



In the digital world, where data drives decisions, innovation, and growth, data loading has emerged as an essential process within the data ecosystem. From start-ups to enterprises, there is a need for effective methods of transferring, processing, and using data for competitive advantage.
This blog digs deep into the concept of loading data to a warehouse, exploring its types, techniques, challenges, tools, and best practices, and discussing its impact on businesses and emerging trends. So, let’s dive in!
Table of Contents
What is Data Loading?
Think of it as stocking a warehouse. Imagine you run a grocery store. Your inventory/stockroom(source) has all the products(data), but they need to be stocked on the shelves(destination) for the customers to access and use. This movement of data from source to destination is called data loading.
It is the “LOAD” phase of the ETL (Extraction, Transformation, Load) process. It transfers the processed data into a storage system, such as a cloud data warehouse.
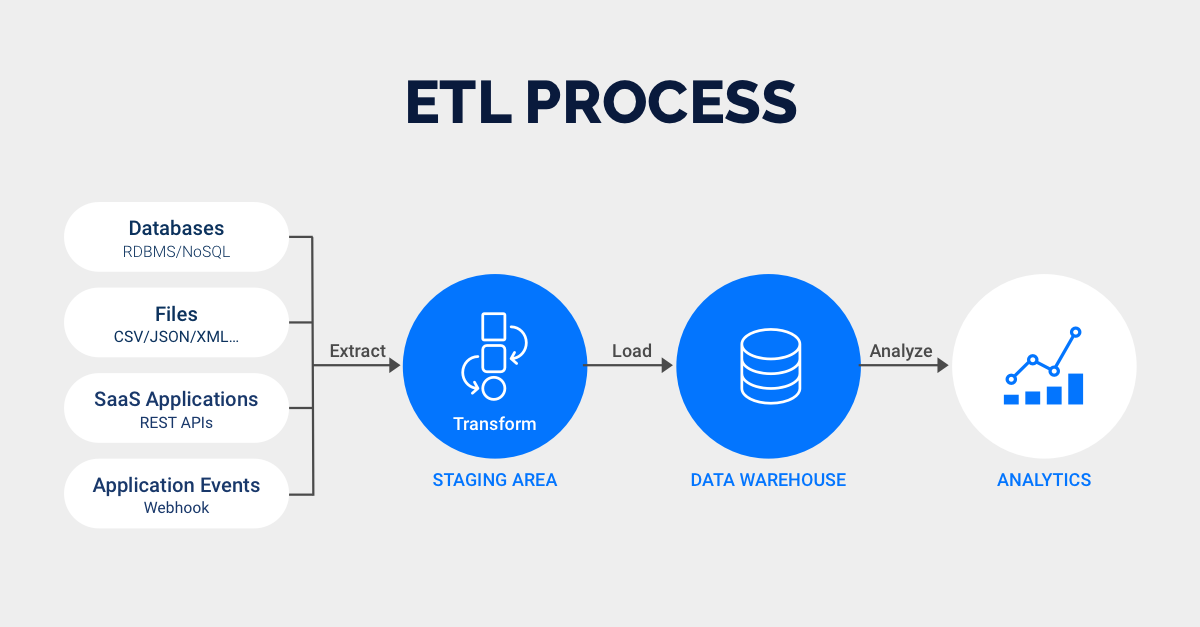
Why It Matters?
If the stock is not replenished efficiently, the shelves remain empty, and customers leave disappointed. In the same way, if your data is not loaded smoothly, analytics platforms cannot work at their best, causing delays in decision-making. It is vital because of the following reasons:
- Enables Business Intelligence: Organizations can perform advanced analytics by transferring data into centralized storage.
- Improves Decision-Making: Accurate and timely data empowers informed decisions.
- Facilitates Integration: Combines data from multiple sources for a unified view.
Effortlessly load data from 150+ sources to your data warehouse in minutes. Say goodbye to complexity and hello to simplicity! With Hevo, you can:
- Automate Data Extraction: Effortlessly pull data from 150+ connectors(and other 60+ free sources).
- Transform Data effortlessly: Use Hevo’s drag-and-drop feature to transform data with just a few clicks.
- Seamless Data Migration: Quickly load your transformed data into your desired destinations.
Try Hevo and join a growing community of 2000+ data professionals who rely on us for seamless and efficient migrations.
Get Started with Hevo for FreeWhat are the Types of Data Loading in Data Warehouse?

Depending on load volume and frequency, they are of the following types:
| Method | Description | Advantages | Drawbacks |
| Full Load | Loads all data from source to target. | Simple to implement; Ensures data consistency. | Time-consuming for large datasets; Inefficient for frequent updates. |
| Incremental Load | Loads only new or changed data since the last load. | Efficient for large datasets; Reduces data transfer volume. | It requires tracking of changes; it can be complex to implement. |
| Batch Load | Loads data in batches at scheduled intervals. | Suitable for non-time-sensitive data; Reduces peak load on systems. | It may introduce latency, which is not suitable for real-time applications. |
| Stream Load | Loads data as soon as it becomes available. | Low latency; Ideal for real-time applications. | It requires high processing capacity and can be complex to implement. |
Which Method to Choose When?
The tricky question is deciding which method to use to load your data. The optimal methodology depends on the volume and frequency of data updates.
1. High Volume, Low Updates
- Full Load: Use in initial loads or for infrequent significant changes
- Batch Load: Works well for large datasets when updates are done periodically.
2. High Volume, High Updates
- Incremental Load: Helps avoid transferring data in cases of high updates
Know the difference between full and incremental load before deciding which one to choose.
3. Low Volume, Low Updates
- Full Load: It is quite efficient if the dataset is small with static data
- Batch Load: Flexibility is allowed as far as scheduling updates are concerned.
4. Low Volume, High Updates:
- Incremental Load: Tracks and applies changes efficiently.
- Stream Load: Applicable to real-time applications with low data volume.
What are Techniques that You Can Use to Load Data?
The data is physically moved to the data warehouse in the process of loading data. It takes place within a “load window”. The tendency is close to real-time updates for data warehouses as warehouses are growing in use for operational applications.
Cloud-based: ETL tools in the cloud are built for speed and scalability and often enable real-time data processing. They also include the ready-made infrastructure and expertise of the vendor, who can advise on best practices for each organization’s unique setup and needs.
Batch processing: ETL tools that work off batch processing move data at the same scheduled time every day or week. It works best for large volumes of data and organizations that don’t necessarily need real-time access to their data.
Open-source: Many open-source ETL tools are pretty cost-effective as their codebase is publicly accessible, modifiable, and shareable. While a good alternative to commercial solutions, these tools can still require customization or hand-coding.
What Challenges Do Users Face When Loading Data?

- Data Transformation and Cleaning: Source data is often messy or inconsistent. Proper transformation and cleaning are essential before loading.
- Solution: Use tools that support robust data transformation workflows, such as Apache Spark or Hevo.
- Schema Evolution: As systems evolve, schema changes can disrupt pipelines.
- Solution: Employ tools that support schema evolution, like Snowflake or Apache Iceberg or tools like Hevo that provide auto schema-mapping.
- Handling Large Data Volumes: Loading terabytes or petabytes of data strains storage and processing capabilities.
- Solution: Leverage compression techniques, data partitioning, and distributed processing.
- Ensuring Data Accuracy: Inaccurate data can lead to faulty analytics and decisions.
- Solution: Implement validation checks at every stage of the ETL process.
Tools to Overcome These Challenges

There are various types of tools available in the market. You can choose the right tool for your organization depending on your use case, budget, and data requirements.
Open Source tools:
- Airbyte
- Apache Kafka
- Pentaho Data Integration
- Singer
Check out our blog to learn more about the best open-source data-loading tools.
Paid tools
- Hevo Data
- Stitch Data
- Google Dataflow
- Informatica Power Center
- Microsoft SSIS
- Fivetran


What Best Practices Should Users Follow for Successful Data Loading?
- Data Profiling: Conduct data profiling to understand data characteristics like data types, distributions, and key values. This helps identify potential issues and plan accordingly.
- Data Transformation: Transform the data into the appropriate format for the target system. Data transformation may involve data type conversions, aggregations, and other transformations.
- Consider CDC: For high-volume, real-time data streams, consider using CDC techniques to efficiently capture and apply changes to the target system.
- Data Validation and Testing: Perform rigorous testing and validate the loaded data in the target system to ensure data accuracy and completeness.
- Detailed Documentation: Maintain comprehensive documentation of the entire process, including data sources, transformations, and any issues encountered.
How can You Seamlessly Load Data Using Hevo?
Hevo’s automated platform makes loading your data a breeze. You can say goodbye to writing long lines of complex codes to load your data and say hello to Hevo’s no-code seamless platform. Hevo lets you:
- Connect to 150+ data sources and integrate data from numerous sources, including databases, SaaS applications, cloud storage, and streaming platforms, with ease.
- Create data pipelines using the intuitive no-code interface, independent of your coding skills.
- Clean, enrich, and transform data right there before loading it into the destination using built-in transformation capabilities
- Capture data in real-time and start replicating to ensure target systems are up-to-date.
- Leverage the cloud-based infrastructure to handle massive data volumes and high-velocity streams easily.
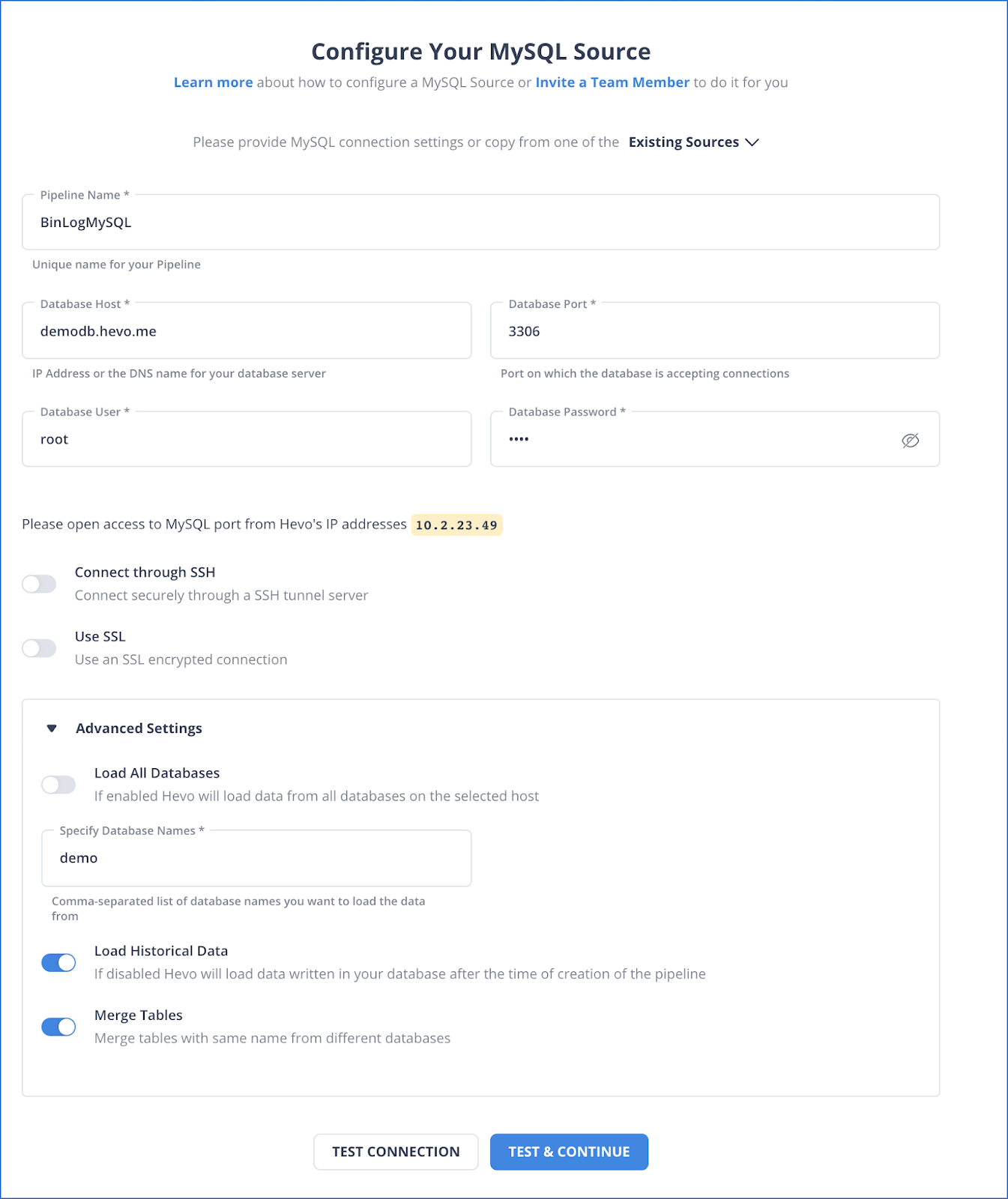
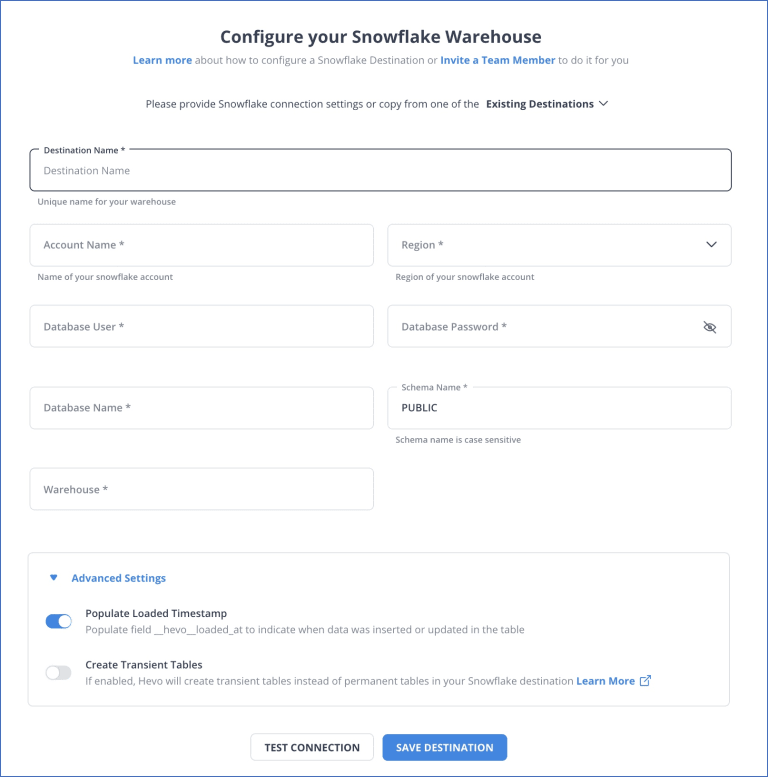
Let’s consider an example to understand how Hevo loads your data from source to destination. Let’s say you want to move data from MySQL to Snowflake; for this, you have to perform two simple steps with Hevo:
Step 1: Configure MySQL as your Source.
Step 2: Configure Snowflake as your destination
Conclusion
This article gives a comprehensive overview of the data-loading component of the ETL process. It also listed open-source& paid data-loading tools that can ease the ETL process.
To make things easier, Hevo comes into the picture. Hevo Data is a No-code Data Pipeline with awesome 150+ pre-built Integrations from which you can choose.
Hevo can help you Integrate your data from numerous sources and load them into a destination to Analyze real-time data with a BI tool such as Tableau. It will make your life easier and data migration hassle-free. It is user-friendly, reliable, and secure. Sign up for a 14-day free trial to experience seamless data loading. the comments section below.
FAQs
1. What is meant by data loading?
Data loading refers to the process of importing or transferring data from a source (like files, databases, or APIs) into a program or system for processing. It’s a crucial step in data preparation and analysis.
2. What is full data load?
A full data load involves transferring the entire dataset from a source to a destination, replacing any existing data. It is often used during initial setups or complete refreshes of a database or system.
3. What are data loading tools?
Data loading tools are software applications designed to automate the transfer of data between systems, such as databases or data warehouses. Examples include Talend, Hevo, and Informatica PowerCenter.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





