

Niklas Lang is the founder and lead author of Data Basecamp, a machine learning blog that aims to offer easy explanations of data science and artificial intelligence. He uses the power of data to find growth opportunities and automate repetitive tasks.
The quality of your data determines how well it supports your business goals within a given context, be it in operations, planning, or decision-making. Low-quality data cannot effectively serve your purpose. Usually, decision-makers rely on data to support their decisions; however, much evidence suggests that poor or uncertain data quality can contribute to ineffective decision-making in practice.
Good data is, therefore, the most valuable asset for any business today, and without good data, you can’t create targeted business intelligence or train machine learning models. The ability to gather and analyze “good” data and come up with accurate conclusions from it is what sets a company apart from the rest and is one of the key necessities for success.
For companies to ensure the long-term quality of their data, it is crucial to assess and manage data quality beyond the usual missing or outdated information since data quality is also affected by many other factors.
A well-defined data quality assessment and management strategy helps businesses improve the accuracy, consistency, and completeness of their data. This enables them to make more informed decisions about how to best manage their information assets, including who can access it, how much it’s worth, and how much time is wasted unnecessarily on reporting errors.
Table of Contents
Assessing Your Data Quality or Its “Worthiness”
Data quality describes the extent to which a data set is suitable for a particular use case. Whenever a data set meets all the requirements to implement a use case, it is said to have a high data quality. However, if the data set has missing or inaccurate values, it is considered low in quality.
The data quality assessment process, therefore, checks the extent to which the specifications are met by a given data set. Following this assessment, for example, an attempt can be made to fill the existing gaps in collaboration with the data publisher.
Why is Data Quality Assessment a Growing Priority?
A data quality assessment only deals with a data set that is used in a specific application. This means that the data is only cleaned and prepared for this purpose. At the same time, it can happen that different teams have to deal with the same data set and that the same steps have to be repeated each time.
Therefore, it makes sense to bundle this process centrally so that know-how is not lost and data quality is checked once. Using this approach, the teams involved can then also acquire a sound knowledge of the company’s data and understand the peculiarities of this information without having to acquire this knowledge separately, which is time-consuming.
In addition, experts in the fields of data science or machine learning are hard to come by or extremely expensive to hire. Therefore, it is important not to waste their time with elaborate data quality checks but rather to provide them with a working environment in which they can begin immediately. An effective data quality management and assessment framework is key to this.
Avoid These Common Problems with Data Quality Management
According to a report by 451 Research, the following are two common reasons for poor data quality management in organizations:
Manual Data Entry
In many systems and companies, it is still normal for employees to enter certain types of data by hand. This can lead to errors, whether intentional or unintentional.
Additionally, irregularities may occur when entering units of measurement that are either written out or abbreviated. Other times, manual data entry may result in duplicate data records if, for example, two employees are involved in the same project. Although to some extent, you can reduce data entry errors by replacing free text fields with drop-down menus, this isn’t a feasible long-term solution.
Error-Prone Data Migration
When transferring data from multiple systems or databases, errors and duplication of records may occur. Often, different databases also have different data schemas that need to be merged. During the conversion of the data format, errors can occur, leading to the loss of valuable information.
Managing Data Quality Has Many Benefits
Data quality management refers to methods aimed at sustainably and permanently increasing data quality so that business analysts and data scientists have targeted access to good data. In addition to improving existing data, this also includes preventive measures in the source systems so that only high-quality data is created in the future. A good data quality management strategy is a component of data governance.
Establishing comprehensive data quality management is a decisive competitive advantage for many companies. By using “clean” data, business processes can be analyzed and improved. In addition, comprehensive data gets obtained for a better understanding of the customer and their feedback on the product.
As a bonus, data quality management offers the advantage of centralizing all data quality efforts and combining know-how. This is drastically different from the past, where data quality assessment and management used to be handled only in individual projects, meaning that it had to be repeated every time a new project was started.
Who Is Responsible for Ensuring Data Quality?
The short and easy answer is everybody!
Every member of a company is in-part producing data and making it available for cross-team use. Whether you are creating new products and maintaining their attributes, storing customer interactions in a CRM tool, or managing customer complaints, all of these actions create data that can be either of good or bad quality.
Thus, everyone in the organization should take responsibility for ensuring good data quality. Along with this, dedicated positions within teams should also pave the way towards higher quality data and lay the appropriate foundations so that the rest of the team members can build on it. The following positions are elemental to this:
Data Scientist
A data scientist tries to generate additional value from data using statistical methods. They try to conceive the right algorithms for incoming raw data to solve an existing business problem. Among many other things, machine learning approaches can also be used in this process, and for accurate predictions, they need good-quality data.
By winnowing through the data, a data scientist can see firsthand the actual state of the data quality and maybe offer statistical methods to improve it. For example, he can fill in missing values with the median or average value of the column.
Data Engineer
A data engineer helps companies cope with the vast volumes and varieties of data generated every day as a result of big data. Their task is to prepare and store structured and unstructured information so that it is readily available for further analysis.
The job of a data engineer is to ensure that the data is delivered correctly from the source systems to the databases. Like in most cases, they have a very substantial role to play here because data quality management also starts at the source. Within these ETL steps, data needs to be cleaned up and transformed, which a data engineer must take care of in order to ensure that all information has the same structure and can be consolidated into one database.
Business Analyst
A business analyst monitors various business processes and checks whether these processes are running satisfactorily or whether there is potential for improvement. The quality of data is a key determinant of these processes.
A business analyst is first employed independently of a specific discipline or department and acts as a link between different departments and stakeholders. So, the business analyst has a similar role to the data scientist in that they spend a lot of their time working directly with the data and managing its quality.
Thus, they are also directly affected by the data quality. In contrast to the data scientist, the business analyst also works closely with the business departments and can thus ensure that they contribute to better data quality by understanding key business requirements and how data helps in achieving those.
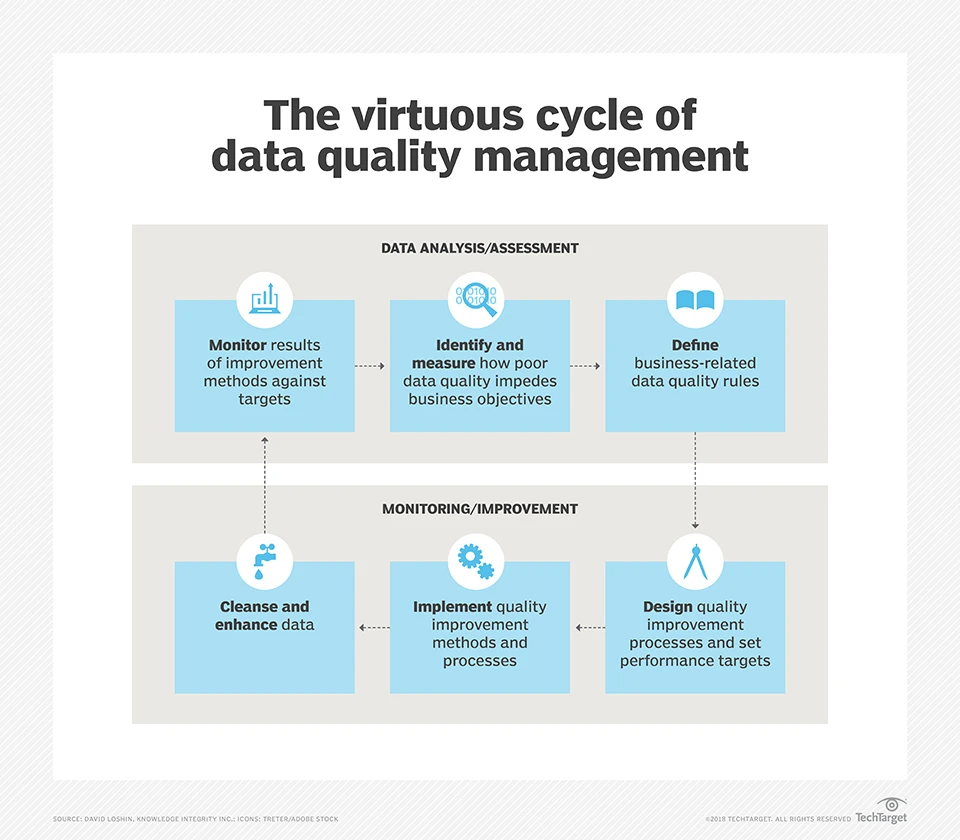
Best Practices for Data Quality Assessment and Management
The following steps can help you set up and run an initial data quality assessment to create a solid base for long-term data quality improvement.
Measure Your Current Data Quality Level
To ensure a sustained level of data quality, it is necessary to agree on certain key metrics within the company and then measure the current status of your data.
You can, for example, decide on a metric based on the number of missing fields in tables or the number of outliers in numerical fields. It is crucial that, within this framework, the measurements be developed and monitored by the department responsible for the data. Only as a team can the data quality be improved.
Start by measuring your current progress in terms of how effectively and positively you can position these figures in the process of making a change. Although there are still no centrally defined processes or fixed metrics for measuring and evaluating your data sets, some measures have become standards and are consulted when examining data quality.
Completeness
The completeness of a data set measures whether all relevant information is available without gaps. During such a test, each empty or missing field is counted, and the ratio of missing fields to all fields is calculated. A high proportion of empty values indicates poor data quality.
For example, if we as a company were to analyze our customers’ locations, we would need a data record with customer numbers and their addresses. This would, in turn, consist of their street name, postal code, and city. For some customers, however, there is no street maintained. These fields are then marked as incomplete.
Validity
The validity of a data set checks whether all fields have a valid value. Among other things, the data type (string, integer, date, etc.) must match the expected value.
For example, in the postal code column, we expect only integers. So, if a value contains letters or has the data type decimal, this value is probably not valid.
Besides the data type, there are other values that can make a statement about validity. For example, if the data type matches, it can still be checked whether the specified minimum or maximum values are undercut or exceeded. A postal code in Germany, for example, consists of five digits. So, if a postal code is specified with six digits, this should be examined more closely again.
Timeliness
When it comes to timeliness, data must be current. Some information is extremely time-critical and thus loses value over time. For example, if you don’t retrieve your competitor’s price information regularly, it loses significance, making it harder for you to make decisions about your own prices.
Consistency
The consistency of data plays a crucial role as well. What counts here is whether the truthfulness of the values is carried across different systems. For example, if two different addresses are maintained for a single customer in two systems, then the data is inconsistent.
Identify the Problem Areas
After creating a common picture of the current situation, it is relatively easy to identify the potential for improvement. Especially at the beginning of data quality management, these can be very diverse. Therefore, you should pick out a few specific points of attack that you want to improve. In this way, successes will become more visible more quickly, and you will not lose focus.
Define Strategies to Increase Data Quality
In many cases, the faulty data originates in specialized departments. For example, product properties can be incorrectly maintained, or complaints can not be documented in sufficient detail.
Therefore, it is important to define strategies together with the department to increase the data quality without creating too much additional work. One should find out if there are possibilities to regulate data entry in order to reduce wrong entries. For example, predefined values, suggestions, or drop-down menus can help. This makes data creation easier and ensures a common format for the data.
Establish and Monitor the Measures
Once you’ve decided on your data quality assessment measures, you can put them into action and test them. After a sufficient testing period, you should check to see if the desired quality improvements have been achieved. It is also important to consider whether the business and data teams using the data are satisfied with the implementation and whether it is now easier for them to maintain quality data.
Final Words
There’s no denying that data quality assessment and management are becoming important priorities for data-savvy companies wanting to work with big data. Data quality is a decisive factor in many fields, including business intelligence, machine learning, decision-making, and regulatory compliance. Developing intelligent models and building meaningful analyses are only possible if you have clean, quality data.
Start small if you are dealing with low-quality data or are just beginning your data journey. Victories don’t happen overnight. Start small, and you will be able to gain expertise and practice good data hygie
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link

