

The fast-growing pace of big data volumes produced by modern data-driven systems often drives the development of big data tools and environments that aim to support data professionals in efficiently handling data for various purposes. At the same time, the architecture design of such systems is also facing changes to optimize any part of the data processing pipeline (ingestion, storage, processing, etc.).
Enter Delta Lake: the optimized storage layer designed to complement data lakes. According to its developers, the new storage format aims to increase reliability and improve the performance, security, and data consistency of the underlying data lakes.
However, questions remain about how much Delta Lake actually improves existing Data Lakes and when it makes sense to upgrade a Data Lake to a Delta Lake. So let us delve into its features, compare Data Lake vs Delta Lake and see how it addresses these questions.
Table of Contents
What is Medallion Architecture?
The Medallion architecture is a data design pattern used for logically organizing data in a data lakehouse.

The data organization scheme consists of the Bronze, Silver and Gold layer (Figure 1). The Bronze layer represents the initial storage location for raw data ingested from source systems, supplemented with metadata information such as ingestion timestamp and process ID.
The Silver layer stores data transformed to a certain degree to be consumed by analytics jobs. Finally, the subject-specific data ready for consumption is stored in the Gold layer, which represents the source for generating reports and publishing the results to users. This layer corresponds to the data marts and the star schema found in data warehouses.
Confused about Data Lake vs Delta Lake? Use Hevo’s intelligent ETL platform to streamline your data integration workflow, regardless of your storage solution. With Hevo, your data team can:
- Connect 150+ data sources to your preferred destination
- Transform data with a no-code, user-friendly interface
- Ensure real-time data accuracy and consistency
Trusted by 2000+ companies, Hevo has been rated 4.7 on Capterra. Find out how Postman saved 40 hours of their developer efforts with Hevo.
Get Started with Hevo for FreeDelta Lake vs Data Lake: Architecture and Design
How Data Lakes Work and their Architecture
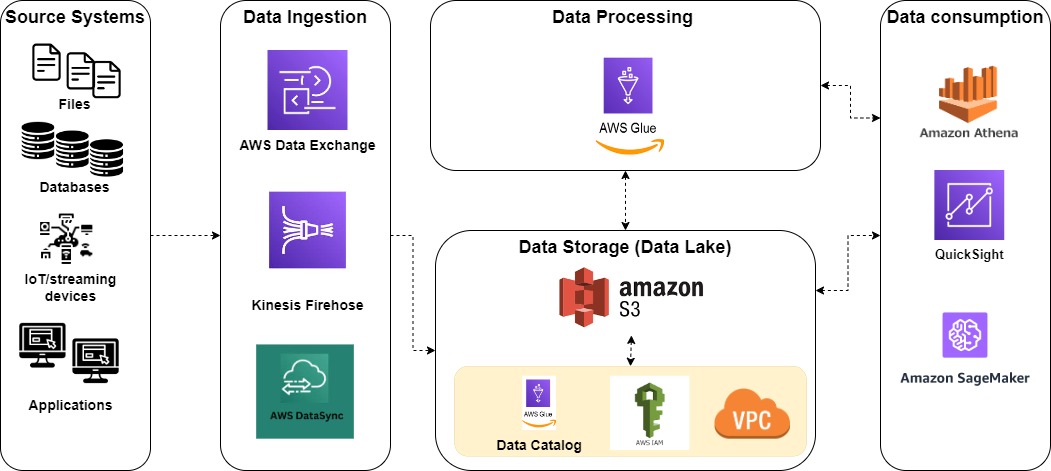
A Data Lake is a centralized data storage architecture used to store data in original format. The Data Lake multi-layered architecture comprises:
- Data ingestion layer: collects heterogeneous data from data sources;
- Data storage layer: it includes several data zones, which store data depending on its degree of processing;
- Data processing layer: transforms data to the required format before moving it between data zones;
- Data consumption layer: provides an interface for users to access data.

How Delta Lakes Work and their Architecture
The Delta Lake architecture extends the Data storage layer:
- Delta table: a transactional table where data is stored in columnar format for efficient large-scale data processing;
- Delta log: a transaction log that records changes made on Delta tables;
- Storage layer: an object store for persisting data within the Delta lake.
Delta Lake vs Data Lake: Data Storage and Formats
Data storage formats in Data Lakes
Data Lakes store raw data in its original format (e.g., tables, JSON files), as ingested from various sources. The storage layer is built on top of object storage solutions such as Azure Blob Storage, where data is stored as files in different formats (Apache Parquet, ORC, Avro, Text or JSON).
Delta Lake Storage Format and Optimization
The Delta Lake storage format builds upon the Parquet format by adding a file-based transaction log for ACID transactions and scalable metadata management. Each Delta table comes with a reference to the Parquet file in the object store and the transaction log folder, which records all changes, while users use regular table operations to insert, update or delete rows from a table.
Data Partitioning and Indexing
Partitioning and indexing are two common strategies for handling data in Data Lakes. Partitioned datasets divided into smaller chunks help query the data. However, the excessive number of partitions can downgrade the performance of such jobs and is recommended for columns with lower cardinality (e.g., dates). The core idea of the Delta Lake format is to reduce excessive partitioning on datasets, so it uses statistics built for Delta tables (e.g., table row count) to build the optimized query execution plan that reads only relevant data. Z-order indexing is an additional mechanism that enables data files to be ordered only by the frequently used columns.
Delta Lake vs Data Lake: Data Quality and Reliability
Handling data quality issues in Data Lakes
The ELT approach makes it difficult to validate data quality in Data Lakes. Although tools are available for data quality checks, the following strategies are recommended:
- Landing/raw zone – data profiling (i.e., analyzing the structure, content and metadata about data sources), building quality checking rules based on business rules, measuring quality KPIs, storing metadata into a Data Catalog.
- Refined zone – common dictionaries, final KPI measurements before publishing data.
ACID Transactions in Delta Lake
Each write operation on the Delta Lake table that changes its state is recorded in the Delta Lake transaction log together with its metadata description. Therefore, before running any changes to a Delta table, Delta Lake first retrieves information about the last recorded state of that table, then changes the underlying Parquet data file and adds a new transaction record into the transaction log. This prevents users from corrupting tables with their changes.
Schema Enforcement and Evolution
The supported schema enforcement and evolvement ensures that the stored data always meets the data quality rules and remains consistent in different processing stages. Furthermore, the tiered approach within the medallion architecture facilitates progressive data quality maintenance within and across zones. A good design practice is to develop dedicated pipeline workflows for monitoring data quality on different granularity levels (e.g., by data source or zone).
Delta Lake vs Data Lake: Performance and Scalability
Query Performance in Data Lakes
Data lake query optimization techniques such as partitioning reduce query costs and improve performance. However, partitioning can also create an excessive number of small data files. Therefore, it’s important to find a balance between the benefits of partitioning and the drawbacks of small files.
Delta Lake Performance Features
Delta Lake automatically merges small files. Combined with Z-indexing, this significantly reduces disk reads. For even faster access to frequently used tables, Delta Lake offers “liquid clustering,” a flexible way to group similar data without rewriting data.
Scalability Tips
Delta Lake offers ways to keep your data storage efficient, especially for tables managed by Unity Catalog. It can automatically optimize these tables by reorganizing the data files for better compression.
Delta Lake vs Data Lake: Use Cases and Applications
When to Use Data Lakes?
Some common use cases for Data Lakes include:
- Storing large and diverse datasets
- Advanced analytics and Machine Learning (ML)
- Real-time analytics
- Data exploration
When to Use Delta Lakes?
Delta Lake is highly recommended if:
- You need reliable data pipelines
- Optimized query performance and fast analytics are your primary concern
- Time travel and data lineage are important
- You need a unified Big Data platform
- You need reliable data for ML workflows
Case Studies and Industry Examples
Nowadays, various industries build their data-driven solutions on Data Lakes, whereas Delta Lakes are still on a growing usage trajectory. For instance, the music streaming giant Spotify leverages Data Lakes to recommend music to users, and the telecommunications industry giant, AT&T, adopted a cloud-based data lakehouse architecture powered by Databricks to handle massive datasets and detect fraud.
Delta Lake vs Data Lake: Data Governance and Security
Governance Challenges in Data Lakes
Deleting or updating data in a Data Lake is compute-intensive, as scanning through folders to identify the correct data files without a reliable data catalog is inefficient. For this reason, Delta Lake implements an integrated Unity Catalog for robust data governance. In contrast, the Data Lake architecture requires the integration of external governance tools.
Security Features in Data Lakes vs Delta Lakes
Tracing data’s origin and transformations is a challenge, making it difficult to pinpoint issues or comply with regulations in Data Lakes. Furthermore, they often store sensitive information, demanding strong access controls to prevent unauthorized access. All data is encrypted using industry-standard algorithms like AES-256. Delta Lakes leverage ACID transactions to ensure successful writes before committing changes to the data, minimizing data corruption.
Access Control and Logging
Data Lakes protect sensitive information through granular access controls and Access Control Lists to ensure only authorized users can view or modify data. For even finer control, data lakes can isolate sensitive information based on project needs. Conversely, Delta Lakes rely on the underlying storage platform’s access control features.
Delta Lake vs Data Lake: Tools and Ecosystem
Tools and Frameworks commonly used with Data Lakes
Some commonly used tools and frameworks in Data Lakes include:
| Component | Examples |
| Storage Platforms | Cloud object storage, HDFS |
| Data Ingestion Tools | ETL/ELT tools |
| Data Processing Frameworks | Apache Spark, Hive, Presto |
| Data Governance Tools | Apache Ranger, Atlas |
| Data Analytics Tools | BI and ML tools |
Delta Lake Integration with Databricks
Delta Lakes extend Data Lakes with additional functionality:
- Databricks Delta Lake: Features for working with Delta Lakes (direct data visualization, ML, and data warehousing).
- Delta Lake Open Source: Libraries and tools for various programming languages for interacting with Delta tables.
- Delta Integrators: Integrations with external frameworks beyond Apache Spark (e.g., Presto, Flink).
- Delta Standalone: Enables standalone applications written in Scala or Java to read and write data to Delta tables.
Open Source vs. Proprietary Tools
The landscape of Data Lake and Delta Lake implementation has expanded with many open-source and proprietary tools. Established vendors such as Amazon, Google or Microsoft already offer dedicated tools and services able to implement all components of the Data Lake architecture.

Open-source tools are free to use and modify, making them budget-friendly and adaptable to specific needs. However, this flexibility comes with the responsibility of managing your own infrastructure and relying on online communities for support. Proprietary tools come with licensing fees and limited customization options.
Delta Lake vs Data Lake: Cost Considerations
Cost implications of Data Lake Storage and Processing
Some key factors to consider when building a Data Lake are:
- Infrastructure: You can choose on-premises solutions, cloud-based platforms, or a hybrid approach.
- Data Ingestion: Costs depend on the volume, variety, and velocity of your data, and the tools used for data ingestion.
- Data Storage: Cloud providers typically offer tiered storage options with varying costs based on access frequency.
- Data Governance: This involves tools, personnel, and processes to ensure data integrity and compliance with regulations.
- Data Management and Analytics: Transforming raw data into usable insights requires additional tools for data processing.
- Ongoing Maintenance: Maintaining the infrastructure requires an ongoing effort from IT and data engineering teams.
Cost Benefits of Delta Lake Optimization Techniques
There are some cost considerations specific to upgrading your Data Lake with a Delta Lake:
- Underlying Storage Costs: You’ll still incur storage charges based on the amount of data in the Data Lake.
- Compute Costs: Processing data involves using cloud-based compute resources like Databricks clusters. These services typically charge per unit of computing power used.
- Potential Savings in reduced storage, improved query efficiency, and time travel.
- Managed Services: If you use a managed Delta Lake service like Databricks Lakehouse, there might be additional platform fees.
Cost Comparison between Traditional Data Lakes and Delta Lakes
Building Data Lakes and Delta Lakes incurs certain costs throughout their lifetime:
| Feature | Data Lake | Delta Lake |
| Upfront Infrastructure Cost | Lower | Potentially Higher |
| Storage Cost | Potentially Higher | Lower |
| Data Management Cost | Higher | Lower |
| Risk of “Data Swamp” | Higher | Lower |
Delta Lake vs Data Lake: Future Trends and Innovations
Emerging Trends in Data Lake Technologies
One key trend is the rise of data lakehouse architectures. Another trend is the emergence of serverless data lakes to reduce the operational burden and costs of managing the infrastructure. Improvements in data catalogs and metadata management tools are making data lakes more navigable and user-friendly. Overall, these trends highlight a data lake market moving towards greater efficiency, accessibility, and real-time capabilities.
Innovations in Delta Lake and their Impact on the Industry
Delta Lakes, whilst still evolving, offer exciting possibilities for the future:
- Open Source Focus: Improved performance, scalability, and integration with other open-source tools for wider adoption.
- Liquid Clustering: Groups frequently accessed data for faster queries and lower storage costs.
- Generative AI Integration: Seamless work with Generative AI tools for training and deploying models.
- Enhanced Security: Ongoing development to further strengthen existing security features.
- Universal Format: Read and write Delta Lake data using various engines beyond Apache Spark.
Predictions for the Future of Data Management Systems
Vendors such as Databricks are already working to reach valuable customers and spread the adoption of the data lakehouse concept. Data democratization will make data available to a wider audience via improved data management tools. Generative AI is also expected to play a bigger role in automating data tasks and monitoring data quality.
The future of data management is about automation, accessibility, security, and empowering organizations to leverage their data for smarter decisions and innovation.
Delta Lake vs Data Lake: Comparison Summary and Conclusion
Summary of Key Differences and Similarities
Some of the similarities between the two approaches include:
- Scalability and flexibility: Both Data Lakes and Delta Lakes can handle massive amounts of differently structured data.
- Centralized Storage: Both act as central repositories of data, where data is stored in one place through different processing stages.
- Cost-effectiveness: Both provide a more cost-effective way of storing large datasets.
The design variations result in the following differences:
- Reliability: Data Lakes lack sufficient built-in mechanisms to enforce data consistency as it progresses through pipeline stages.
- Schema Enforcement: The “schema on read” approach in Data Lakes makes it challenging to enforce schema on ingested data.
- Performance: Data lakes struggle with querying large datasets or complex data structures due to resource-consuming scans. Delta Lakes benefit from optimized data organization and processing techniques.
- Data versioning: Data lakes don’t offer historical versions of data. Delta Lakes automatically version your data in transaction logs.
Pros and Cons of Data Lake vs Delta Lake
A more precise overview of the benefits and drawbacks of the two technologies is presented in the table below:
| Feature | Data Lake | Delta Lake |
| Flexibility | High | Moderate |
| Scalability | High | High |
| Simplicity | High | Lower |
| Data Quality | Lower | High |
| Performance | Lower | Higher |
| Schema Enforcement | Lower | Higher |
| Data Versioning | No | Yes |
| Cost | Lower | Potentially higher |
| Vendor Lock-in | No | Potential lock-in to Databricks |
| Use Case | Initial data storage with diverse data sources | Data integrity, performance, advanced analytics |
Delta Lake vs Data Lakes – Which to choose?
You should choose Data Lakes if:
- You’re starting with a new data management system.
- Data exploration and discovery are your primary goals.
- Cost is a major concern.
- Your data quality needs are less strict.
A Delta Lake is the preferred option if:
- Data integrity and consistency are crucial.
- You require advanced analytics on large datasets.
- Data lineage and version control are important.
- Your organization is already invested in the Databricks ecosystem.
Choose the solution that meets your requirements the best. Book a personalized demo with Hevo to take your data management one step further and streamline your data integration.
Frequently Asked Questions
1. Does Delta Lake sit on top of Data Lake?
Yes, Delta Lake is a storage layer that sits on top of a Data Lake, adding features like ACID transactions, scalable metadata handling, and data versioning.
2. What is the difference between Big Lake and Delta Lake?
Big Lake is a Google Cloud service that unifies data across data warehouses and data lakes, while Delta Lake is an open-source storage layer that brings ACID transactions and scalable metadata handling to data lakes.
3. Can Delta Lake replace Data Warehouse?
No, Delta Lake is designed to enhance data lakes by adding structure and reliability, but it does not replace a data warehouse, which is optimized for complex queries and reporting.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




