

As businesses continue to generate massive amounts of data, the need for an efficient and scalable data warehouse becomes paramount. Amazon Redshift has always been at the forefront of providing innovative cloud-based services, and with its latest addition, Amazon Redshift Serverless, the data warehouse industry is being revolutionized.
With Amazon Redshift Serverless, AWS has removed the complexities of provisioning and infrastructure management. You can simply load and query your data and only pay for the what you use. This fully managed, petabyte-scale data warehousing solution seamlessly integrates with the existing Redshift ecosystem.
In this comprehensive guide, we will explore the depths of Amazon Redshift Serverless, its features, benefits, use cases, and how it differs from Amazon Redshift. Let’s dig in!
Table of Contents
What is Amazon Redshift Serverless?
Amazon Redshift Serverless is a cloud data warehousing solution by AWS that eliminates manual provisioning and cluster management.
Unlike, traditional Amazon Redshift which requires users to provision and manage clusters, which involves specifying the number and type of nodes needed for processing data, with the serverless technology you can simply create your data pipeline, and load and query your data.
Amazon Redshift Serverless uses AI technology to scale up or scale down according to the workload in all dimensions such as data volume changes, query complexity, and concurrent users—to maintain your price performance targets. It adjusts capacity in seconds to deliver the best performance even for volatile and huge workloads.
Amazon Redshift Serverless Architecture
Amazon Redshift Serverless follows a decoupled architecture, separating the compute and storage layers. The compute layer uses a seamlessly scalable infrastructure, automatically provisioning and scaling compute resources based on workload demands.
The storage layer leverages a high-performance, distributed storage system based on Amazon S3, where data is durably stored and automatically backed up across multiple Availability Zones.
This architecture enables Redshift Serverless to provide a serverless, scalable, and secure data warehousing solution, allowing organizations to focus on data analysis without managing the underlying infrastructure.
Amazon Redshift Serverless Features
While retaining the core functionalities of Redshift data warehouses, Amazon Redshift Serverless takes it a step further with these serverless-specific capabilities:
| Feature | Description |
| Snapshots | Amazon Redshift Serverless offers the flexibility to migrate existing data warehousing workloads by allowing you to restore snapshots from both serverless and provisioned Redshift deployments onto the serverless environment. Visit Working with snapshots and recovery points for more information. |
| Recovery Points | Amazon Redshift Serverless creates automatic recovery points every 30 minutes, which are retained for 24 hours. These allow you to restore data after accidental modifications or deletions by reverting to a previous point in time. Additionally, you can create snapshots from recovery points to keep them for longer durations if needed. |
| Base RPU capacity | Redshift Serverless lets you set a base capacity in Redshift Processing Units (RPUs), where 1 RPU equals 16GB of memory. This base capacity setting allows you to balance resource allocation and cost for your workloads. You can increase RPUs for better query performance or decrease them to reduce spending. |
| Usage Limits of Data Sharing | Redshift Serverless allows you to limit cross-region data transfers between producer and consumer regions, controlling associated data transfer costs which vary by AWS region and are measured in terabytes. This can be configured through the console or API. |
| User-defined functions (UDFs) | Amazon Redshift Serverless lets you define user-defined functions. |
| Stored procedures | Amazon Redshift Serverless enables you to create stored procedures using the PostgreSQL procedural language PL/pgSQL. |
| Materialized views | Materialized views in Amazon Redshift offer a solution by precomputing and storing the result sets of complex queries involving large tables with billions of rows like multi-table joins and aggregations can be resource-intensive and slow. |
| Spatial functions | Spatial data such as map directions, store locations and weather reports can be queried with Amazon Redshift Serverless. Read more about querying spatial data here. |
| Federated queries | Amazon Redshift Serverless enables you to execute queries that join and integrate data residing in Aurora and Amazon RDS databases. |
| Data lake queries | You can execute queries that combine data from your Amazon S3 data lake with data stored in Amazon Redshift Serverless. |
| HyperLogLog | The HyperLogLog function in Amazon Redshift Serverless allows you to estimate the cardinality or distinct count of a dataset efficiently, using minimal memory. |
| Querying data across databases | Amazon Redshift Serverless supports cross-database queries, enabling you to query data from multiple databases within the same cluster, irrespective of the database you’re currently connected to. |
| Data Sharing | Amazon Redshift Serverless data sharing allows secure, live data access across Redshift clusters, workgroups, AWS accounts, and regions without data movement or copying. |
| Semistructured data querying | With Amazon Redshift Serverless, you can ingest and store semi-structured data using the SUPER data type. |
| Tagging resources | Amazon Redshift Serverless allows you to annotate resources with relevant metadata using either the AWS Command Line Interface (CLI) or the Redshift Serverless API. |
| Machine learning | Amazon Redshift Serverless supports the use of Amazon Redshift machine learning capabilities. Read more about using machine learning in Amazon Redshift Serverless. |
| SQL commands and functions | Amazon Redshift Serverless supports the majority of SQL commands and functions available in Amazon Redshift, with a few exceptions like REBOOT_CLUSTER. |
| CloudFormation resources | With CloudFormation templates, you can automate the provisioning and updating of Amazon Redshift Serverless resources, allowing you to divert your attention from resource management to application development. |
| CloudTrail resources | Amazon Redshift Serverless integrates with AWS CloudTrail, which logs all API calls made to the service, providing a comprehensive audit trail of actions performed within Amazon Redshift Serverless. |
Getting started with Amazon Redshift Serverless
Getting started with Amazon Redshift Serverless is a quick and straightforward process, and it includes $300 in free trial credits. To begin, access the Amazon Redshift service and select the ‘Redshift Serverless’ option located in the upper-left corner.

On the Serverless dashboard you don’t need to worry about provisioning clusters or nodes, it is infact a silent dashboard. Amazon Redshift Serverless automatically sets up your workgroups and namespace in addition to the IAM roles and other important settings.

Namespaces provide an overview of all associated workgroups and serve as the entry point for managing database objects, users, data backup, security, and data sharing. You can view general namespace information such as the ID, ARN, status, creation date, storage usage, and table count.
Workgroups, which are associated with namespaces, give you access to the compute resources for processing data workloads. Here, you can configure data access options like network and security settings, as well as VPC endpoint information.
Additionally, workgroups allow you to set limits on the default Redshift Processing Unit (RPU) capacity, which is 128 by default but can range from 32 to 512 in increments of 8. You can also configure rules for RPU usage limits (e.g., 1 RPU hour per day), resources used by queries, and cross-region data sharing.

Creating a data warehouse with Amazon Redshift Serverless
As you log into the Amazon Redshift Serverless console you get prompted with a getting started experience which can be used to create serverless resources. In this redshift serverless tutorial, we are going to create serverless resources using the default settings. For a more granular hold, you can choose the Customization settings.
- Access the Amazon Redshift console through the AWS Management Console at https://console.aws.amazon.com/redshiftv2, and select the option to “Try Amazon Redshift Serverless”.
- Under the “Configuration” section, choose “Use default settings”. This will create a default namespace and associate it with a default workgroup. Confirm your selection by choosing “Save configuration”. The screenshot provided displays the default configuration settings for Amazon Redshift Serverless.
- After the setup is done, choose continue to go to the Serverless dashboard. All the serverless workgroups and namespaces will be visible.
Loading Sample Data
Now that you’ve configured your data warehouse with Amazon Redshift Serverless, you can use the Amazon Redshift Query Editor v2 to load sample data:
1. From the Redshift Serverless console, choose “Query data” to launch the Query Editor v2 in a new browser tab. This will establish a connection between your client machine and the Redshift Serverless environment.

2. If this is your first time using the Query Editor v2, you’ll need to configure AWS KMS encryption before proceeding. Optionally, you can also specify an S3 bucket URI for later data loading. After providing this information, choose “Configure account”.
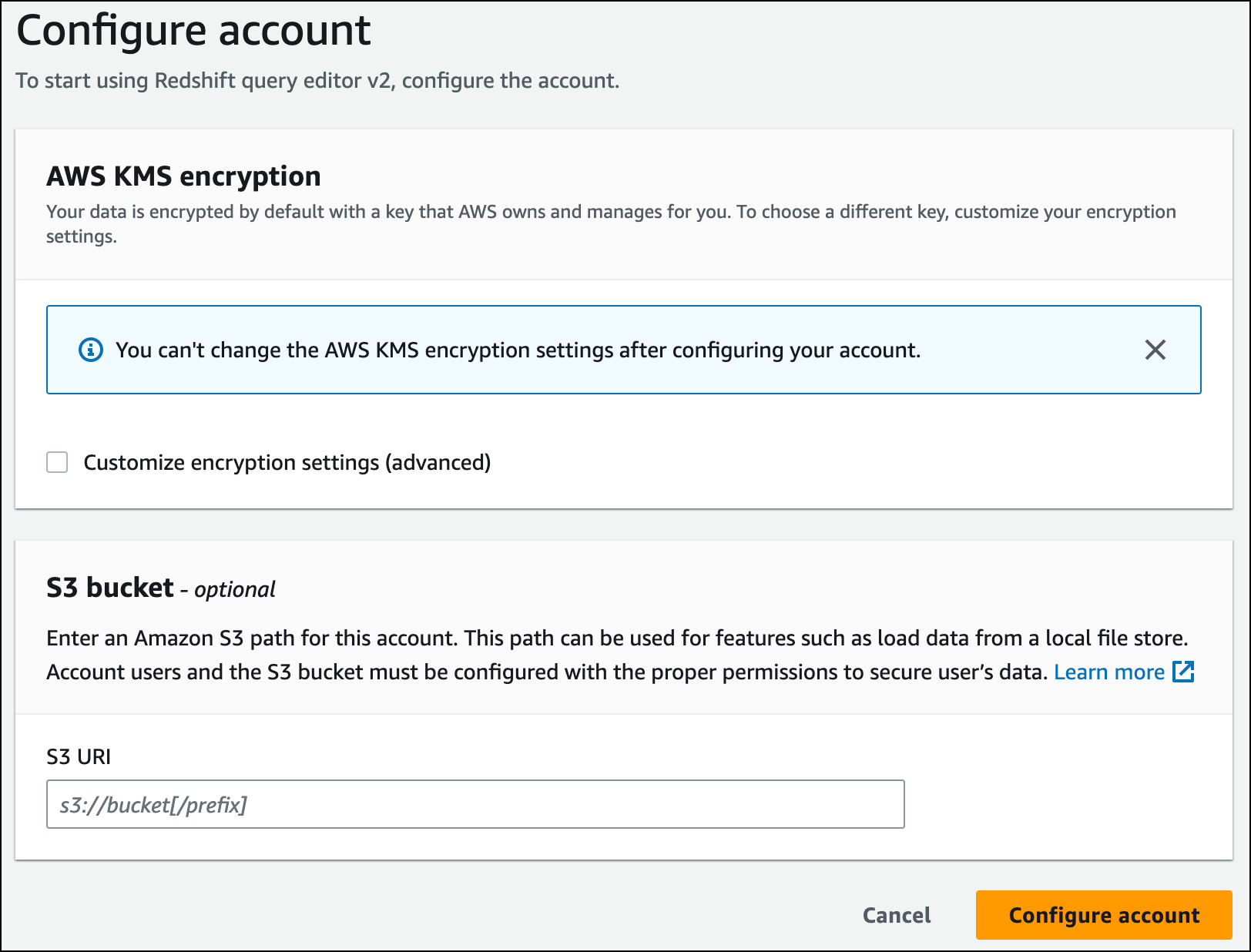
3. To connect to a workgroup, select its name from the tree-view panel.

4. When connecting to a new workgroup for the first time, you’ll need to choose the authentication type. For this guide, leave “Federated user” selected and choose “Create connection”. Once connected, you can choose to load sample data from either Amazon Redshift Serverless or an Amazon S3 bucket.
5. Under the default workgroup, expand the “sample_data_dev” database. There are three sample schemas representing different datasets you can load. Select the desired dataset and choose “Open sample notebooks”.

6. If loading data for the first time, the Query Editor v2 will prompt you to create a sample database. Choose “Create” to proceed.

Running Sample Queries
After configuring Amazon Redshift Serverless, you can begin working with a sample dataset. Redshift Serverless automatically loads the selected sample data, such as the tickit dataset, allowing you to query it immediately.
- Once the sample data finishes loading, the sample queries will be loaded into the editor. You can choose “Run all” to execute all the queries from the sample notebooks at once.

- Additionally, you have the option to export the query results as JSON or CSV files, or visualize them as charts.

Loading in Data from Amazon S3
After creating your data warehouse, you can load data from Amazon S3 into Redshift Serverless:
You currently have a database named ‘dev’. Next, you’ll create some tables in this database, upload data to those tables, and run a query. For convenience, the sample data you’ll load is available in a public Amazon S3 bucket.
- Before loading from S3, you must first create an IAM role with the necessary permissions and attach it to your serverless namespace. Navigate to “Namespace configuration” > “Security and encryption” > “Manage IAM roles”.

- Expand “Manage IAM roles” and choose “Create IAM role”.
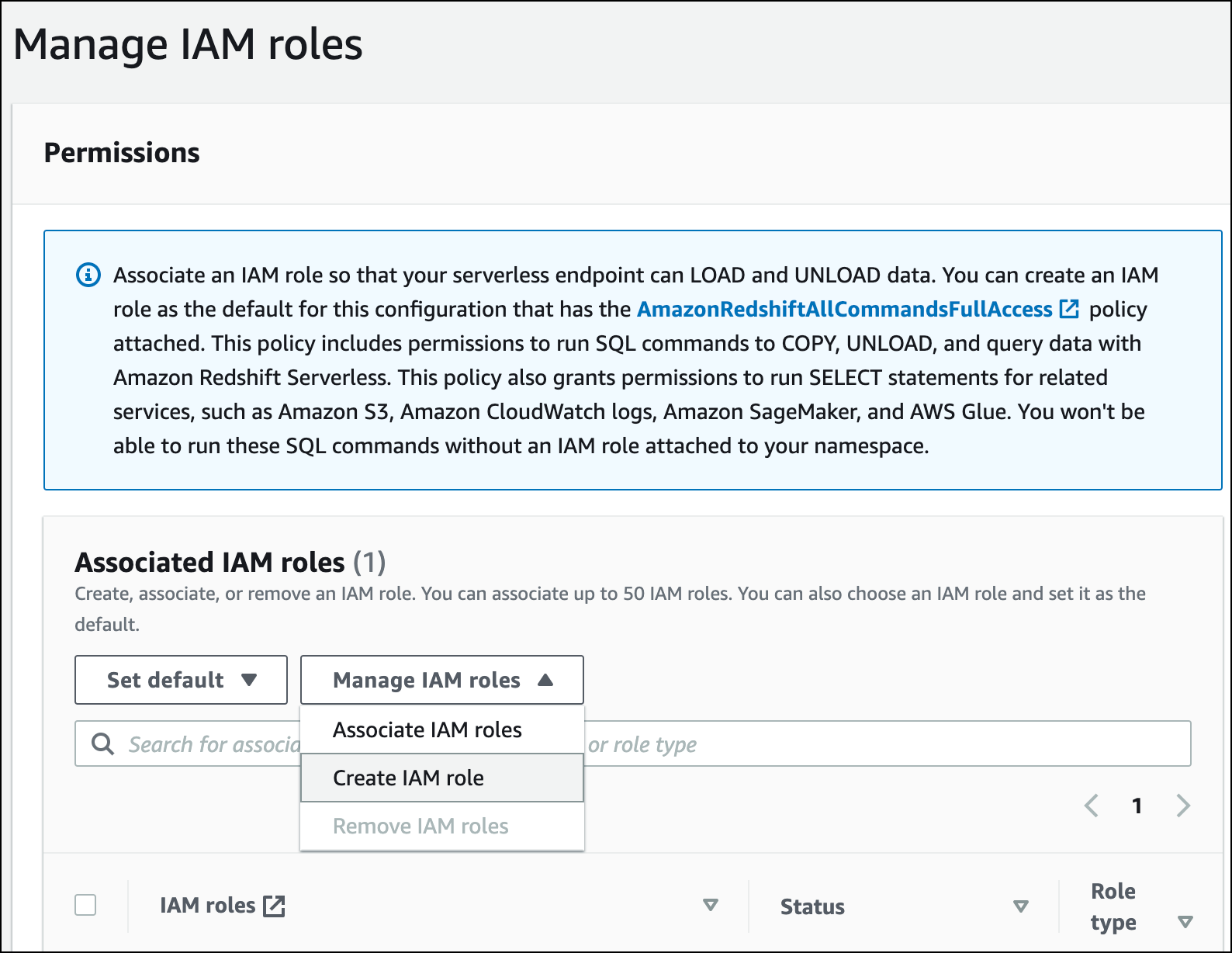
- Select the desired level of S3 bucket access for this role, then choose “Create IAM role as default”.

- Choose “Save changes”. You can now load the sample data from Amazon S3.
The following steps utilize the public Redshift S3 bucket, but you can replicate the same process using your own S3 bucket and SQL commands.
Loading Sample Data from Amazon S3
- In the Query Editor v2, choose “Add”, then “Notebook” to create a new SQL notebook.
- Switch to the ‘dev’ database.
- Create tables by copying and running the provided CREATE TABLE statements in the SQL notebook. These will create tables in the ‘dev’ database. Refer to the CREATE TABLE documentation for syntax details.
create table users(
userid integer not null distkey sortkey,
username char(8),
firstname varchar(30),
lastname varchar(30),
city varchar(30),
state char(2),
email varchar(100),
phone char(14),
likesports boolean,
liketheatre boolean,
likeconcerts boolean,
likejazz boolean,
likeclassical boolean,
likeopera boolean,
likerock boolean,
likevegas boolean,
likebroadway boolean,
likemusicals boolean);
create table event(
eventid integer not null distkey,
venueid smallint not null,
catid smallint not null,
dateid smallint not null sortkey,
eventname varchar(200),
starttime timestamp);
create table sales(
salesid integer not null,
listid integer not null distkey,
sellerid integer not null,
buyerid integer not null,
eventid integer not null,
dateid smallint not null sortkey,
qtysold smallint not null,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp);- Create a new SQL cell in your notebook.
- Use the COPY command to load large datasets from Amazon S3 or DynamoDB into Redshift Serverless. Run the provided COPY commands which use a public S3 bucket for sample data. See the COPY documentation for syntax information.
COPY users
FROM 's3://redshift-downloads/tickit/allusers_pipe.txt'
DELIMITER '|'
TIMEFORMAT 'YYYY-MM-DD HH:MI:SS'
IGNOREHEADER 1
REGION 'us-east-1'
IAM_ROLE default;
COPY event
FROM 's3://redshift-downloads/tickit/allevents_pipe.txt'
DELIMITER '|'
TIMEFORMAT 'YYYY-MM-DD HH:MI:SS'
IGNOREHEADER 1
REGION 'us-east-1'
IAM_ROLE default;
COPY sales
FROM 's3://redshift-downloads/tickit/sales_tab.txt'
DELIMITER '\t'
TIMEFORMAT 'MM/DD/YYYY HH:MI:SS'
IGNOREHEADER 1
REGION 'us-east-1'
IAM_ROLE default;- After loading data, create another SQL cell and run some example SELECT queries to interact with the loaded data. Consult the SELECT documentation for more details. Explore the sample data structure and schemas using the Query Editor v2.
-- Find top 10 buyers by quantity.
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales
GROUP BY buyerid
ORDER BY total_quantity desc limit 10) Q, users
WHERE Q.buyerid = userid
ORDER BY Q.total_quantity desc;
-- Find events in the 99.9 percentile in terms of all time gross sales.
SELECT eventname, total_price
FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) Q, event E
WHERE Q.eventid = E.eventid
AND percentile = 1
ORDER BY total_price desc;Redshift Serverless Monitoring
- Monitoring Amazon Redshift Provisioned Clusters involves tracking various metrics such as CPU utilization, disk usage, network performance, and query execution times to ensure optimal performance and identify potential issues.
- With Amazon Redshift Serverless, AWS handles the infrastructure and cluster management, reducing the complexity of monitoring. Your focus can shift to query performance and data-related metrics.
- Serverless insights can be achieved using System Views and CloudWatch metrics, which provide detailed monitoring capabilities for query performance and data metrics.
System Views
Monitoring serverless queries and workloads can be achieved with the help of system views, which are available in a system schema called pg_catalog. The system views have been streamlined to provide the essential information required for monitoring Amazon Redshift Serverless.
Here is a list of the available system views in this schema you can directly query through the query editor.

The system views provide insights from multiple perspectives such as:
- Workload Views: Here you can monitor queries over time to understand the workload patterns and deviations, if any.
- Data Load & Unload Views: These views help you understand the bytes or rows transferred and your file processing status.
- Failure and problem diagnostics: These views help in understanding the query or runtime failures.
- Performance tuning views: These views provide you with the run plan statistics, duration, and resource consumption associated with your queries.
- User object Views: This view helps you understand the actions and activities of user objects, such as refreshing materialized views, vacuum and analyze.
- Usage Tracking: These views help you in budget planning, cost estimates, and identifying the cost saving opportunities.
Granting Access to Monitor Queries
A superuser can assign users to query monitoring in two simple steps: add a query monitoring policy for a user or a role and then grant query monitoring permission.
To add the query monitoring policy
- Open https://console.aws.amazon.com/iam/.
- Choose “Policies” under “Access Management”
- Select “Create Policy”
- Select JSON and paste the following policy definition
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"redshift-data:ExecuteStatement",
"redshift-data:DescribeStatement",
"redshift-data:GetStatementResult",
"redshift-data:ListDatabases"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "redshift-serverless:GetCredentials",
"Resource": "*"
}
]
}- Select “Review Policy”
- Enter any Name for the policy such as, query-monitoring.
- Select “Create Policy”
You can grant the appropriate permissions now.
To grant query monitoring permission for a user
Users who have been granted the sys:monitor role can view and monitor all queries executed on the system. Additionally, users with the sys:operator role have extended privileges that allow them to cancel running queries, analyze query history, and perform vacuum operations for maintenance purposes.
To grant the necessary roles and permissions, follow these steps:
- Execute the following command, replacing user-name with the actual user’s name, to provide system monitoring access:
grant role sys:monitor to “IAM:user-name”;
- Optionally, if you want to grant system operator access, execute the following command, again replacing _user-name_ with the user’s name:
grant role sys:operator to “IAM:user-name”;
To grant query monitoring permission for a role
To grant these permissions to specific roles, follow these steps:
- Execute the following command, replacing role-name with the actual name of the role you want to grant access to:
grant role sys:monitor to “IAMR:role-name”;
- Optionally, if you want to grant the sys:operator role and its extended privileges, execute the following command, again replacing role-name with the role’s name:
grant role sys:operator to “IAMR:role-name”;
CloudWatch Metrics
CloudWatch is another service offered by the AWS suite for monitoring your cloud resources and applications. To use it, you must configure Redshift serverless to export connection, user, and user activity log data to AWS CloudWatch.
After selecting the Redshift log types you want to export, you can monitor the log events within Amazon CloudWatch Logs. A new log group is automatically created for your Amazon Redshift Serverless instance, where the log_type represents the specific log type being exported.
The log group follows this naming convention:
/aws/redshift/<namespace>/<log_type>
When you create your first workgroup and namespace, the default namespace name is default. However, the log group name will reflect the custom name you provide for your namespace.
For instance, if you choose to export the connection log, the log data will be stored in the following log group:
/aws/redshift/default/connectionlog
The log events are exported to the log group using a serverless log stream, which allows for seamless integration with CloudWatch Logs.
Additionally, CloudWatch can also be used to create alarms against any of the events you are interested in. See Managing Alarms for more information.
Amazon Redshift Serverless – Use cases
- Self-Service Analytics: Amazon Redshift Serverless goes beyond basic reporting. It lets you perform what-if analyses, anomaly detection, and ML-based forecasting in seconds for real-time analytical insights.
- Auto-scaling for Unpredictable Workloads: You do not need to worry about spending time determining your compute capacity or overspending issues. Amazon Redshift Serverless automatically scales to handle your workloads, whether it’s regular usage throughout the day or complex, hard-to-predict query peaks.
- New Applications: If you’re unsure about how to determine the appropriate size for your data warehouse when deploying a new data-driven application, consider initiating an Amazon Redshift Serverless endpoint, which will automatically size your data warehouse according to your workload requirements.
- Auto-scaling for variable workloads: Applications with fluctuating usage patterns, such as HR, budgeting, and operational reporting tools, can benefit from Redshift Serverless, eliminating the need for over- or under-provisioning capacity, thus avoiding unnecessary costs, performance issues, and user experience degradation.
- Multi-tenant applications: To accommodate multi-tenant applications where each tenant experiences varying levels of activity at different times, such as during promotional events or seasonal fluctuations, the Amazon Redshift Serverless architecture is designed to employ individual workgroups tailored for each tenant. These workgroups feature a flexible capacity range, allowing rapid scaling to effectively manage peaks in activity as needed.
Amazon Redshift Serverless Pricing
Free Trial
Amazon Redshift Serverless offers a free trial to new users. This lets you try out the service and see if it meets your needs before committing to a paid plan.
- Free Credit: If you’re a new user, you get a $300 credit to use towards compute and storage costs during your free trial. This credit is valid for 90 days from the time you sign up.
- Monitoring Usage: You can track your free trial usage in two ways:
- Redshift Console: The console will display your remaining free trial credit balance.
- SYS_SERVERLESS_USAGE View: This system view lets you see detailed information about your free trial usage.
- Billing Transparency: Charges incurred during the free trial won’t show up in the regular billing console. You can only see usage details there after the trial ends.
Billing for Compute Capacity
- Provisioned Clusters Monitoring: Monitoring Amazon Redshift Provisioned Clusters involves tracking various metrics like CPU utilization, disk usage, network performance, and query execution times to ensure optimal performance and identify potential bottlenecks or issues.
- Simplified Monitoring with Serverless: With Amazon Redshift Serverless, AWS manages the infrastructure and cluster management, significantly reducing the complexity of monitoring and shifting the focus to query performance and data-related metrics.
- Query Performance Focus: In a Redshift Serverless environment, your monitoring efforts are streamlined to concentrate primarily on query performance, making it easier to maintain and optimize the system.
- Tools for Serverless Insights: Serverless insights can be obtained using System Views and CloudWatch metrics, which offer detailed monitoring capabilities for assessing query performance and data metrics in a Redshift Serverless environment.
Monitoring Amazon Redshift Serverless usage and cost
Monitoring Amazon Redshift Serverless usage and cost can be done in several ways. System views and CloudWatch are helpful tools for this purpose.
Visualizing usage by querying a system view
You can query the SYS_SERVERLESS_USAGE system table to track usage and get the charges for queries:
select trunc(start_time) "Day",
(sum(charged_seconds)/3600::double
precision) * <Price for 1 RPU> as cost_incurred
from sys_serverless_usage
group by 1
order by 1This query provides the cost per day incurred for Amazon Redshift Serverless, based on usage.
Visualizing usage with CloudWatch
You can use the metrics available in CloudWatch to track the billing usage. The relevant metrics are:
- ComputeSeconds: Indicates the total RPU seconds used in the current minute.
- ComputeCapacity: Indicates the total compute capacity for that minute.
Billing for Redshift Serverless Storage
In Amazon Redshift, the primary storage capacity is billed as Redshift Managed Storage (RMS). The storage billing is calculated based on the amount of storage used in gigabytes per month. It is important to note that the storage billing is separate from the billing for compute capacity.
Additionally, the storage used for user-created snapshots is billed at the standard backup billing rates, which depend on the usage tier you belong to.
Wrapping Up
This fully managed and automatically scaling data warehousing solution abstracts away the complexities of capacity planning, cluster management, and infrastructure provisioning, allowing you to focus on data analysis without worrying about the underlying infrastructure.
Enhance your system with our guide on Redshift performance tuning to optimize query efficiency and overall database performance.
Frequently Asked Questions
1. How to setup ongoing replication from Redshift to Redshift Serverless?
- Create a snapshot of your provisioned cluster and restore it to your Redshift Serverless instance. This will serve as your baseline data in the serverless environment.
- Set up data sharing between your provisioned cluster and the Redshift Serverless instance.
- Execute “insert into” scripts to copy data from the shared tables in your provisioned cluster to local tables in your Redshift Serverless instance.
- It’s recommended to have audit fields or mechanisms in place to identify and pull only incremental records. For tables without such audit capabilities, you’ll need to perform a full table refresh.
2. Does Redshift Serverless Support Load from Remote Host via SSH?
- The COPY command in Amazon Redshift allows you to load data in parallel from one or more remote sources, such as Amazon EC2 instances or other computer systems.
- When using COPY, Redshift establishes SSH connections to the remote hosts and executes commands on those hosts to generate text output streams.
- These text output streams are then loaded into your Redshift database tables in parallel, providing efficient and scalable data ingestion capabilities.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





