




Organizations use Azure Synapse Analytics and Azure Data Factory to streamline data handling processes. Both tools offer numerous features to connect, transform, and centralize data quickly. However, since both platforms are similar in a few aspects, it becomes difficult to pick between the two solutions.
In this article, we will explore the similarities and differences between Azure Synapse vs Data Factory. This will help you understand the solutions’ capabilities and identify the best solution for your business requirements.
Looking for the best ETL tools to connect your data sources? Rest assured, Hevo’s no-code platform helps streamline your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Utilize drag-and-drop and custom Python script features to transform your data.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
Try Hevo and discover why 2000+ customers have chosen Hevo over tools like AWS DMS to upgrade to a modern data stack.
Get Started with Hevo for FreeTable of Contents
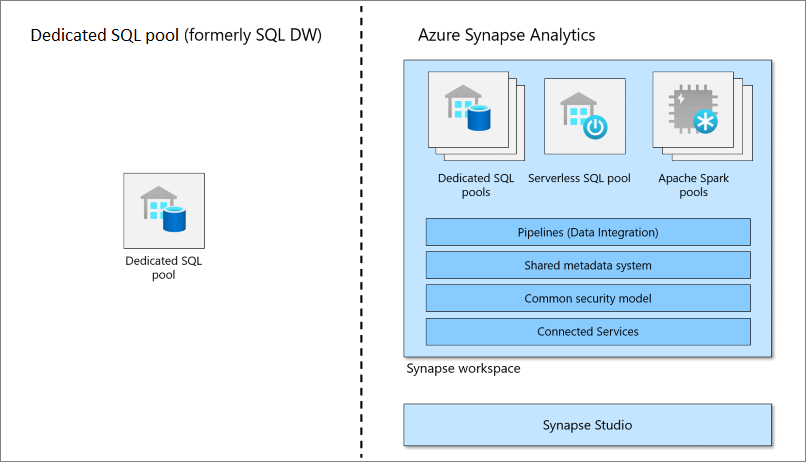
Azure Synapse Overview

Azure Synapse is a unified analytics service that includes capabilities for data integration, data warehousing, and data analytics. For integration, Azure Synapse supports over 95 native connectors that allow you to gather data from multiple sources. After the data is collected, you can transform the data and store it in a data warehouse. Eventually, you can leverage Azure Synapse for analysis and visualization.
Synapse’s numerous features to manage end-to-end big data workflow have quickly made it popular among analytics professionals. Its ability to handle unstructured data stored in a data lake makes it even more powerful. Synapse also supports analyst-friendly languages like T-SQL, Python, Scala, Spark SQL, and .Net.

Building Pipelines in Synapse
- Sign in to the Azure portal.
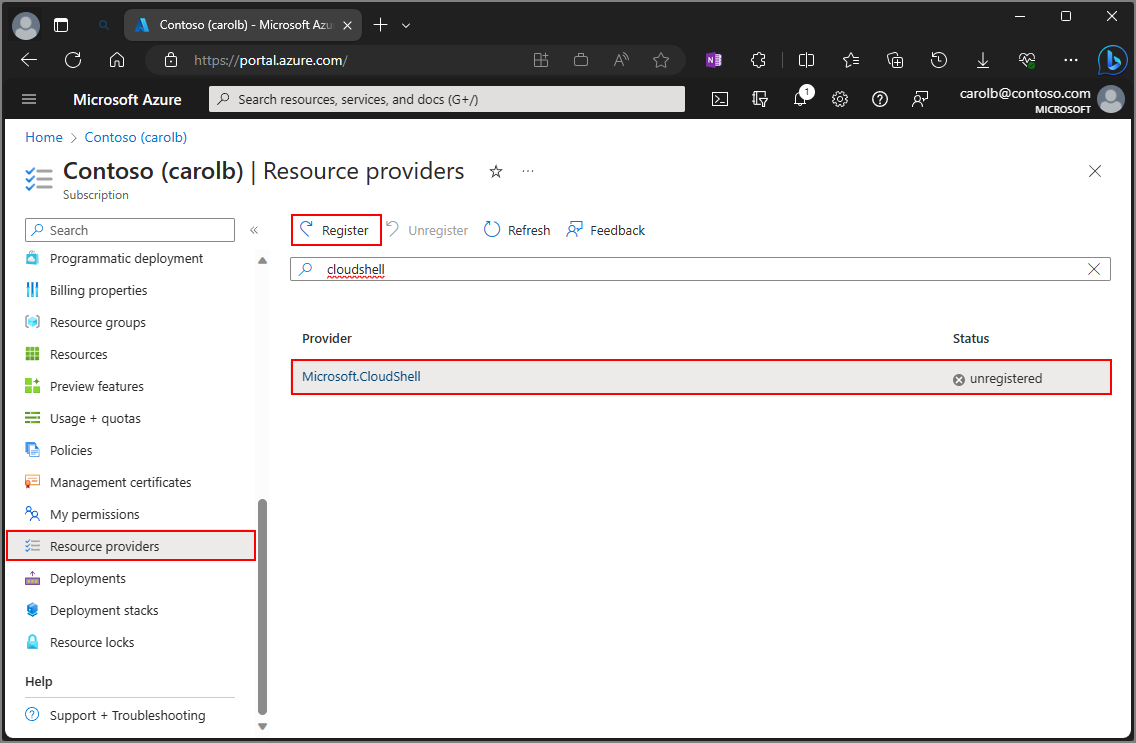
2. Click on the icon [>_] to create Cloud Shell to get a command line interface environment.

- In the command line interface (PowerShell), provide the following command to clone a repository from GitHub:
rm -r dp-000 -f<code>git clone https://github.com/MicrosoftLearning/mslearn-synapse dp-000
- Navigate to the desired folder (../16) and run setup.ps1 script to set up the project.
- When prompted, provide the password for your Azure Synapse SQL pool.
- Now, open the dp000-xxxxxxx resource group created after running the setup.ps1 script.
- Open the resource group, and select Open to start Synapse Studio.
- Create a dedicated SQL pool (an enterprise data warehouse). Go to Manage > SQL pools. Now, select the sqlxxxxxxx dedicated SQL pool and press the run icon.
9. You can now start building pipelines. Head to Home > Ingest > Copy Data. When prompted, provide the necessary details to set up the tool.
10. You can build a transformation pipeline by navigating to Home > Integrate.
Azure Data Factory Overview

Azure Data Factory is a fully managed, serverless data integration service. It has more than 90 built-in connectors to collect data from different sources. You can also use Azure Data Factory to transform data without writing a single line of code. Since it is a no-code platform, it enables non-technical professionals to gather and transform data efficiently.
Azure Data Factory also supports Git and CI/CD to incrementally build ETL/ELT pipelines. With Azure Data Factory, you can even monitor your pipelines without its no-code capabilities.
Want to learn about ADF activities? Explore our ADF ETL tutorial for a detailed guide.
Similarities – Azure Data Factory vs Synapse
Azure Synapse and Azure Data Factory have similarities in data integration and transformation practices.
- Both services have built-in connectors that allow you to move data between different databases with UI-based workflows.
- Both platforms offer similar features for ETL or ELT. Both platforms also allow similar connectors to pull data while building data pipelines. You can also manage how the solutions scale up or down based on the size of the data to ensure better performance flexibility.
- Both solutions offer linked services to extend data engineers’ capabilities. These services can be used to connect with other Azure services and handle data based on downstream requirements.
- As a result, if you are familiar with Azure Data Factory, you can swiftly move to Azure Synapse, as both have similar data integration and transformation features.
Major Differences – Azure Synapse vs Data Factory
| Category | Azure Synapse | Azure Data Factory |
| Data Transformation | Data pipelines are built with no-code features and Python programming | Data pipelines are primarily built using no-code features |
| Machine Learning | Build machine learning models with or without code | Mainly used for building data pipelines only |
| Security and Access Control | Has a wide range of access control for Azure roles, Synapse roles, SQL roles, and Git permissions | Generally, users are added with contribution role |
| Pricing | Pricing is categorized based on the resources you use for data warehousing, data exploration, and more. | Pricing is dependent on the status and usage of data pipelines. |
| Pipeline Activities | It provides support for Power Query Activity and also supports global parameters. | It does not support Power Query Activity and also does not provide support for global parameters. |
| Monitoring | Does not provide any monitoring support. | Monitoring of Spark Jobs for Data Flow by leveraging the Synapse Spark pools |
| Integration Runtime | Support for Cross-region Integration Runtime (Data Flows) and supports Integration Runtime Sharing (can be shared across different data factories) | Does not provide any Integration Runtime support. |
Discover the top Azure Data Factory alternatives in our latest blog.
1. Data Transformation Capabilities
Azure Synapse
When discussing Data Factory vs Synapse, it’s important to start with data transformation. Data transformation can be carried out through the no-code capabilities of both platforms. But, with Azure Synapse, you can use programming languages like Python to write custom code for transformation. Based on the business requirements, data transformation can get complex over time. As the complexities increase, you will require more flexibility to modify and optimize data pipelines.
Azure Data Factory
However, with Azure Data Factory, you must primarily rely on no-code features. As a result, Azure Synapse becomes a go-to platform for your strenuous data transformation requirements. As Azure Synapse supports numerous programming languages, it empowers a broader range of professionals to transform data.
2. Support for Machine Learning
Azure Synapse
Azure Data Factory only helps you with data integration and data transformation. On the other hand, Azure Synapse allows you to perform analysis with numerous programming languages. You can use Python or Spark to leverage its broader ecosystem of machine learning libraries to build robust models for generating insights. Since Azure Synapse also supports unstructured data, leveraging machine learning becomes crucial to gain in-depth insights.
Azure Data Factory
Azure Synapse also supports AutoML workflows. You can quickly train machine learning models without writing code. To build no-code AutoML models, you only have to select the model type. You can choose between classification, regression, and time series to get a set of machine-learning models. You can choose the best model for your use case based on the business requirements.
3. Security and Access Control
Azure Synapse
Microsoft ensures better security and access control over your resources on the cloud. With Azure Synapse, you can control access to data, code, and execution based on roles. When considering Azure Synapse vs ADF, Synapse offers more comprehensive control over data access and processing workflows. You can even control version control and continuous integration capabilities. To ensure you manage the access to different users effectively, create security groups and apply permissions.
Azure Data Factory
Azure Data Factory also allows you to manage access control of resources. Generally, you add a user with the contributor role in the Azure Data Factory. A contributor has permission to create, edit, and delete resources like datasets, pipelines, triggers, and more. However, you can customize roles to serve your business requirements. For instance, you can allow users to access only a few data pipelines or let users monitor the pipelines.
4. Pricing
Azure Synapse
Pricing of Azure Synapse Analytics is complex since the cost depends on the types of services you use. For instance, the cost would be calculated based on storage, I/O requests, and compute units. Generally, the pricing is categorized as follows: Data Exploration and Data Warehousing, Apache Spark Pool, and Data Integration. Since the workflow in each of these categories is different, pricing varies based on workflow. You can use the Azure pricing tool for Synapse to understand its cost.
Azure Data Factory
Azure Data Factory has two versions: V1 and V2. The cost of V1 depends on the status of pipelines, the frequency of activities, and other factors. The cost of V2 considers data flow, pipeline orchestration, and the number of operations.
Both services’ cost depends on your business use cases. As a result, Azure recommends you request a pricing quote for more clarity and a custom deal.

Learn More:
- Azure Synapse vs Databricks
- Azure Synapse vs Snowflake
- Azure Data Factory vs Databricks
- Airflow vs Azure Data Factory
Key Takeaways
- Azure Synapse Analytics is widely used among professionals looking for an end-to-end solution for analytics. Synapse allows you to collect, transform, and analyze data from just one platform. However, Azure Data Factory is only suitable for data engineers who want to streamline data collection processes with in-built processes.
- If you only want to connect and transform data without writing code, you should embrace Azure Data Factory. However, it doesn’t allow you to customize your data pipelines beyond its no-code capabilities. If you want more flexibility while working with data, you must embrace Azure Synapse Analytics.
- If you want to integrate data into your desired Database/destination, Hevo Data is the right choice! It will help simplify the ETL and management process of both the data sources and the data destinations.
Hevo is a cloud-based, completely managed No Code Pipeline ETL tool offering built-in Azure Synapse Analytics support. It can move data from 150+ Data Sources, including 60+ Free Sources, to most of the common Data Destinations used in the enterprise space.
Want to take Hevo for a spin? Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. What is the alternative of Azure Synapse?
Amazon Redshift, Google BigQuery, Snowflake, IBM Db2 Warehouse, Teradata, and Oracle Autonomous Data Warehouse.
2. Is Azure Synapse an ETL tool?
Azure Synapse Analytics is not solely an ETL tool but is a comprehensive analytics service that integrates big data and data warehousing.
3. Is Azure Synapse a data warehouse?
Yes, Azure Synapse Analytics functions as a data warehouse.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



