



Azure Data Factory is one of the most popular Cloud-based Data Integration Services that allows you to create, manage, and schedule Data Pipelines or Workflows. It has a rich set of features and functionalities like Two-way Traceability, Code-free Data Synchronization, CI/CD (Continuous Integration and Continuous Delivery), and Pipeline Orchestration.
One such advanced feature of Azure Data Factory is Azure Data Factory Triggers, which allows you to initiate or revoke the Data Pipelines based on a given time interval. With Azure Data Factory Triggers, you can easily schedule and automate Data Pipelines and track the success and failure rates of active Workflows or Pipelines.
In this article, you will learn about Azure Data Factory, Triggers in Azure Data Factory, their types of triggers in ADF, and steps to create and configure Schedule Triggers to execute Data Pipelines.
Table of Contents
What is Azure Data Factory?
Azure Data Factory, or ADF, is Microsoft’s cloud-based data integration service. It is designed to facilitate the creation, scheduling, and orchestration of data pipelines in the cloud. ADF is a fully managed service where Microsoft provides infrastructural involvement while you focus on your data workflows.
Key Features
- More than 90 built-in connectors for ingesting all your on-premises and software-as-a-service (SaaS) data to orchestrate and monitor at scale.
- Easy rehosting of SQL Server Integration Services to build ETL and ELT pipelines code-free with built-in Git and support for continuous integration and delivery (CI/CD).
- Pay-as-you-go, fully managed serverless cloud service that scales on demand for a cost-effective solution.
Read more about Azure Data Factory vs Databricks in the following guide: Azure Data Factory vs Databricks: 4 Critical Key Differences.
Say goodbye to complex data transfers! With Hevo, you can migrate data between platforms effortlessly, ensuring a smooth and seamless transition. Our no-code platform automates the entire process, offering real-time data syncing and 150+ pre-built integrations. With Hevo:
- Transform your data for analysis with features like drag and drop and custom Python scripts.
- 150+ connectors, including 60+ free sources.
- Eliminate the need for manual schema mapping with the auto-mapping feature.
Try Hevo and discover how companies like EdApp have chosen Hevo over tools like Stitch to “build faster and more granular in-app reporting for their customers.”
Get Started with Hevo for FreeAzure Data Factory Trigger Types
Azure Data Factory Triggers come in three types: Schedule Trigger, Tumbling Window Trigger, and Event-based Trigger.
1. Schedule Trigger
This Azure Data Factory Trigger is a popular trigger that can run a Data Pipeline according to a predetermined schedule. It provides extra flexibility by allowing for different scheduling intervals like minute(s), hour(s), day(s), week(s), or month(s).
You can set the start and end dates for the Schedule Trigger to be active so that it only runs a Pipeline based on the given time period. Furthermore, you can also use the Schedule Trigger to run on future calendar days and times, such as the 30th of each month, the first and third Monday of each month, and more.
The Schedule Azure Data Factory Triggers are built with a “many to many” relationship in mind, which implies that one Schedule Trigger can run several Data Pipelines and a single Data Pipeline can be run by multiple Schedule Triggers.
2. Tumbling Window Trigger
The Tumbling Window Azure Data Factory Trigger executes Data Pipelines at a specified time slice or pre-determined periodic time interval. It is significantly more advantageous than Schedule Triggers when working with historical data to copy or migrate data.
Consider the scenario in which you need to replicate data from a Database into a Data Lake regularly, and you want to keep it in separate files or folders for every hour or day.
To implement this use case, you have to set a Tumbling Window Azure Data Factory Trigger for every 1 hour or every 24 hours. The Tumbling Window Trigger sends the start and end times for each time window to the Database, returning all data between those periods. Finally, the data for each hour or day can be saved in its own file or folder.
3. Event-based Trigger
The Event-based Azure Data Factory Trigger runs Data Pipelines in response to blob-related events, such as generating or deleting a blob file present in Azure Blob Storage. With the Event-based Triggers, you can schedule the Data Pipelines to execute in response to an event from Azure Blob Storage.
In addition, event-based triggers are compatible not only with blob but also with ADLs. Like Schedule Triggers, Event Triggers can also work on many-to-many relationships, in which a single Event Trigger can run several Pipelines and a single Pipeline can be run by multiple Event Triggers.
| Aspect | Scheduled Trigger | Tumbling Window Trigger | Storage Event Trigger | Custom Event Trigger |
| Definition | A trigger that runs at a pre-defined time interval or schedule. | A trigger that fires at regular intervals, with no overlaps or gaps. | A trigger that responds to events in storage (e.g., file creation or deletion). | A trigger that responds to custom events published to an event grid. |
| Use Case | Regularly scheduled tasks, such as backups or data processing. | Time-based processing that must occur at fixed intervals (e.g., aggregations). | Triggering actions based on changes in storage, such as new files or updates. | Responding to specific custom events like user actions or application events. |
| Time-based | Yes, based on a set time or frequency (e.g., daily, hourly). | Yes, but with non-overlapping windows (e.g., every hour, every day). | No direct time dependency; event-based based on storage actions. | No time dependency; event-based based on custom event publication. |
| Overlap Allowed | Yes, runs as per the defined schedule regardless of the previous run’s state. | No, intervals are fixed with no overlap. Each window must be completed before the next starts. | Not applicable; fires as storage events occur. | Not applicable; fires as custom events are received. |
| Dependencies | None runs independently of data or events. | Dependent on the completion of the current time window. | Dependent on storage events (e.g., file creation or deletion). | Dependent on custom events being published to an event grid. |
| Trigger Flexibility | Very flexible and can be scheduled at any desired interval or time. | Limited to fixed intervals with no overlap or delay. | Triggered only by file-based events in the storage location. | Triggered by any custom event based on defined event types and subscriptions. |
| Examples | – Run a backup every night at 2 AM. – Send daily sales report. | – Process data every hour. – Aggregate log entries every 10 minutes. | – Trigger data pipeline when a file is uploaded. – Start a process on file deletion. | – Trigger an event when a user places an order. – Respond to an IoT device message. |
Want to learn about ADF activities? Explore our ADF ETL tutorial for a detailed guide.
How to Create Triggers with UI?
Step 1: To manually trigger a pipeline or configure a new trigger, select Add trigger at the top of the pipeline editor.
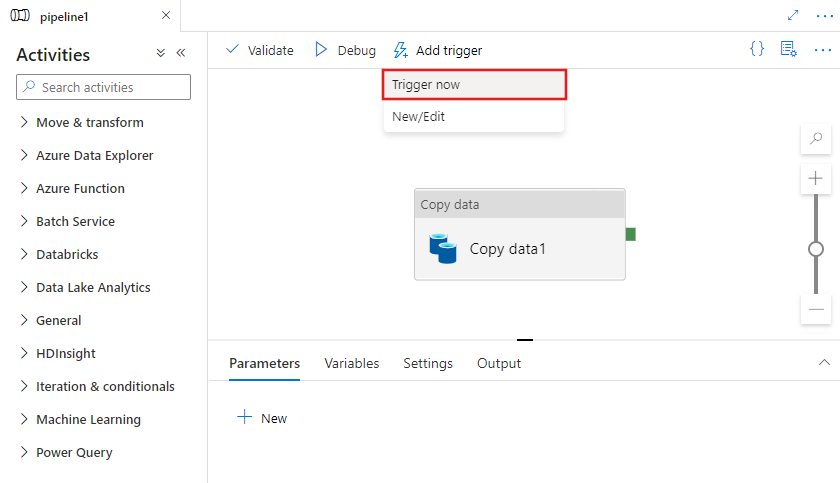
Step 2: If you choose to manually trigger the pipeline, it will execute immediately. Otherwise, if you choose New/Edit, you will be prompted with the add triggers window to either choose an existing trigger to edit, or create a new trigger.
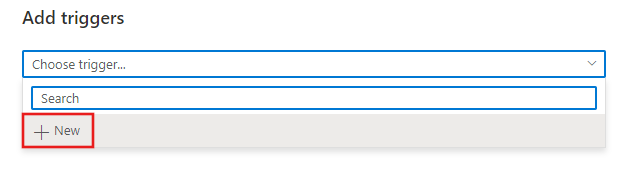
Step 3: Select your trigger type in the configuration window.
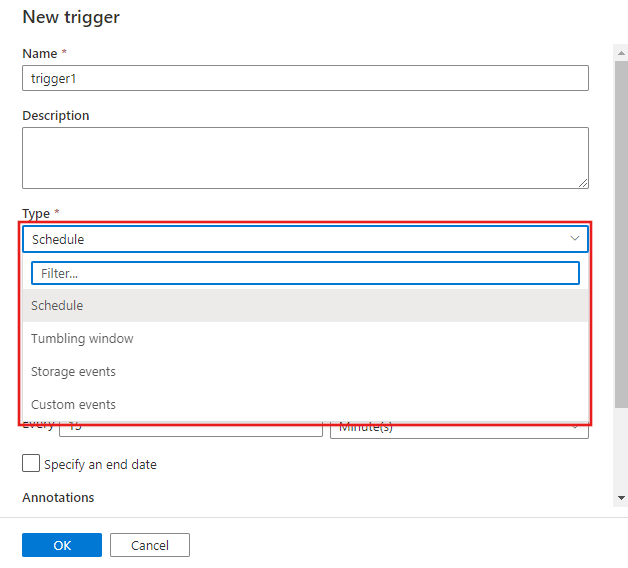
And you are done! Now, you can execute this trigger as mentioned in step 1.
Recommended
- Fivetran vs Azure Data Factory
- Airflow vs Azure Data Factory
- Azure Synapse vs Data Factory
- Guide to Azure Data Factory Snowflake Integration
- AWS Glue and Azure Data Factory
- Azure Data Factory alternatives
- Airbyte vs Azure Data Factory
- Apache NiFi vs Azure Data Factory

Conclusion
In this article, you learned about Azure Data Factory, Azure Data Factory Triggers, their types, and steps to create and configure Schedule Triggers to execute Data Pipelines. This article mainly focused on configuring the Triggers to run pre-built Data Pipelines using Azure Data Factory UI. However, you can also use Azure PowerShell, Azure CLI, Azure Resource Manager Template, .NET SDK, and Python SDK to create and configure Schedule Triggers.
To learn more about Azure Data Factory, check out our blogs and to experience seamless data migration, sign up for Hevo’s 14-day free trial today!
Frequently Asked Questions
1. What are the triggers in Azure Data Factory?
Used to initiate pipeline execution; types include scheduled triggers, event-based triggers, and tumbling window triggers.
2. How do I schedule a trigger dependency in Azure Data Factory?
Create multiple triggers and use trigger conditions to set dependencies, allowing one trigger to start after another completes.
3. How to parameterize trigger in Azure Data Factory?
Define parameters in the trigger settings to pass dynamic values to the pipeline at runtime. Reference these parameters in pipeline activities.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




