

Google BigQuery is a cloud-based data warehouse solution provided by Google. It offers users a flexible platform to store and analyze their data. It scales automatically to meet changing storage and compute needs, allowing users to access their data from various locations. With a focus on security, BigQuery ensures data protection through multiple mechanisms. Among its many features, BigQuery provides users with a range of functions to generate summaries, including the AVG function for calculating the average value of a specific field.
BigQuery’s table structure, organized by rows and columns, makes it easy for users to extract insights from large datasets. By invoking functions like AVG, users can quickly summarize data, which is especially useful when dealing with massive volumes. This capability helps users better understand and analyze their data efficiently.
Table of Contents
Prerequisites
- A Google Account.
What is Google BigQuery?
Google BigQuery is a highly scalable, Serverless Data Warehouse with a built-in Query Engine. It was developed by Google, hence, it uses the processing power of Google’s Infrastructure. The Query Engine can run SQL Queries on terabytes of data within seconds, and petabytes within minutes. Google BigQuery gives you this performance without the need to maintain the infrastructure or rebuild or create indexes.
Google BigQuery’s Speed and Scalability make it suitable for use in processing huge datasets. It also comes with built-in Machine Learning capabilities that can help you to understand your data better.
With Google BigQuery, you can achieve the following:
- Democratize Insights with a scalable and secure platform that comes with machine learning features.
- Improve business decision-making from data using a Multi-Cloud and Flexible Analytics solution.
- Adapt to data of any size, from bytes to petabytes, with no operational overhead.
- Run large-scale analytics.
Want to Simplify BigQuery ETL with Hevo?
Hevo makes BigQuery ETL effortless with its no-code data pipelines. Automate data ingestion, transformation, and loading seamlessly while enjoying real-time updates and robust data integrity. Transform your ETL process and focus on insights, not complexities.
Here’s why you should choose Hevo:
- Real-time data transfer
- Plug-and-play transformations
- 24/5 Live Support
Google BigQuery also allows you to create dashboards and reports that you can use to analyze your data and gain meaningful insights from it. It is also a powerful tool for real-time data analytics.
What is Google BigQuery AVG Function?
The Google BigQuery AVG Function returns the average or the mean of all the non-null values provided in the input, or NaN if the input has a NaN. The function supports numeric types such as INT64. If the input has Floating-point Values, the output from the function will be non-deterministic, meaning that you may get different results for the same input values when you run the function repeatedly.
Syntax: How to use the Google Bigquery AVG Function?
The Google BigQuery AVG Function takes the following syntax:
AVG
[DISTINCT]
expression)
[OVER (...)]The function takes two optional clauses in the following order:
- OVER: It helps you to specify a window. It is incompatible with all other clauses of the AVG function.
- DISTINCT: When this clause is used in the Google BigQuery AVG Function, every distinct value in the expression will be aggregated only once.
Example Queries for Google BigQuery AVG Function
- Using AS Clause with AVG Function
- Using the DISTINCT Clause with AVG Function
- Using the OVER Clause with AVG Function
1) Using AS Clause with AVG Function
SELECT AVG(x) as Average
FROM UNNEST([2, 4, 8, 12, 1]) as x;In the above query, we have invoked the AVG Function to calculate the average for a set of input values. The input values are integers passed inside an array. The UNNEST operator helps us to convert the array into rows.
The AS keyword helped us to give a name to the result column.
SELECT AVG(x) as Average
FROM UNNEST([1, 2, 4, 3, 5]) as x;The query will return the following result:

Note that we have a set of integers as the input values, the result is a floating-point value. We also used the UNNEST function to convert the array into rows.
2) Using the DISTINCT Clause with AVG Function
The Google BigQuery AVG Function can also be used together with the DISTINCT Clause. In that case, any value that occurs more than once in the input will only be considered once in the calculation of the average. Consider the example given below:
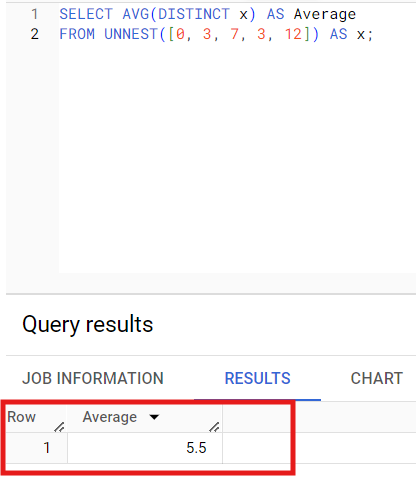
SELECT AVG(DISTINCT x) AS Average
FROM UNNEST([0, 3, 7, 3, 12]) AS x;In the above query, there are two 3s in the input, but only one was considered in the calculation of the average. The reason is that we have used the DISTINCT Clause in the query.
Here is another example:
SELECT AVG(DISTINCT x) AS Average
FROM UNNEST([0, 3, 7, 3, 12, 7]) AS x;The query will return the following result:
Both 3 and 7 occur more than once in the input values, but each was only considered once in the calculation of the average.
Consider the next example given below:
SELECT AVG(DISTINCT x) AS Average
FROM UNNEST([0, 3, NULL, 7, 3, 12]) AS x;The query will return the following result:

In the above query, we have NULL as one of the input values. However, this hasn’t changed the result. This means that the Google BigQuery AVG function ignored the NULL.

3) Using the OVER Clause with AVG Function
SELECT
x,
AVG(x)
OVER (ORDER BY x ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS Average
FROM UNNEST([0, 4, NULL, 2, 4, 6]) AS x;The query should return the following output:

In the above query, we have a number of input values passed into an array. The UNNEST Function helped us to convert the array into a set of rows. We have then used the OVER Clause to specify the window for the Google BigQuery AVG Function.
This has helped us to calculate the average value between the value of x in the current row and its previous row. That is how the Google BigQuery AVG function works.
Conclusion
In this article, you learned the fundamentals of Google BigQuery. You also learned about Google BigQuery AVG Function and its key features, as well as the various operations that can be performed on Google BigQuery AVG Function.
Extraction of complex data from a diverse set of data sources such as Databases, CRMs, Project Management Tools, Streaming Services, and Marketing Platforms to Google BigQuery can be difficult. This is where a simpler solution, such as Hevo Data, can come in handy!
Hevo Data is a No-Code Data Pipeline that offers a faster way to move data from 150+ Data Sources, including 60+ Free Sources, into your Data Warehouse, such as Google BigQuery, to be visualized in a BI tool. Hevo is fully automated and, hence does not require you to code.Want to take Hevo for a spin? Explore Hevo’s 14-day Free Trial and experience the feature-rich Hevo suite firsthand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Share your experience of learning about the Google BigQuery AVG Function in the comments section below!
Frequently Asked Questions
1. What is the AVG function in BigQuery?
The AVG function in BigQuery calculates the average (mean) value of a numeric dataset.
2. What is an approximate aggregate function BigQuery?
Approximate aggregate functions in BigQuery are designed to compute aggregate values quickly and with a trade-off in precision.
3. What is approximate quantile in BigQuery?
Approximate quantile in BigQuery refers to the APPROX_QUANTILES function, which estimates the quantiles (e.g., median, quartiles) of a dataset distribution.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





