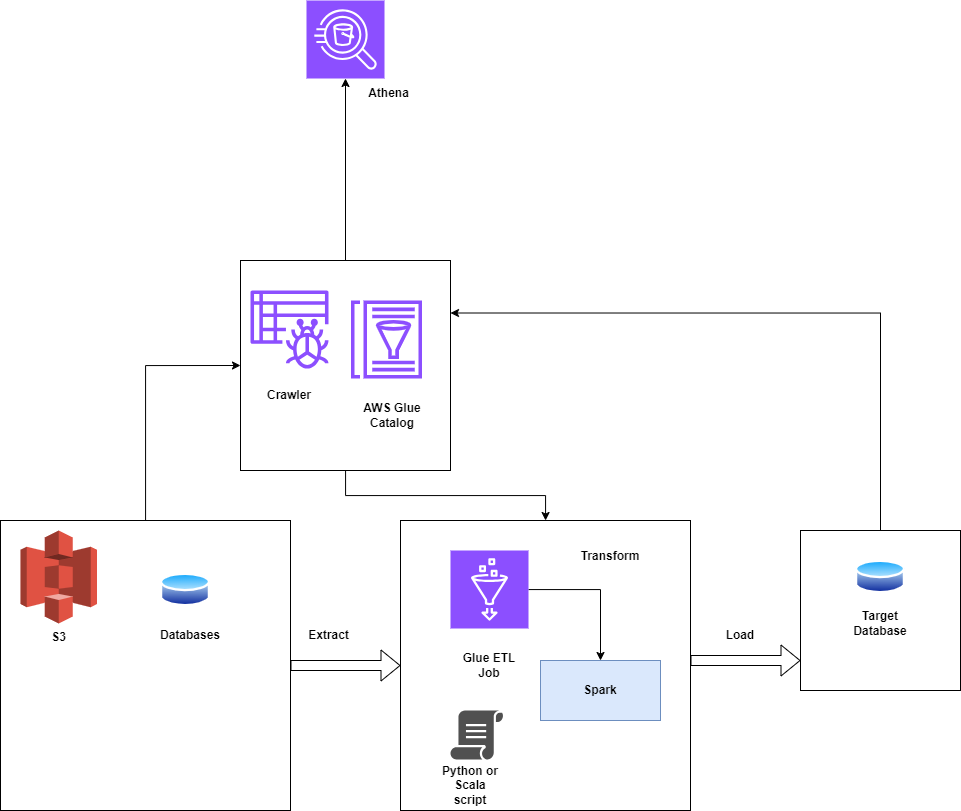
How AWS Glue ETL Works
- AWS Glue is an ETL tool to orchestrate your ETL pipeline to build a data warehouse, and data lake and generate output streams.
- AWS Glue calls an API to run your job, create run-time logs, store your job logic, and notify for job monitoring. The AWS Glue console connects these services so that you can focus only on writing ETLs.
- AWS Glue takes care of provisioning resources that are required to run the ETL job.
- With AWS Glue, you create a table definition and data definitions from the Data Catalog. A job contains your transformation logic, and triggers are used to schedule the job. We just need to tell Glue what our input source and output targets are. Glue generates the code required to transform your data from source to target.
- While configuring the ETL job in Glue, you only need to provide input source and output data targets. We also provide the IAM role, VPC ID, Subnet ID, and security groups needed to access the source and data targets.
- Glue creates an Elastic Network Interface in the given subnet using private IP addresses. Calls made to Glue libraries can proxy traffic to Glue APIs, and we can enable AWS Cloudtrail and deliver all audit logs to it for audit purposes.
Streamline your data integration process by connecting your AWS sources—like OpenSearch, S3, and Elasticsearch—directly to Redshift using Hevo’s no-code platform. Automate your data flows and ensure real-time, reliable data transfer.
Why Choose Hevo?
- Comprehensive AWS Integration: Seamlessly connect AWS OpenSearch, S3, and Elasticsearch to Redshift.
- Real-Time Data Sync: Keep your Redshift data up-to-date with continuous, automated updates.
- No-Code Simplicity: Set up and manage your data pipelines effortlessly without any technical expertise.
Setting Up AWS Glue ETL
Creating an IAM Role:
- Go to the IAM section on the AWS console
- Create a role for Glue service.
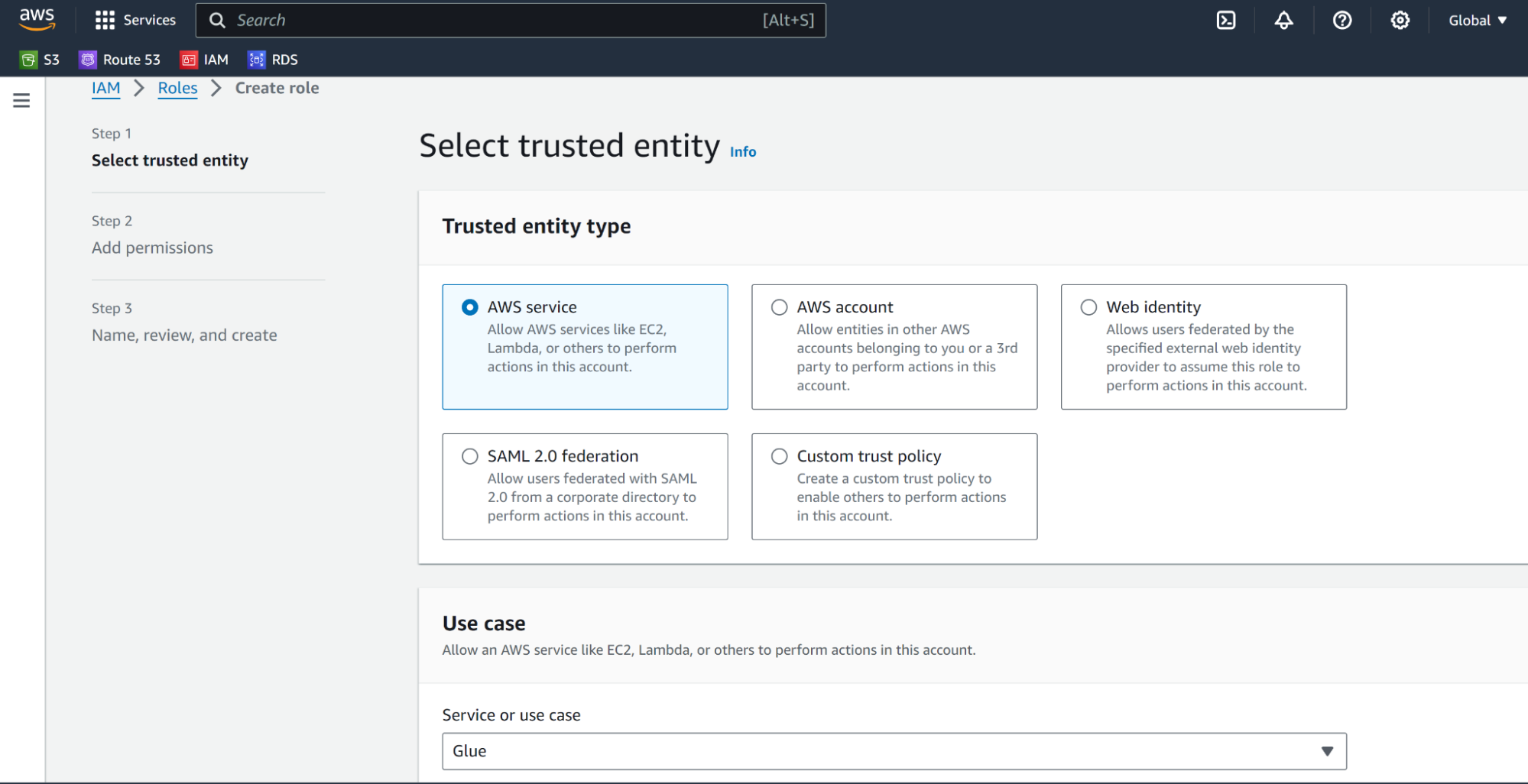
- Select AWSGlueServiceRole from the Add Permissions section.
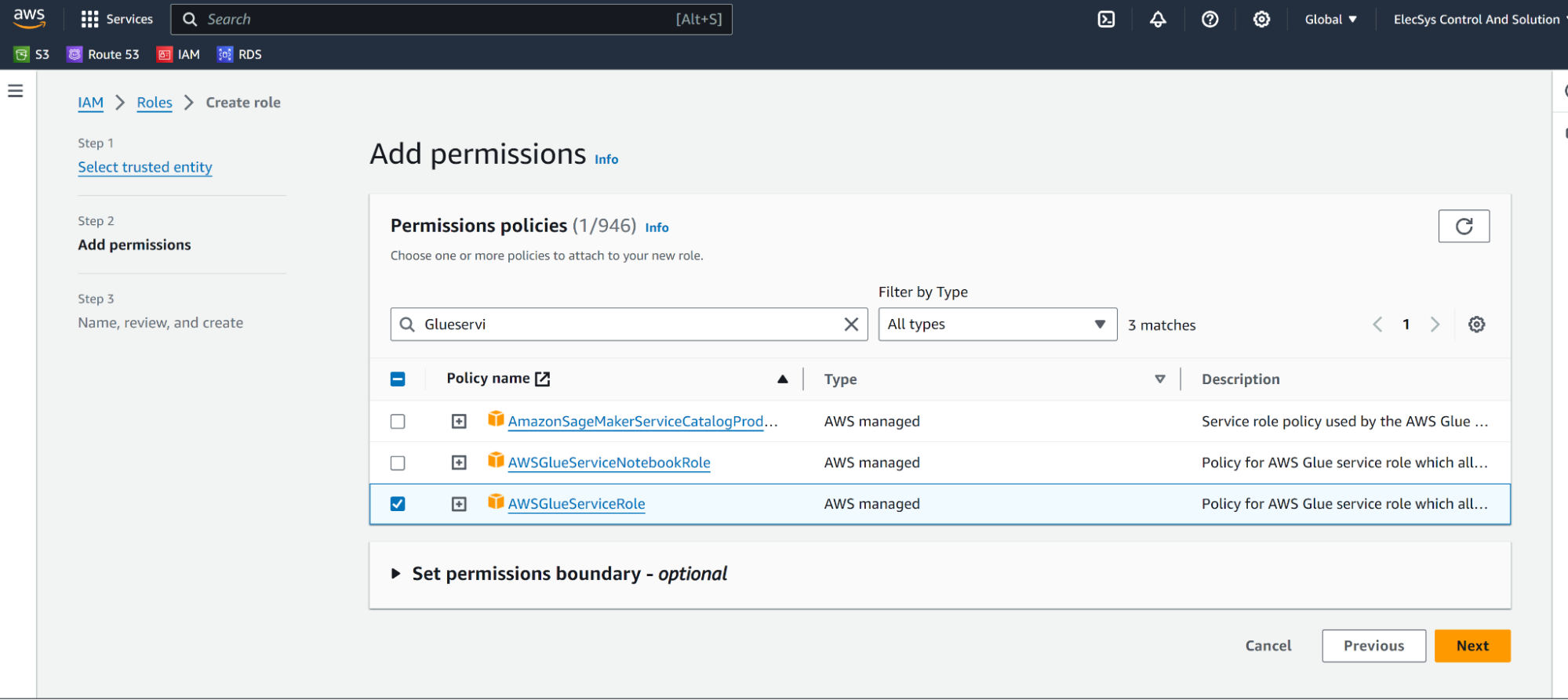
- Click on next, add tags as required, and Create a Role.
Creating and configuring Crawlers
- Click on the Glue service page and on the left side under Data Catalog click on Crawlers as shown below
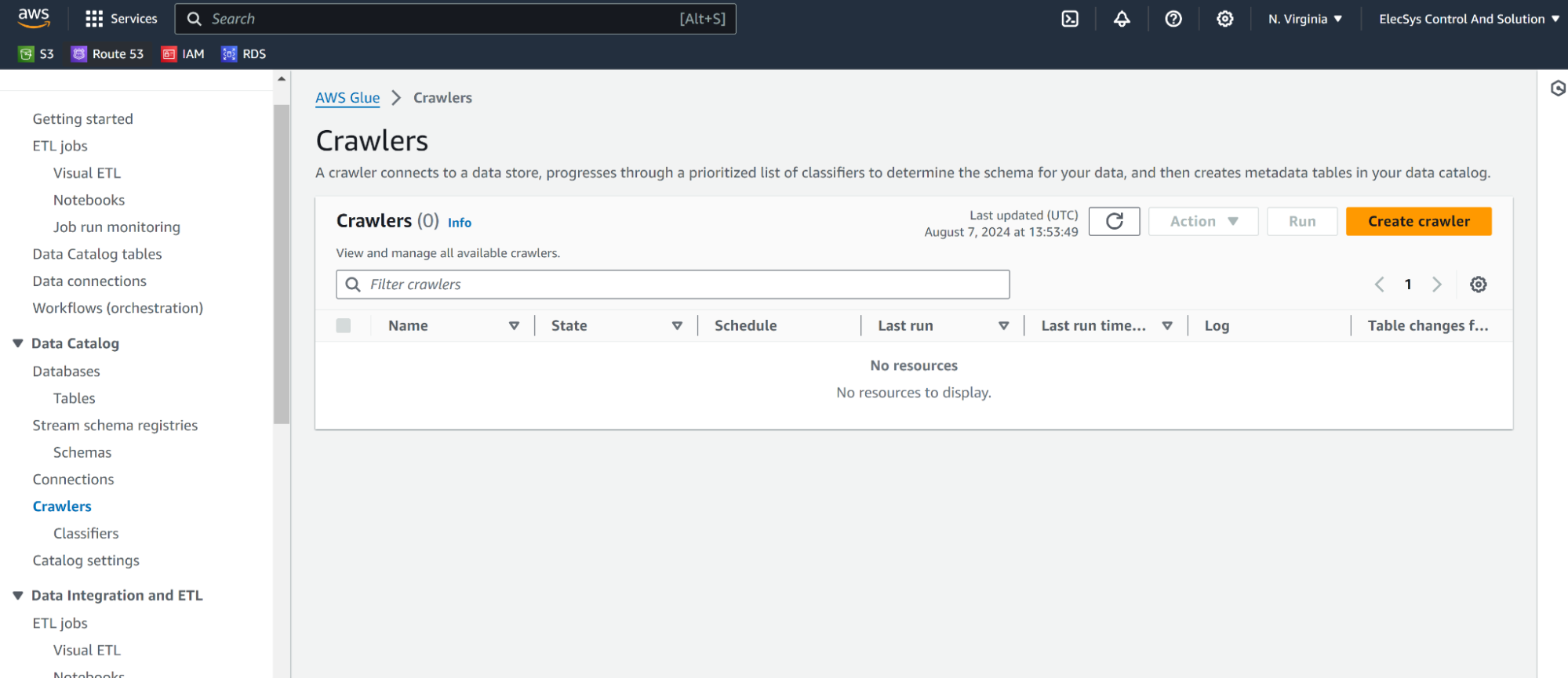
- Click on Create Crawler
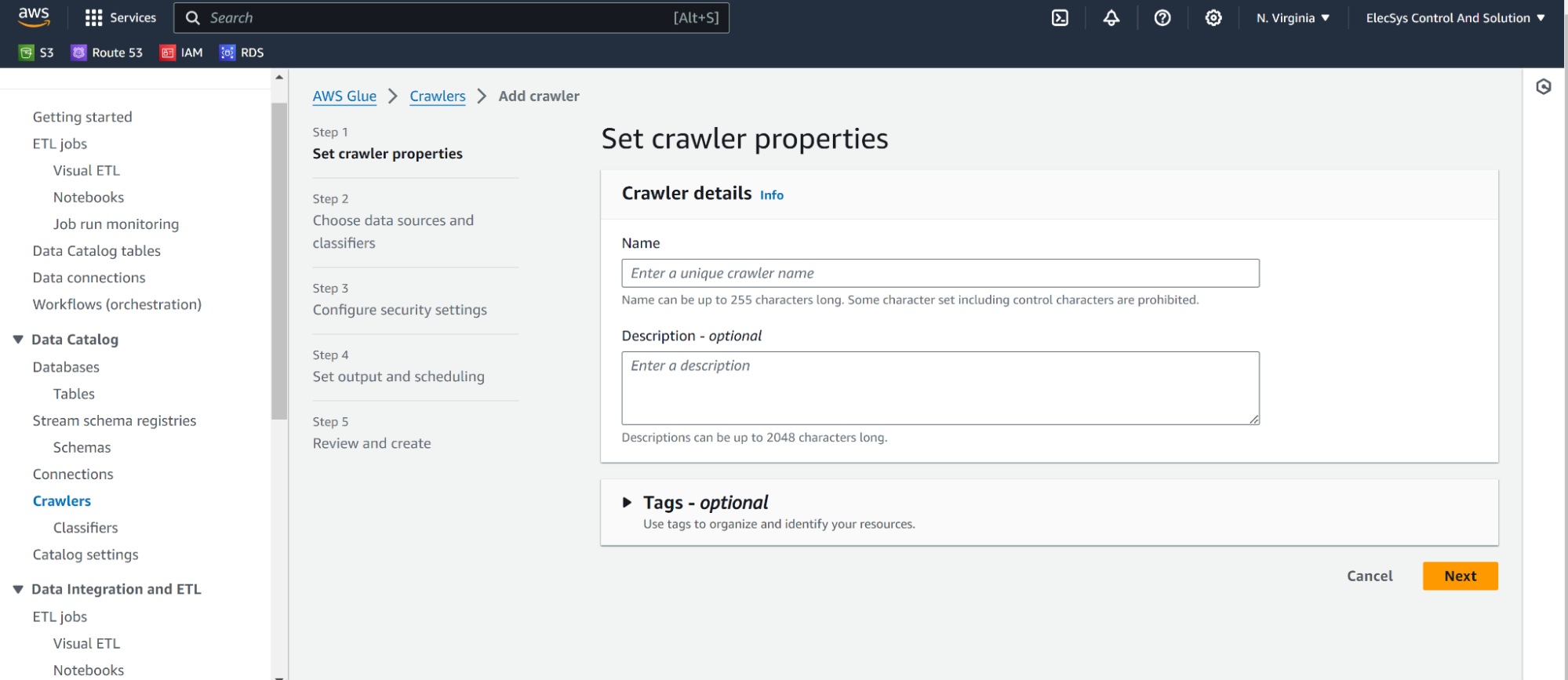
- Add Datasource as s3
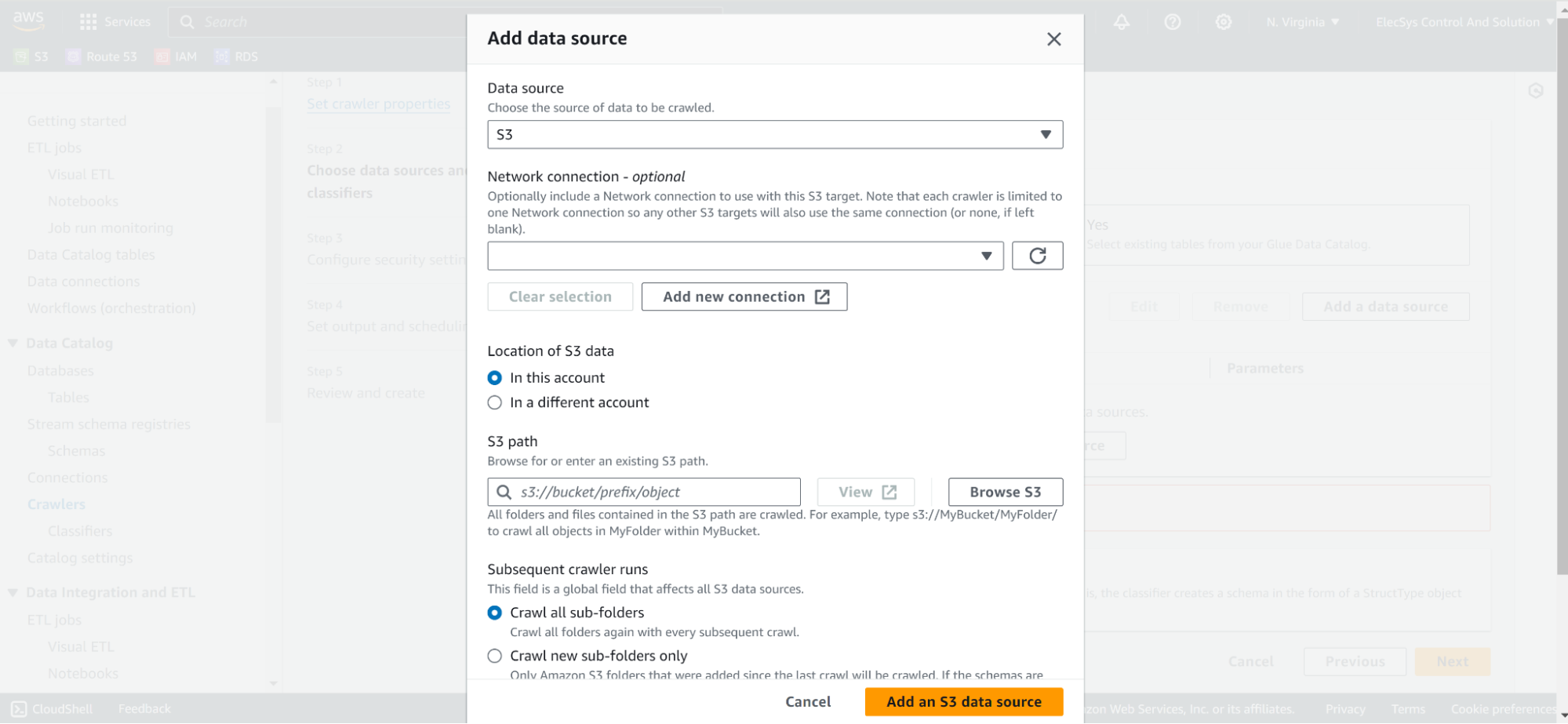
- Add Datasource as s3 and any folder having CSV file/s.
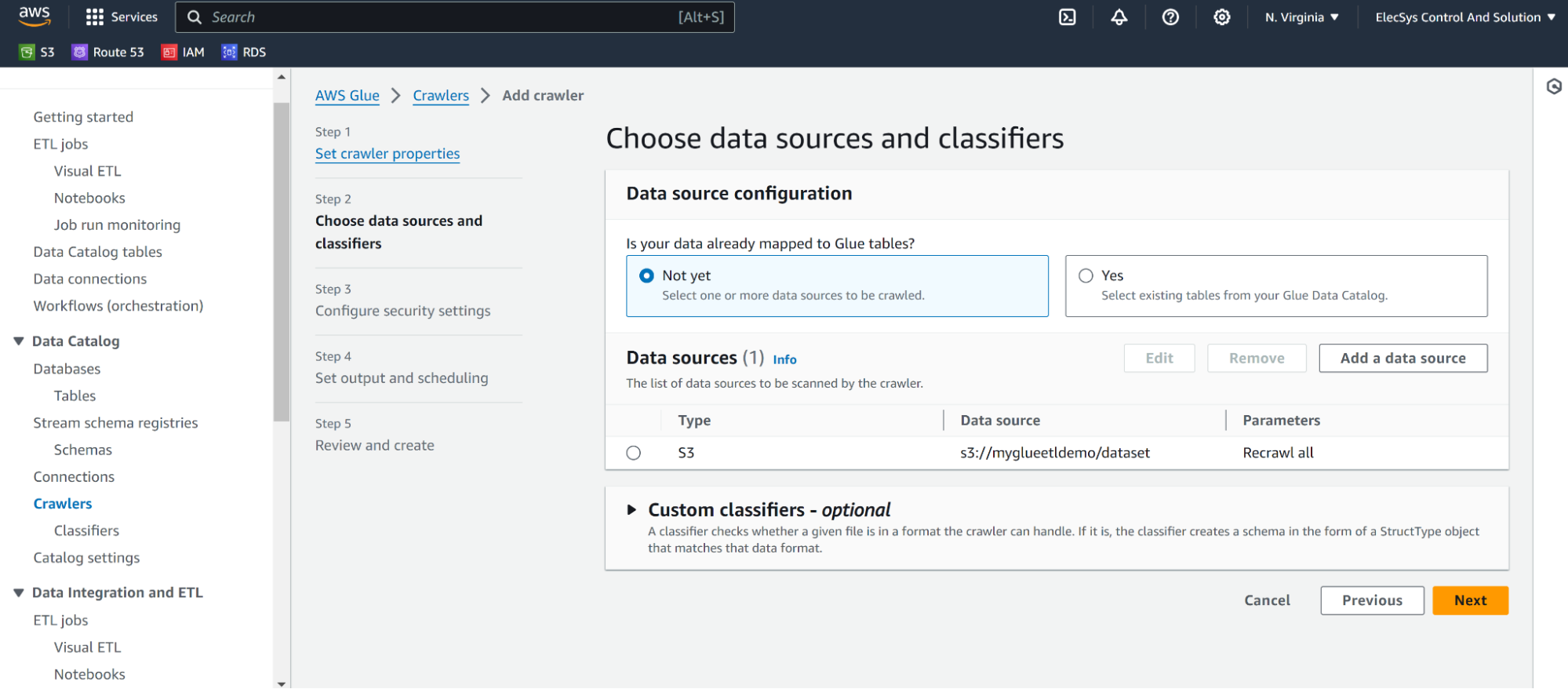
- Use CSV as a classifier.
- Select earlier created AWSGlueService Role
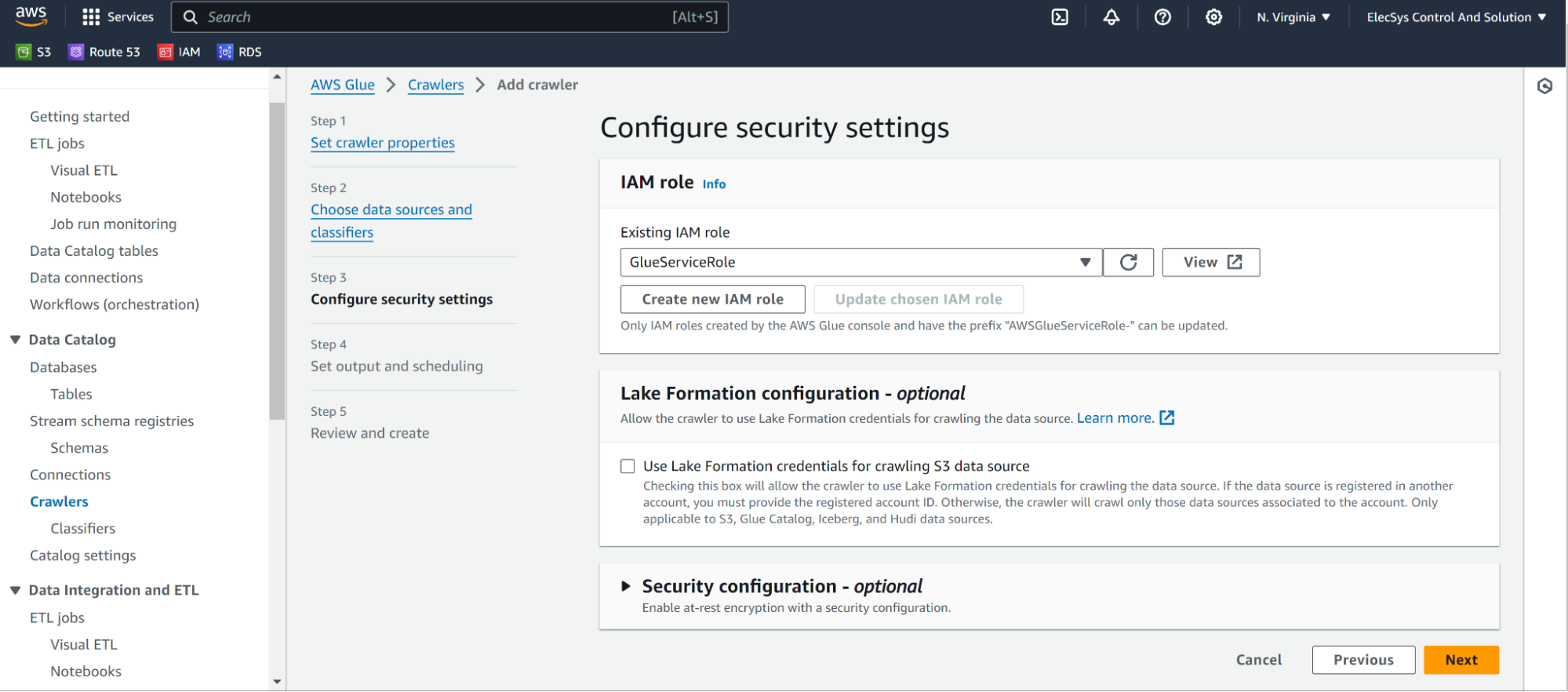
- Then select Glue database as the target database and keep crawler schedule as demand as of now.
- Click on Run Crawler.
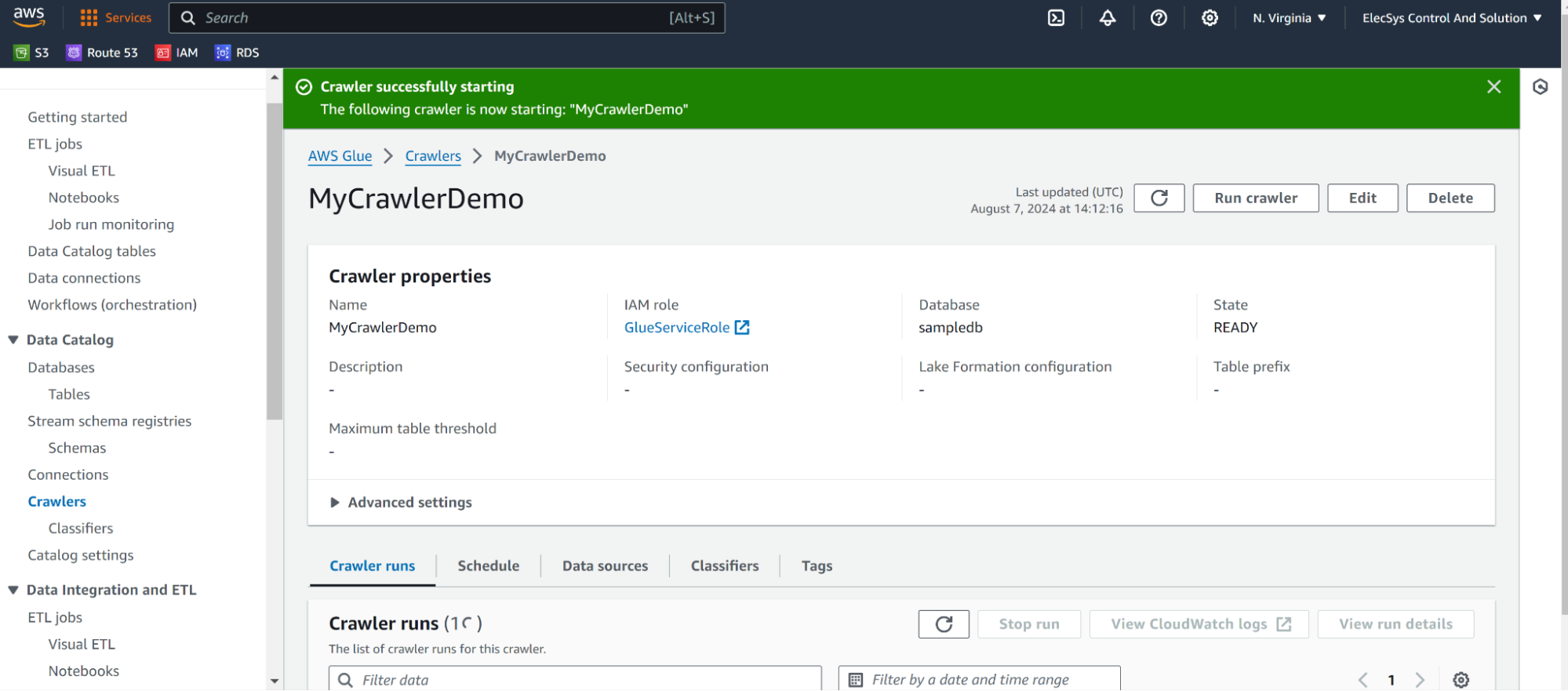
- It will create table like this using crawlers.
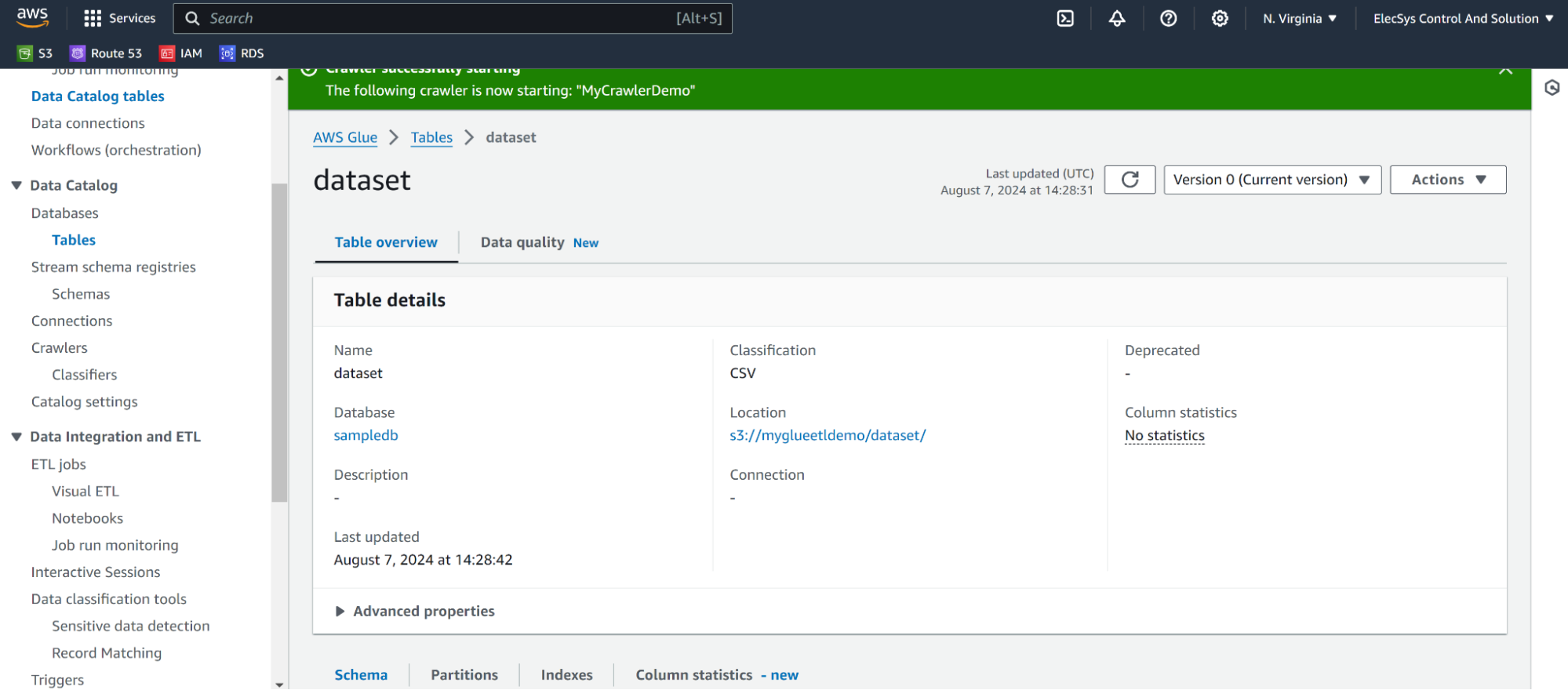
Creating ETL Jobs
- Go to AWS Glue Studio and go to Visual ETL.
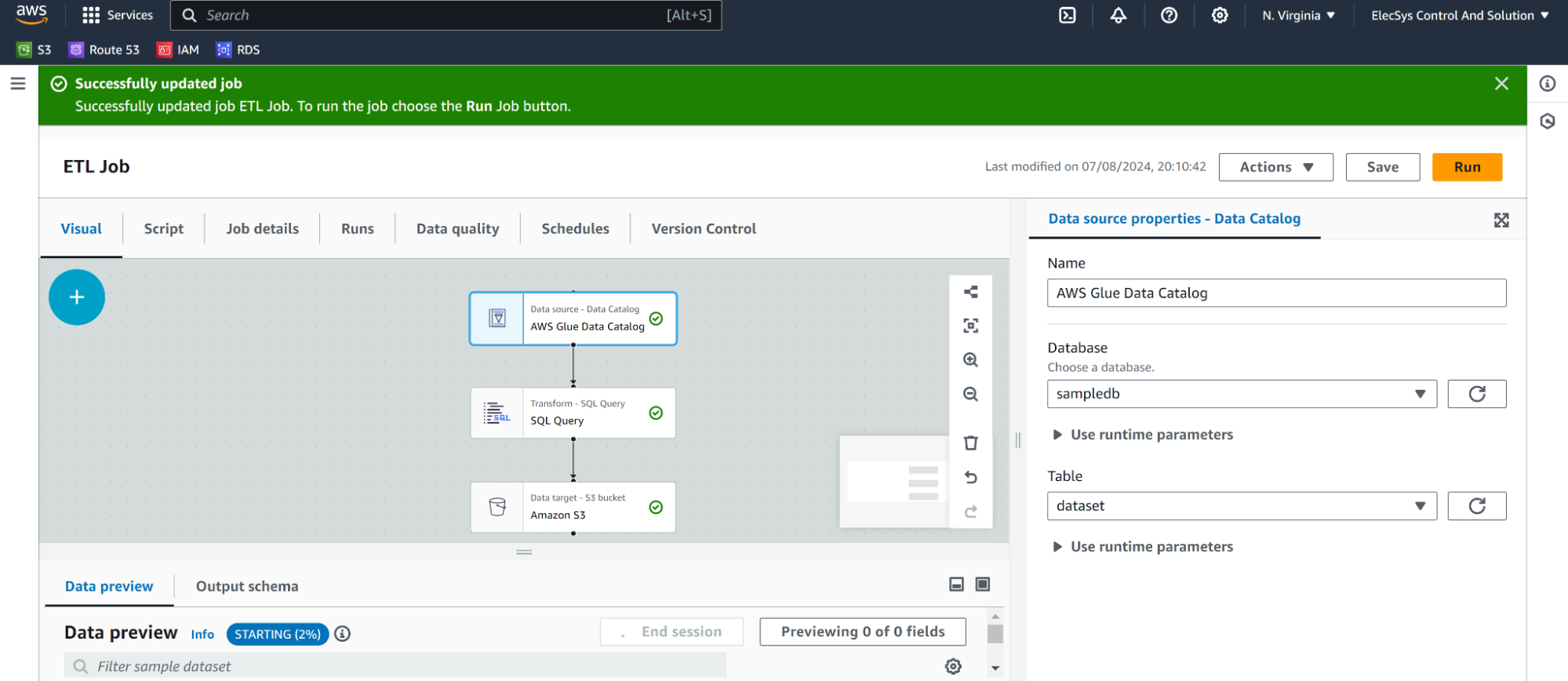
- Click on Run.
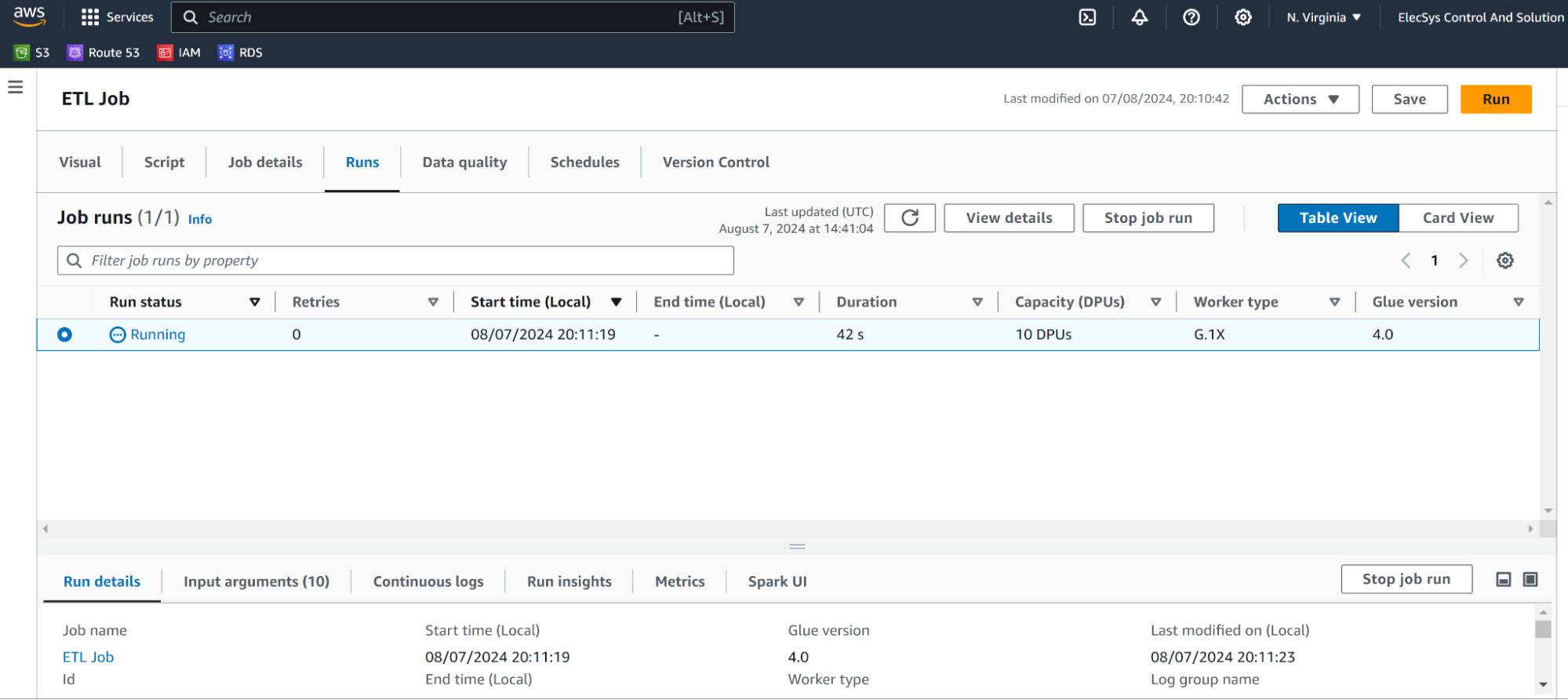
- This will create output from ETL to out s3 bucket we have mentioned.
Running and Monitoring Jobs
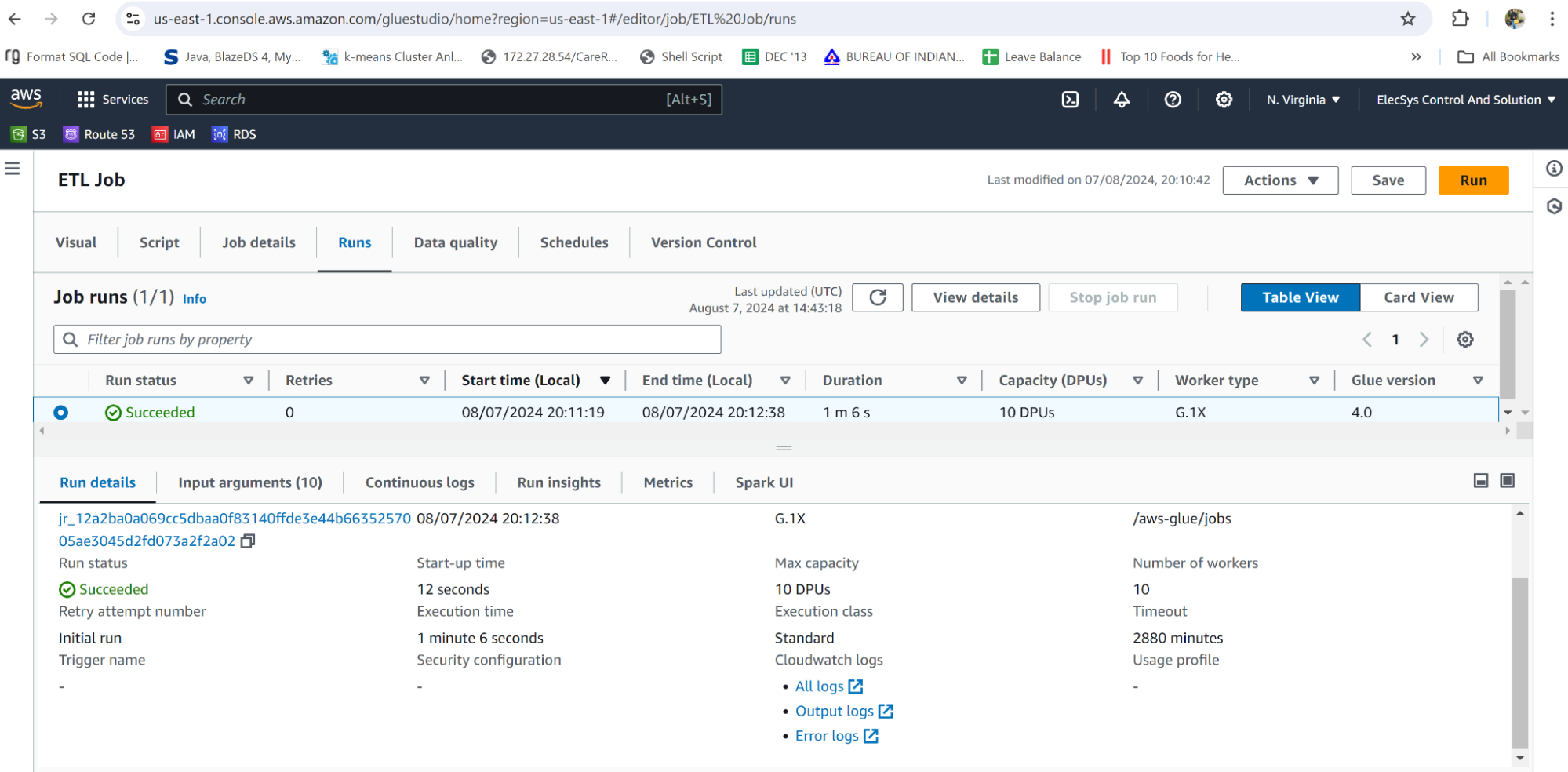
To monitor job execution please find the ETL job console as below and it will have run details and access to CloudWatch logs for each execution.
AWS Glue Components
Data Catalog
A data catalog is a centralized metadata repository that stores metadata of all the data sources, transformations, and targets.
Database
It is created to access source and target databases.
Table
Tables are created while accessing one or more tables from sources or targets.
Crawler Classifier
Crawlers are used to retrieve data from sources using built-in classifiers and they also uses metadata stored in the data catalog to crawl data.
Job
Job is the piece of code written in Apache Spark with Python or Scala which carries ETL tasks.
Trigger
Trigger is used to schedule a job.
Development Endpoint
It creates the development environment where ETL jobs are developed, tested, and debugged.
Setting Up AWS Glue ETL
- Creating an IAM Role: Step-by-step guide to creating and attaching an IAM role for ETL jobs.
- Creating and Configuring Crawlers: How to set up crawlers for metadata discovery.
- Creating ETL Jobs: Instructions for creating ETL jobs, including script development and configuration.
- Running and Monitoring Jobs: Details on how to execute and monitor ETL jobs.
Best Practices for AWS Glue ETL
Data Catalog Optimization
Always keep the AWS Glue Data Catalog well-organized with appropriate databases and tables.
Provide meaningful names to databases and tables for easy discovery and understanding.
Shema Evaluation and Data Crawling
Regularly schedule data crawler to discover the data changes in source data and update the data catalog with any schema evolutions.
Glue Job size and resource configuration
Use appropriate instance type and memory based on the scale and complexity of the job.
Try to divide complex ETL into pieces to improve performance and achieve parallelism.
Data partitioning
Partition data based on the field that is most likely used in the query filter to improve query performance. It is an important aspect of bigger data size to improve query performance and reduce job execution time.
Error Handling
Implement robust error handling in the ETL script to handle unexpected issues gracefully.
Set retries for transient errors to ensure the failed job is retried.
Data Encryption and Security
Use data encryption at rest and in transit to ensure data compliance and security.
Use IAM (Identity and Access Management) to control access to Glue resources.
Job Monitoring and Logging
Enable Cloudwatch alarms and logging for Glue jobs to monitor resource utilization, performance, and job status.
Code Reusability
Keep reusable code in a separate module and import and reuse it whenever required.
Optimized Data Processing
Whenever possible try to use Glue’s built-in functions rather than developing custom functions. Leverage spark engine optimization such as predicate pushdown to reduce data scene and improve the job’s performance.
Cleanup Resources
Clean up resources such as non-used development scripts or temporary files to reduce cloud costs.

Benefits and Limitations of AWS Glue ETL
Advantages
- AWS Glue is easy to use.
- It is a cost-effective cloud service for ETL processing. As you only have to pay for the resources used for the execution of the job.
- It is fast as code is written in Scala or Python.
Challenges and Limitations:
- It is an AWS service hence it runs with an AWS console with no provision of using the same with other technologies.
- There is a limitation on real-time data processing due to a lack of incremental sync with data sources.
- Although AWS Glue is a serverless service, it requires certain team members to develop a skill set.
- It only supports structured databases.
Future of AWS Glue ETL
Advanced data transformation which can clean, enrich, and analyze your data. It should have support for integrating Machine learning models. There is room for improvement where crucial real-time streaming ETLs can be run. As this is serverless, it should give precise cost estimation for your data pipeline to have more control over it.
Learn More:
Conclusion
Using AWS Glue for building an ETL pipeline is easier and quicker. We just have to glue pieces together. It enables users to just focus on deriving insights from ETL rather than focusing on managing infrastructure. Its serverless nature, ease of use, and powerful features make it a valuable asset for any organization looking to build and maintain efficient ETL pipelines.
FAQ on AWS Glue ETL
What is ETL in AWS Glue?
ETL in AWS Glue refers to the process of Extracting, Transforming, and Loading data using AWS Glue, a fully managed ETL service provided by Amazon Web Services.
Which ETL tool is used in AWS?
The primary ETL tool used in AWS is AWS Glue. AWS Glue provides a serverless environment where users can build ETL workflows without having to manage the underlying infrastructure. It includes a data catalog to manage metadata, automated code generation for ETL scripts, and a job scheduling service.
What is AWS Glue?
AWS Glue is a fully managed ETL service that simplifies the process of preparing and loading data for analytics. It is designed to automatically discover and profile data, generate ETL code, and orchestrate complex data flows.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




