


The greatest tool collection for handling enormous volumes of data – delivering, managing, and using data for analytics is known as the “modern data stack”. Lately, it has come to dominate the data industry.
The positive: The modern data stack is extremely quick, quick to scale up, and has little overhead.
The negative: In terms of providing governance, trust, and context to data, it’s still a rookie.
This is where metadata comes into play.
So while the rest of the data stack has advanced, metadata management has not. Companies are ingesting an ever-increasing amount of data, but data catalogs are having a hard time keeping up. Turmoil and distrust in data are some repercussions.
Data catalogs of previous generations saw data as discrete, disconnected, static entities to be cataloged and numbered, rather than what they are: continually developing resources with context and relationships, much like people.
The best part is that the new age data catalogs aka Data Catalog 3.0 take an original approach to data & a modern data catalog is constructed on top of a knowledge graph that values the connections between the data as highly as the data itself.
Table of Contents
The Basics of Metadata: What is it?
Metadata is information about data. It gives crucial context and data descriptions; helping data users understand the structure, nature, and context of their business data.
For a better understanding, consider your regular excel spreadsheet. If your rows and columns include text or numbers, the columns’ contextual information would be those descriptions. You can grasp what your data implies or depicts with the use of metadata.

Metadata facilitates the discovery of relevant information. It helps in organizing electronic resources, interoperability, digital identification, and archiving and preservation by summarizing basic information about data.
Time to stop hand-coding your data pipelines and start using Hevo’s No-Code, Fully Automated ETL solution. With Hevo, you can replicate data from a growing library of 150+ plug-and-play integrations to any destination warehouse or database.
Hevo’s in-built Transformations accelerate your business team to have analysis-ready data without writing a single line of code!
Start your Journey with HevoWhy do I Need Metadata?
Data and Business teams are already overwhelmed with vast quantities of information that is available to them. The only thing they need to have is a mechanism to locate the necessary information, one that is fast and easy to use.
Where, then, does its importance originate? Although the motivation behind its relevance is not a mystery, metadata may provide that impression.
Users typically attribute a document metadata problem when they claim that their search does not produce relevant results or that they are unaware of where to seek business-critical information.
We were taught to arrange stuff using folders and tree structures in the past.
Think about how challenging and time-consuming it will be to browse through multiple directories to obtain the information you’re looking for.
Metadata can be useful in this situation. By effectively utilizing and putting the tag theory into practice on a document, the data team would be able to categorize material and make it findable and searchable to efficiently drive business processes.
Because it enables you to arrange your data in a way that is relevant to you and makes it simpler to discover the information you’re searching for; metadata is crucial. Maintaining accuracy and consistency in your data is also beneficial.
Metadata ensures that your data is FAIR: Findable, Accessible, Interoperable, and Reusable.
- Findable: Finding relevant material is made considerably simpler by metadata. Formats like music, pictures, and video are constrained unless text information is present because the majority of searches are performed using text (like a Google search). Because metadata defines exactly what a text document is about, it also makes such papers simpler to search.
- Accessible: Metadata describes how data may be accessed, perhaps including authentication and authorization, after a user locates the information they want.
- Interoperable: A data collection can be combined with other data by assigning metadata. Additionally, the data must work with different processes or apps for analysis, storing, and processing.
- Reusable: In order to reuse a data collection, researchers must comprehend its structure, the meanings of the terminology used, how it was gathered, and how to interpret it. Data must be accurately documented in order to be duplicated and/or integrated into many contexts.
What are the Different Types of Metadata?
Metadata can be divided into two major categories:
Passive Metadata
Passive metadata is the most often used method for gathering and storing metadata in a static data catalog. It is basically technical information that contains fundamental data specifications such as schema, data types, models, owner names, and so on.
Active Metadata
Active metadata enables seamless and rapid metadata flow throughout the whole data stack, integrating rich context and data into each and every data stack tool. You can think of it as descriptive information that gives context to data by detailing everything that occurs to it (e.g., operational, business, and social metadata).
Active metadata can be compared to a viral narrative. It appears to appear instantly everywhere you already dwell. It is promptly compared to and merged with other data, connecting a network of relevant contexts into a bigger trend or story. Additionally, it generates discussions that ultimately increase everyone’s knowledge and awareness.
Why do I Need Modern Metadata Management?
Until a few years ago, an organization’s IT team would mostly use data. Today’s data teams, however, are more diversified than ever. They include data engineers, analysts, analytics engineers, data scientists, product managers, business analysts, and more. Each of these people has their own preferred and equally varied data tools, ranging from Tableau, DBT, and R to SQL, Looker, and Jupyter.
This situation creates a bit of a ruckus in terms of team collaboration. A lack of understanding of data makes even the most efficient employee struggle to keep up with the targets.
It is surprising to see that even though it is a common problem witnessed by all firms that aspire to be data-driven, the modern data catalog aka Data Catalog 3.0 hasn’t emerged as a crucial part of the modern data stack.
How does Metadata Management Benefit My Business?
- Improved Consistency: Metadata management creates a standard definition of metadata across the company to avoid data retrieval challenges caused by competing words.
- Better Data Quality: Metadata management systems nearly usually make use of automation, which is capable of detecting data errors and inconsistencies in real-time.
- Easier Accessibility of Insights: Data scientists now have more time to evaluate data in order to extract true business value, and data teams may complete projects more quickly.
- Cost Savings: Metadata management efficiency improvements and repetitive operations minimize redundancy and unnecessary expenses, such as storage costs.
What is Data Catalog 3.0?
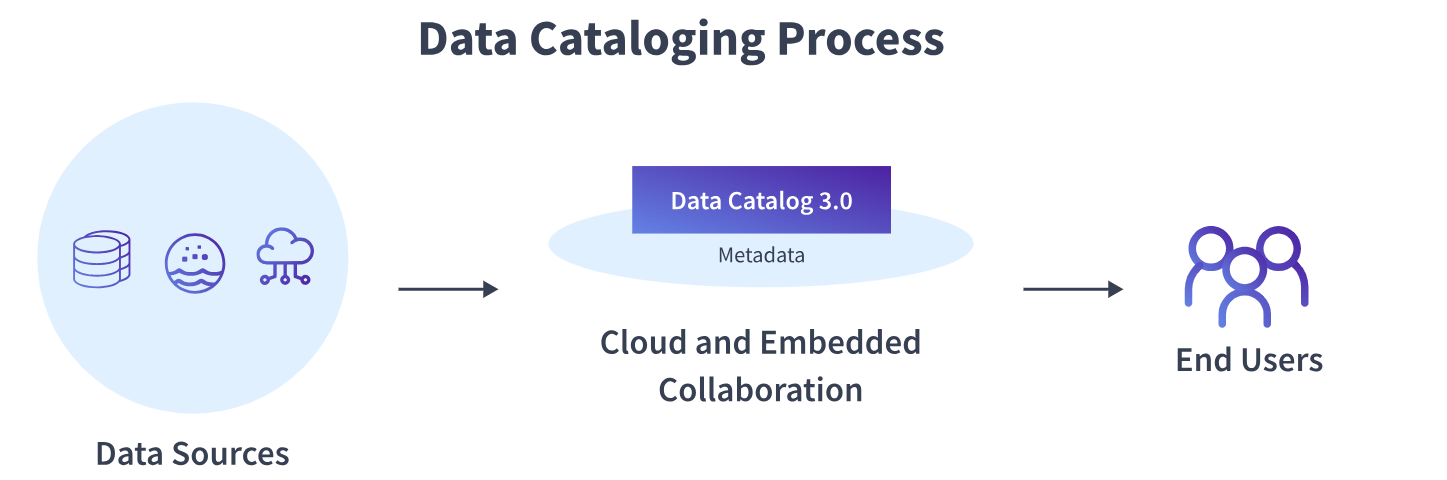
The era of the on-premise, slow Data Catalog 2.0 is coming to an end, and a new one, Data Catalog 3.0, is beginning. This marks an important turning point in metadata management.
Third-generation data catalogs commonly referred to as Data Catalog 3.0 will seem more like collaborative, self-service tools in today’s modern workplace than their predecessors.
Data Catalog 3.0 offers an agile approach to data governance that gives your team instant access to understandable, applicable, and trustworthy data, allowing every employee of your company to make smarter, data-informed decisions, unearth deeper insights, & promote continuous development across all areas of your business.
They also enable collaboration to let the teams work together by allowing comments in a dataset, ranking them, and creating wiki-like pages. These collaborative tools also allow for the provision of crowd-sourced metadata on the data’s reliability. In this sense, Data Catalog 3.0 is useful for both internal and external reasons, since it lays the groundwork for data exchange.

Evolution of Metadata Management
The way we approach and use metadata has changed over the past three decades, much like how we approach and use data. Data Catalog 1.0, Data Catalog 2.0, and Data Catalog 3.0 are the three primary stages of its progression.
Data Catalog 1.0: IT Team Metadata Management

Technically, metadata has existed since the earliest times, as evidenced by the descriptive tags affixed to each scroll in the Library of Alexandria. The contemporary concept of metadata, however, wasn’t invented until the late 1900s.
Thankfully, we abandoned floppy discs in the 1990s and welcomed this cutting-edge technology called the internet. Big data and data science quickly became popular, and businesses began to consider how to structure their brand-new data sets.
IT teams were given the task of producing an “inventory of data” as data kinds, formats, and the actual data itself grew. Companies like Informatica had the lead in metadata management early on, but IT always struggled to set up and maintain their new data catalogs.
Data Catalog 2.0: Data Controllers Fuel the Data Inventory

Data Catalog 2.0 refers to a group of specialists who were in charge of looking after an organization’s data. They would deal with metadata, uphold governance standards, manually document data, etc.
The concept of metadata changed in the interim. Companies began setting up extensive Hadoop systems after realizing that a straightforward IT inventory of data was no longer sufficient. New data catalogs were instead required to combine data inventory with fresh business context.
Data Catalog 2.0s were challenging to build up and manage, much like the ultra-complex Hadoop systems of the time. This prompted a rebuild of the existing data catalog, which now has evolved into the concept of Data Catalog 3.0.
Data Catalog 3.0: Cloud-native Collaboration Focused Element of Modern Data Stack

We are currently at a turning point in metadata management, moving from the cumbersome, on-premise Data Catalog 2.0 to the dawn of a new era, Data Catalog 3.0. This will result in a fundamental change in how we see metadata, much to the transition from version 1.0 to version 2.0.
Data Catalogs 3.0 won’t have the same appearance and feel as their 2.0-generation forebears. Instead, they will be based on integrated collaboration and draw inspiration from cutting-edge technologies that teams currently use and adore.
What are the Key Features of Data Catalog 3.0?
Empowers Metadata
We live in a world where metadata is becoming big data in and of itself. The insight we can draw from metadata grows in unison with the variety of use cases that metadata can power.
It is no longer enough to simply arrange and preserve technical metadata. We want data catalogs that activate metadata, that is, catalogs that can locate, inventory, enhance, and use all types of information – allowing for manual or automated use across the stack.
Organized & Consolidated Metadata
Data assets are typically dispersed across several locations – data lineage tools, data quality tools, data prep tools, and so on. Modern data catalogs often serve as the integrated access layer from all data sources and repositories, and they are driven by visual querying capabilities to enable democratic access to everyone – data and business teams.
Enables Integrated Teamwork
Analysts, engineers, business users, product specialists, scientists, and others make up data teams. They all have different tool preferences, skill sets, and workflows. Modern data catalogs appreciate the value of diversity and are inclusively built to serve all of them in their natural environments.
Enables Fine-Grained Governance & Access Control
As more individuals utilize data, its worth rises. Before businesses can perceive the actual value of their own data, usage and acceptance must reach a critical mass. But then there’s the issue of governance and access to sensitive data.
This difficulty is eliminated by modern data catalogs, which provide granular control not just for data stewards but also for every data creator and consumer in the company.
Based on an Open API Framework
The modern data stack is growing and changing. As a result, catalog tools that are open by default and easily expandable with the tools you use are advantageous. Today, your data stack may look like this, but tomorrow you may want to add new capabilities, even re-engineer some – the modern data catalog should make it easy for data teams to create their own architecture on top of it.
What Makes Data Catalog 3.0 Essential for My Businesses?
Business Scalability
A microservices architecture underpins cloud-native data catalogs. Microservices architecture is defined by Amazon Web Services as “an architectural and organizational approach to software development in which software is made of tiny independent services that communicate over well-defined APIs.” This architecture has the advantage of being quick to implement and simple to scale.
A cloud-native third-gen data catalog may be deployed significantly faster than a previous-gen cloud-based or cloud-enabled one. Traditionally produced catalogs often need the installation of software and/or the provisioning of hardware. None of this is required for a Data Catalog 3.0.
These characteristics of Data Catalog 3.0 allow you to scale as per the needs of your business with considerably less overhead while also keeping up with your fast-evolving modern data stack.
Recurring Release Cycle
Another advantage of Data Catalog 3.0 being cloud-native and using microservices architecture is the ability to distribute updates and upgrades quickly. Because each component is constructed independently, there is no code exchange; all communication between autonomous components is done via a simple API.
Because cloud-based data catalogs are typically constructed on monolithic architectures with closely integrated code and procedures, they need substantially more effort to manage. As the program works as a single entity, it becomes increasingly difficult to add or upgrade features as the code complexity evolves.
Pricing is Crystal Clear
The third advantage of Data Catalog 3.0 being cloud-native may come as a surprise: price transparency. Simple products that are easy to try, buy, and grow are a trademark of SaaS. However, this is not the case with many cloud-based data catalogs. If you want to discover how much anything costs, you must call or email their sales team.
While some of this is due to a demand capture strategy (after all, the best-qualified prospect is the one who contacts you), it may also be attributable to a catalog’s inflexible deployment and adoption methodology, which makes it more expensive to maintain and hence a higher cost to the end-user.
Applications of Data Catalog 3.0 and Who’s Using Them
Metadata Management & Access
A data catalog has to compile descriptive data about each piece of data in order for it to work. Later, the metadata helps the user to quickly and effectively discover the needed data based on certain qualities.
For this, the data catalog makes use of the customer’s databases. These include, for instance, databases, data lakes, data warehouses, ERP systems, CRM systems, and ERP systems. These may be accessed either directly through a database connection, through APIs, or through ingesting databases and can be kept either “on-premise” or in the cloud.
Data catalog may also include various forms of data information, like APIs, data lineages, and connections between data as well as data reports with visuals.
Data Management & Organization
A data catalog is responsible for setting up and indexing data. It examines data sources based on metadata, tags, annotations, similarity, the relevant context, or the data origin to achieve this. It doesn’t matter what kind of data it is or if the data is already structured or is still unstructured.
With the use of Artificial Intelligence (AI), Machine Learning (ML), semantic interference, tags, patterns, or connections, Data Catalog 3.0 is successfully able to scan databases in a systematic manner and automatically derive the necessary information.
Learn about Offensive vs Defensive Data Strategy: Do You Really Need to Choose?
Data Governance
According to Contiamo, 43% of analyses are held back due to governance concerns.
A data catalog’s fundamental component is the data governance function. This process controls and records how users access data. The data governance function determines responsibilities for the data, gives roles and permissions, and evaluates the data quality and data flows. It is feasible to follow the company’s internal compliance criteria while also taking into consideration regulatory requirements like the General Data Protection Regulation (GDPR) on the basis of working data governance.
If you want to know more about the real-world use cases of the data catalog you can have look at What is Data Catalog?
Data Users
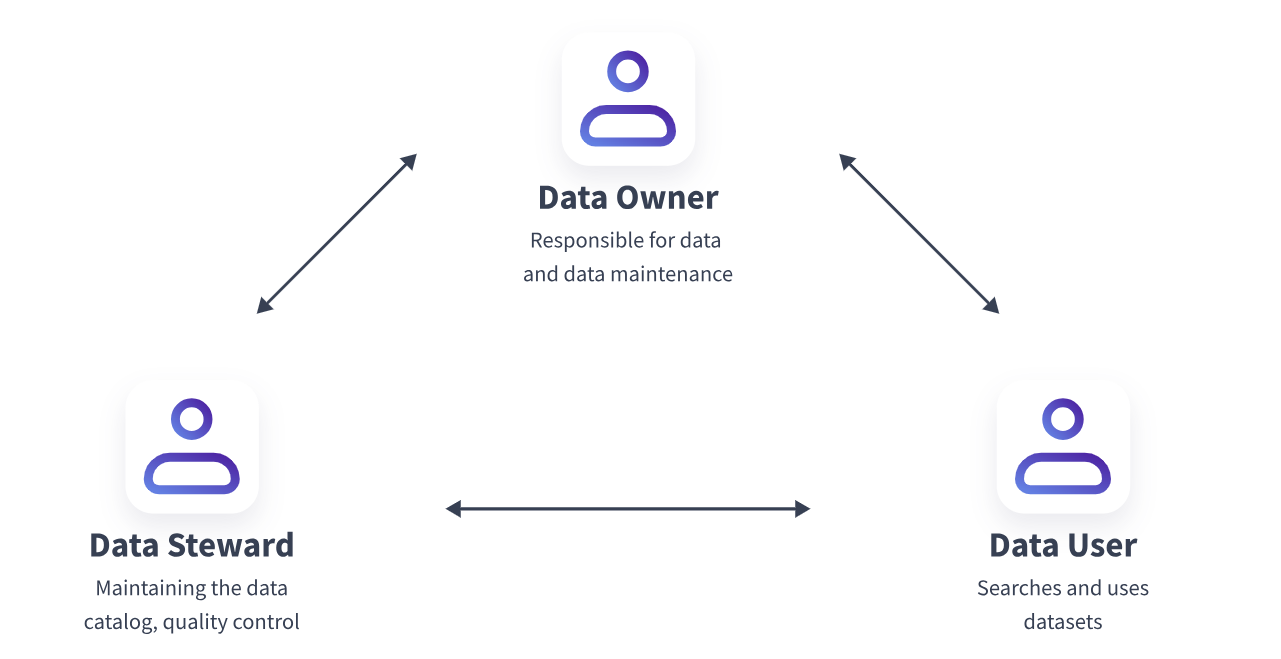
- Data Proprietor
The “owner” of the data is the data owner/proprietor. They are in charge of the data and its upkeep. The data owner’s efforts have a significant impact on the quality of the data catalog. - Data Steward
They guarantee the quality of the data and maintain the metadata in the catalog. They play a key role in the development of the data catalog, the enhancement of preexisting information, and the catalog’s upkeep. To ensure accuracy, they collaborate closely not just with the data owner but also with the business users. - Data Consumer
The data catalog is frequently used by data users for their job. They employ datasets for research and assessment and conduct focused data searches.
Final Thoughts
Moving data to new systems, altering processes and workflows, and upsetting much of the information within the organization about where to get data and how to utilize it is all part of modernizing your data stack. The good news is that by implementing a modern data catalog aka Data Catalog 3.0, your users will not be affected by these changes. The end-user may continue to easily discover and use the data as it changes as long as you update where the catalog tries to find that resource.
While your data architecture must always change to suit the demands of the company, this does not mean that your users must suffer from tool fatigue. Data governance implemented by your Data Catalog 3.0 should aim to empower and assist your data workforce rather than control and constrain it.
Your users will be met where they are by a Data Catalog 3.0. And it acts as a continual information center that links to their chosen tools — whatever they are now or will be tomorrow — rather than being yet another “all-in-one” tool that must be acquired, so discarding years of accumulated knowledge and experience.
Tell us what you think about Data Catalog 3.0 & Metadata Management in the comment section below!
FAQ
What is the data catalog?
A data catalog is a searchable inventory of data assets, providing metadata to help users find, understand, and manage data. It improves data discovery, governance, and collaboration.
What is data catalog Microsoft?
Microsoft Data Catalog is a cloud-based service that helps users discover, understand, and manage data assets. It enhances data governance by organizing metadata in Azure.
What is the OCI data catalog?
OCI Data Catalog is Oracle’s cloud-native service for managing metadata across Oracle Cloud Infrastructure. It enables data discovery, lineage tracking, and governance in OCI environments.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





