




Braintree is an online payment platform that specializes in web and mobile payment solutions for eCommerce companies. To provide a seamless online checkout experience, you’ll have to reduce the time it takes to integrate massive amounts of data from numerous data sources to data warehouses, such as Google BigQuery. You can connect Braintree to BigQuery by writing the code to get the data from Braintree’s API to move it to Google BigQuery. But, if you prefer an automated no-code solution, you can opt for Hevo.
Table of Contents
What is Braintree?

Braintree helps individual merchant accounts for commerce innovators such as Facebook, Airbnb, GitHub, and Uber, facilitating payments spanning 130 currencies and over 40 countries. Braintree’s service aims to replace the traditional model of sourcing merchant accounts from different providers and payment gateways. It achieves this by offering a simple way to enable buying from almost anywhere from the comfort of your mobile app.
With Braintree, you can access the following payment methods:
- Apple Pay
- Debit/Credit Cards
- Venmo
- Android Pay
What is Google BigQuery?

Google BigQuery is Google’s data warehousing solution. As a part of the Google Cloud Platform, it deals in SQL, similar to Amazon Redshift. Google BigQuery helps businesses pick the most appropriate software provider to assemble their data, based on the platform the business leverages.
You can easily interact with Google BigQuery through its web user interface, through a command-line tool. Google also provides various client libraries that you can choose from to interact with Google BigQuery through your application.
Google BigQuery uses a Columnar Storage format that is optimized for analytical queries to store data. BigQuery displays data in tables, rows, and columns, with full database transaction semantics support (ACID). To ensure high availability, BigQuery storage is automatically replicated across multiple locations.
Benefits of Importing Data from Braintree to BigQuery
A payment platform like Braintree contains a vast amount of data related to your company and your customers that are extremely valuable for your business. The data present in your payment system can be used to calculate important KPIs such as your churn and revenues. Your analysts would appreciate it if you can get your hands on all the available data. Luckily, Braintree also houses a rich ecosystem of APIs and tools that you can use to get the most out of your data.
Querying massive volumes of data from Braintree might be tedious without the right infrastructure and hardware. With Google BigQuery, you can leverage super-fast, SQL-like queries against petabytes of data courtesy of Google infrastructure’s processing power. Since Google BigQuery is a no-setup, scalable service, it can provide real-time business insights into your data.
Apart from clarity, moving data from Braintree to BigQuery would also allow you to own your data and reporting. This can allow you to stay ahead of your competition and make data-driven business decisions.
Method 1: Using Hevo to Set Up Braintree to BigQuery
Enjoy a hassle-free experience importing data from Braintree to BigQuery using Hevo. Its fault-tolerant architecture safeguards your data. You can perform complex migrations from sources like Braintree to datawarehouses like BigQuery in minutes.
Method 2: Using Braintree API to Move Data from Braintree to BigQuery
You can also import your data from Braintree to BigQuery using API. However, this method can prove to be inefficient because of the API rate limits and many other factors.
Migrate your data easily using HevoMethods to Replicate Data from Braintree to BigQuery
Method 1: Using Hevo to Set Up Braintree to BigQuery

Using Hevo, Braintree to BigQuery Migration can be done in the following 2 steps:
- Step 1: Configure Braintree as the Source in your Pipeline by following the steps below:
- Step 1.1: Click PIPELINES in the Asset Palette.
- Step 1.2: Next, click +CREATE in the Pipelines List View.
- Step 1.3: Then, on the Select Source Type page, select Braintree Payments.
- Step 1.4: In the Configure your Braintree Payments Source page, mention the following:
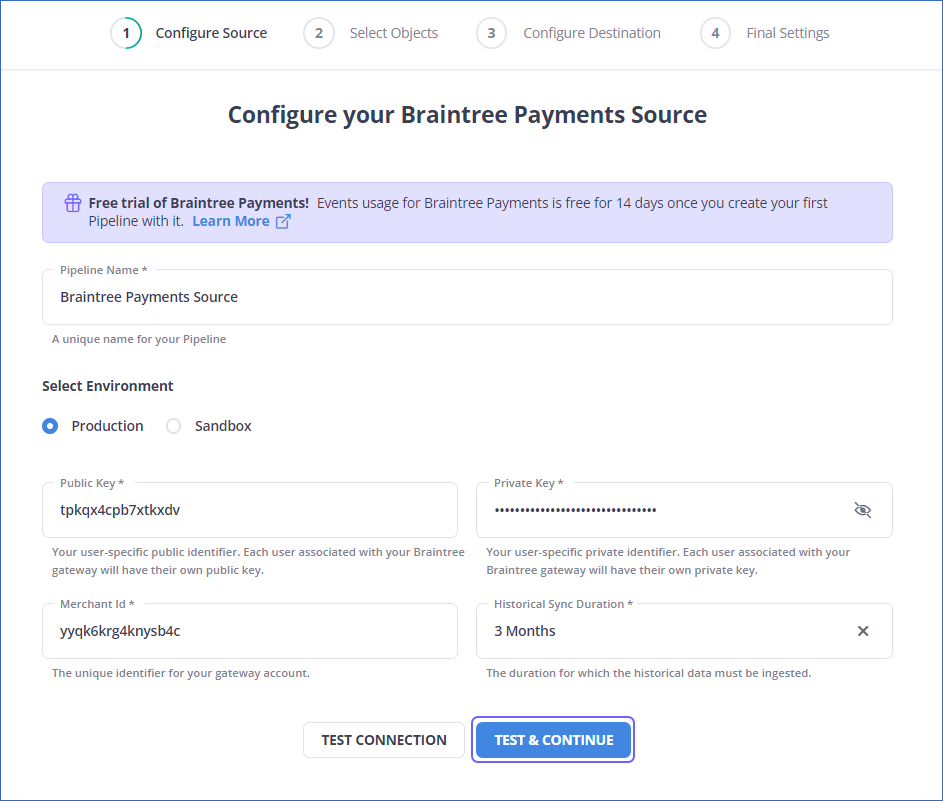
- Public Key: The public key that you got from your Braintree Payments account. You can refer to the section Obtaining the Public, Private API Keys, and Merchant ID for steps to obtain the public key for your environment.
- Pipeline Name: A unique name for your pipeline, not exceeding 255 characters.
- Private Key: It refers to the private key that you obtained from your Braintree Payments account. You can refer to the section Obtaining the Public, Private API Keys, and Merchant ID for steps to obtain the private key for your environment.
- Merchant ID: This is the ID for your merchant account. You can refer to the section Obtaining the Public, Private API Keys, and Merchant ID for steps to obtain the Merchant ID.
- Historical Sync Duration: The duration for which the existing data in the source needs to be ingested. The default value is 3 months.
- Click TEST & CONTINUE.
- Proceed to configure the data ingestion and configure the destination.
- Step 2: To set up Google BigQuery as a destination in Hevo, follow these steps:
- Step 2.1: In the Asset Palette, select DESTINATIONS.
- Step 2.2: In the Destinations List View, click + CREATE.
- Step 2.3: Select Google BigQuery from the Add Destination page.
- Step 2.4: Choose the BigQuery connection authentication method on the Configure your Google BigQuery Account page.

- Step 2.5: Choose one of these:
- Using a Service Account to connect:
- Service Account Key file, please attach.
- Note that Hevo only accepts key files in JSON format.
- Go to CONFIGURE GOOGLE BIGQUERY ACCOUNT and click it.
- Using a user account to connect:
- To add a Google BigQuery account, click +.
- Become a user with BigQuery Admin and Storage Admin permissions by logging in.
- To grant Hevo access to your data, click Allow.
- Using a Service Account to connect:

- Step 2.6: Set the following parameters on the Configure your Google BigQuery page:
- Destination Name: A unique name for your Destination.
- Project ID: The BigQuery Project ID that you were able to retrieve in Step 2 above and for which you had permitted the previous steps.
- Dataset ID: Name of the dataset that you want to sync your data to, as retrieved in Step 3 above.
- GCS Bucket: To upload files to BigQuery, they must first be staged in the cloud storage bucket that was retrieved in Step 4 above.
- Sanitize Table/Column Names: Activate this option to replace the spaces and non-alphanumeric characters in between the table and column names with underscores ( ). Name Sanitization is written.

- Step 2.7: Click Test Connection to test connectivity with the Amazon Redshift warehouse.
- Step 2.8: Once the test is successful, click SAVE DESTINATION.
Method 2: Using Braintree API to Move Data from Braintree to BigQuery
Step 1: Extracting Data
Braintree exposes an API that can be used to combine a product with payment services, as is typical with payment gateways. This API can be accessed via a variety of clients or SDKs that Braintree provides:
- Client SDKs: iOS, Android and Web/Javascript
- Server DSKs: Ruby, Python, PHP, java, js
To make integration easier, Braintree offers client libraries in seven different languages in place of a public REST API. This helps Braintree guarantee:
- Improved Security
- Improved Platform Support
- Backward Compatibility
The following credentials are necessary in order to perform a transaction against the Braintree API and fetch data:
- Public Key: A unique public identification for each user.
- Private Key: A unique, secure identifier for each user that should not be disclosed.
- Merchant ID: Unique identification for the gateway account.
- Environment: Sandbox (for testing) or production.
Through the accessible SDKs, the Braintree API exposes a variety of resources that you may use to interact with the service and carry out any tasks that are included in the platform’s functionality.
The SDKs that Braintree maintains are used to manipulate all of the resources. The complete set of CRUD activities is often supported except during security issues or ambiguity. Generally speaking, you can engage with all of the platform’s content. You can also obtain data using the same SDKs, which can be stored locally to carry out your analytics.
Let’s say that you want to obtain a list of all the Customers you have along with all of the data related to them. For this, you must first conduct a search on the Braintree API, for instance in Java as follows:
CustomerSearchRequest request = new CustomerSearchRequest()
.id().is("the_customer_id");
ResourceCollection<Customer> collection = gateway.customer().search(request);
for (Customer customer : collection) {
System.out.println(customer.getFirstName());
}The aforementioned search will look for all entries that belong to a client with the specified ID. With the help of Braintree’s extremely comprehensive search engine, you may run sophisticated queries based on your data. For instance, you might search based on dates and only receive results for new clients. The following fields will be present in each returned customer object:

Step 2: Preparing Data
Make sure your data is delivered in a manner that BigQuery supports before loading it into the database. For instance, if the API from which you are pulling your data produces XML, you must first convert it into a data format serialization that BigQuery can comprehend. Two data formats are supported for now: CSV and JSON.
Additionally, you must confirm that the data types you are utilizing are those that BigQuery supports, which include the following: STRING, INTEGER, FLOAT, BOOLEAN, RECORD, TIMESTAMP.
Step 3: Loading Data
Use one of the available data sources below to integrate Braintree to BigQuery:
- Google Cloud Storage
- Send information to BigQuery by using a POST request.
- Google Cloud Datastore Backup
- Streaming insert
- Directly Upload CSV and JSON Files
Here, the data is uploaded via JSON files. Execute the following steps to load data into BigQuery:
- First, you must build a dataset and table in Google BigQuery before you can upload any data. Go to the home page of BigQuery and choose the resource where you want to construct a dataset to get started.

- Give your dataset an ID, choose a data location, and specify the default table expiration period in the Create dataset window.
Please take note that the physical storage location will not be determined if you choose “Never” for table expiration. You can define the duration for which you want to store temporary tables.
- Next, make a table in the dataset.
- Finally, choose JSON as the file format. From your computer, Google Cloud Storage, or Google Drive Disk, you can upload a JSON file.

Limitations of Manual Method
Using the Braintree API to move data from Braintree to BigQuery has several limitations:
- API Rate Limits: Braintree imposes rate limits on API requests, which can slow down or restrict large data transfers.
- Complex Data Transformation: The data format from Braintree may require extensive transformation to fit BigQuery’s schema, adding complexity to the integration.
- Manual Effort Required: If you want to perform manual data extraction and loading processes can be error-prone and require significant effort for ongoing maintenance.
- API Data Access Restrictions: Some of your sensitive or detailed data might be restricted or require additional permissions to access via the API.
Use Cases Of Importing Data From Braintree To Bigquery
- Fraud Detection: You can analyse transaction patterns and anomalies by integrating Braintree data with external datasets in BigQuery to identify potential fraudulent activities.
- Customer Insights: You can create comprehensive customer profiles by merging Braintree transaction data with CRM data, enabling targeted marketing and personalized customer experiences.
- Revenue Forecasting: You can utilise historical transaction data from Braintree stored in BigQuery to develop predictive models for forecasting future revenue and sales performance.
Conclusion
This article highlighted the two methods you can implement to replicate data using two Braintree to BigQuery connectors: using the Braintree API, which might be slightly cumbersome, and through a no-code Data Pipeline, Hevo. It also talked about the benefits of moving your data from Braintree to BigQuery along with its key features.
Hevo offers a No-code Data Pipeline that can automate your data transfer process, hence allowing you to focus on other aspects of your business like Analytics, Marketing, Customer Management, etc.
This platform allows you to transfer data from 150+ sources (including 40+ Free Sources) such as Braintree and Cloud-based Data Warehouses like Snowflake, Google BigQuery, etc. It will provide you with a hassle-free experience and make your work life much easier.
You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
FAQs to import data from Braintree to BigQuery
1. How do I transfer data to BigQuery?
To transfer data to BigQuery, use the bq load command to import data from cloud storage, or leverage BigQuery’s data ingestion tools for real-time streaming. You can also use third-party ETL tools to automate and manage data transfers.
2. How to import SQL to BigQuery?
To import SQL data into BigQuery, use the bq load command to upload data files from cloud storage or use the BigQuery web UI to upload data directly. Ensure your SQL data is in a compatible format like CSV or JSON.
3. Is BigQuery free?
BigQuery offers a free tier with limited usage for storage and queries. Beyond these limits, you will incur charges based on the volume of data processed and stored.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



