




Corporations deal with massive amounts of data these days. As the amount of data increases, handling the incoming information and generating proper insights becomes necessary. Selecting the right data management services might be baffling since many options are available.
Multiple platforms provide services that can assist you in analyzing and querying your data. In this article, you will review the main differences between Amazon Athena vs Redshift Serverless and understand which one best suits your workload.
Table of Contents
An Overview of Amazon Athena

Amazon Athena is an intuitive query service in the AWS ecosystem designed to analyze data from Amazon S3 using standard SQL queries. Within seconds, you can use Amazon Athena to run ad-hoc queries with standard SQL to analyze your Amazon S3 data.
Athena simplifies the running data analytics with Apache Spark. You can submit Spark code for processing and receive results directly without configuring or managing resources. Athena SQL is a serverless service that does not require any infrastructure setup. You only need to pay for the queries you run.
Amazon Athena is compatible with other AWS services like AWS QuickSight, which allows you to conduct thorough analysis through visualization. You can also easily connect your business intelligence tool, such as Tableau to Athena for real-time analysis.
Hevo Data, a No-code Data Pipeline, helps load data from any source, such as Databases, SaaS applications, Cloud Storage, SDKs, and Streaming Services, and simplifies the ETL process. Hevo loads the data onto the desired Data Warehouse, such as Amazon Redshift, in real-time, enriches the data, and transforms it into an analysis-ready form without having to write a single line of code.
Check out why Hevo is the Best for you:
- Effortlessly extract data from 150+ connectors.
- Tailor your data to Snowflake’s needs with features like drag-and-drop and custom Python scripts.
- Achieve lightning-fast data loading into Snowflake, making your data analysis-ready.
Try to see why customers like Whatfix and Cure.Fit have upgraded to a powerful data and analytics stack by incorporating Hevo!
Get Started with Hevo for FreeAn Overview of Amazon Redshift Serverless
Amazon Redshift is a cloud-based data warehouse service offering a powerful solution for organizations to store structured and semi-structured data. It leverages the ability of cloud storage and computing to perform cost-effective analysis of your data.
You can use Amazon Redshift to ingest data from different sources, perform SQL queries, and build reports based on the insights generated. Due to its serverless nature, Redshift simplifies the data analysis process without additional infrastructure management.
With Amazon Redshift serverless, you can get an efficient solution to scale your data utilizing AI-driven optimization techniques that can ensure fast performance even with higher workloads.
Let’s look at the Redshift Serverless vs Athena comparison.
Differences between Amazon Athena and Amazon Redshift
Let’s understand the advantages and disadvantages of Athena vs Redshift Serverless before considering anyone over the other. Here’s an overview of the key differences:
| Feature | Amazon Athena | Redshift Serverless |
| Architecture | Works on DPUs, four virtual CPUs with 16 gigabytes of RAM. | Works on RPUs, two virtual CPUs with 16 gigabytes of RAM. |
| Performance | High latency, in some cases, is due to a multi-tenant environment. | You can have more control over the performance due to an isolated environment. |
| Scalability Factor | It can scale vast data but may encounter frequent time-out sessions. | Can scale up to the mentioned Max Capacity setting of RPUs. |
| Cost Effectiveness | It is cost-efficient but provides fewer features and has limitations in scaling data. | Although Redshift Serverless costs more than Athena for the same services, it provides better functionality. It provides billings per compute capacity. |
| Integration Capabilities | Access data directly from Amazon S3, databases, and other custom sources. | Access data from Amazon S3, data warehouses, data lakes, and other third-party datasets. |



Take a look at the differences between Redshift vs Athena in more detail:
1. Athena vs Redshift Serverless: Architecture
- Amazon Athena operates in a serverless environment with a detached storage and computation setup. This setup enables querying Amazon S3 data directly without data ingestion. Since it works within a multi-tenant system, its resources are shared among users. Some specific computational resources for each query in Athena are inaccessible to users since a shared resource pool determines them.
- Athena provides an option to reserve dedicated processing capacity, known as Dedicated Processing Units (DPUs), that you can use to access additional resources within the Athena environment. Each DPU contains four virtual CPUs with a total of 16 gigabytes of RAM, allocated from 24 to 1000 per region.
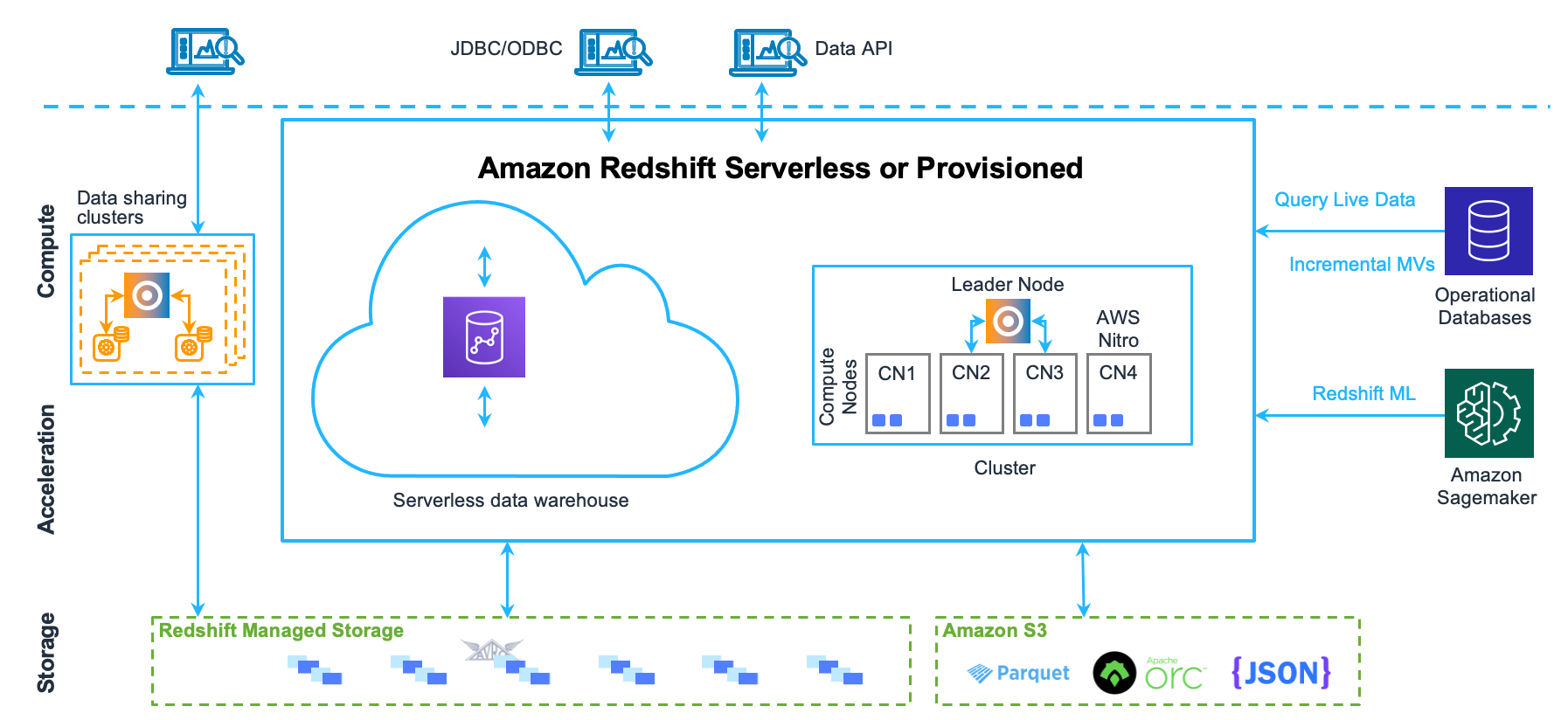
- Amazon Redshift Serverless ensures isolation by dedicating personal environments for each customer. Deploying Redshift in your Virtual Private Cloud (VPC) gives you more control over security and network systems. Redshift Serverless revolves around the concept of Redshift Processing Units (RPUs).
- RPUs range from 8 to 512, incrementing eight units per value. Each RPU consists of 2 virtual CPUs and 16 gigabytes of RAM. The smallest available allocation of RPUs is 8. Therefore, 8 RPUs equate to 16 virtual CPUs with 128 gigabytes of RAM.
2. Athena vs Redshift Serverless: Performance
- Athena is designed to prioritize easy and immediate operations by directly querying where it is present. However, you must also consider the setbacks that come with this functionality. In terms of speed, Athena tends to lag behind other data warehouses.
- Despite supporting partitions, it lacks indexing support functionality. Sometimes, the demand for the query surpasses the resources allocated to the cluster that executes it. When this happens, the query terminates with an error message.
- In Amazon Redshift Serverless, resources are allocated according to your Redshift cluster size and are isolated from shared resources. This functionality allows you to have more control over the performance of your Redshift Serverless instance.
- You can allocate additional resources to a query command in Redshift Serverless to increase the overall performance.
3. Athena vs Redshift Serverless: Scalability Factor
- As AWS Athena works on multi-tenant functionality with shared resources, it can suffer from frequent time-out sessions and longer run times. If scalability is your top priority, Athena might not be the best choice since its query concurrency maxes out at 20.
- Redshift Serverless autonomously scales to manage higher workloads to ensure consistent performance. Your Amazon Serverless billing contains base compute and scale capacity at the same RPU rate. The Max Capacity setting configures the highest level of RPU that Amazon Redshift Serverless can scale up to. This enables you to manage your compute resource expenses.
4. Athena vs Redshift Serverless: Cost Consideration
- Using Amazon Athena, you can start querying data and pay based on the data scanned by the queries. The charges are on the amount of data queried, with a minimum charge of 10 megabytes for each query.
- No charges are deducted for failed queries and Data Definition Language (DDL) statements. Strategies such as data compression, partitioning, and converting the data into columnar format can optimize cost and enhance performance. For more, refer to Amazon Athena Pricing.
- On the other hand, Redshift Serverless charges as little as $3 per hour. The other charges for computational capacity are incurred when the data warehouse is active. It automatically adjusts resources in response to your workload, allowing for optimal performance and resource allocation.
- Amazon Redshift Serverless provides a pay-as-you-go option to pay only for the services used. For more information, you can read Amazon Redshift Serverless Pricing.
5. Athena vs Redshift Serverless: Integration Capabilities
- AWS Athena can access data directly from Amazon S3, databases, and other custom data sources. It allows integration with Amazon Glue and creates a unified metadata repository across multiple services. You can crawl through data sources automatically using Glue Data Catalog, uncovering the data and updating the data catalog with modified tables and partition definitions.
- In this case, schema versioning is available. You can employ Glue’s fully managed ETL capabilities to convert data into a columnar form, enhancing the overall query performance and lowering expenses.
- Redshift Serverless generates actionable insights from structured and unstructured data in Amazon S3, data warehouses, data lakes, and other third-party datasets. In Amazon Redshift Serverless, you must set up external tables for each schema within the Glue Data Catalog.
- There are multiple data integration ways under Redshift Serverless services. You can connect to Amazon Redshift Serverless through JDBC drivers, with Data API, with the help of VPC endpoint, and many more. To learn more, you can read the Amazon Redshift Serverless Connections documentation.
- Using these technologies can get daunting for organizations, as you are required to have prior technical knowledge. This is why most businesses consider automated SaaS-based solutions to integrate data from their in-house data sources to other data management sources.
Key Takeaways
- Managing and analyzing large volumes of data is essential to business management today. Therefore, selecting the right technology is necessary for most companies.
- You have discovered the main advantages and differences between Athena vs Redshift Serverless through this article. Consider the differences to decide which technology best suits you.
- You can also refer to the article Amazon Redshift and Athena to understand the difference between Amazon Redshift and Athena.
- If you want to change your environment from Redshift to Athena, you can transfer data from Redshift to S3.
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines. You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
Frequently Asked Questions (FAQs)
1. What is the difference between Amazon Redshift Serverless and Athena?
Athena is based on Presto and is well-suited to performing ad-hoc queries. On the other hand, Redshift is based on PostgreSQL and competes more with Snowflake and BigQuery.
2. What is the threshold for implementing AWS Athena to Amazon Redshift Spectrum?
The primary consideration revolves around the storage infrastructure. Storing large amounts of structured data suits a proper data warehouse service like Redshift. However, it will not be suitable for effective data management and analysis if you attempt to manage large volumes of data through a flat format like Parquet.
3. Can Redshift be serverless?
Yes, Amazon Redshift can be serverless. With Redshift Serverless, you can run and scale your data warehouse without managing the underlying infrastructure. It automatically handles capacity and scaling based on your workload, allowing you to focus on analyzing your data instead of managing servers.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link




