




The dbt tool is used in organizations that have complex business logic behind their data. It is helping data engineers to quickly transform data and support downstream processes with near-real-time data pipelines. It also enables organizations to keep track of changes made to the business logic and makes it easier to track data.
Currently, dbt can be leveraged through dbt Cloud and a Command Line Interface (CLI). The dbt tool consists of a list of commands supporting dbt Cloud and CLI. dbt build and dbt run are the essential commands in dbt that allows data engineers to build and run their dbt models.
This article talks about dbt build vs dbt run.
Table of Contents
What is dbt Build Command?

The dbt build command runs, tests, seeds, and snapshots in a DAG (Directed Acyclic Graph) order for selected resources or the entire project.
The build command creates a single manifest, a file containing representations of the dbt project’s resources like models, seeds, and sources. It also generates a single run results artifact, a file that contains the details of the output of the dbt build command. It contains information about executed models and tests, the time to run the models, test failure rates, and more.
In 2025, Fivetran and dbt Labs announced a merger to create a unified open data infrastructure platform. This merger signals a major shift in how the data transformation ecosystem is evolving, with closer integration between data pipelines and transformation workflows. Understanding dbt build and dbt run is now even more critical as teams prepare for tighter tool interoperability and new bundled data solutions.
Struggling with manual commands to run your dbt models? Hevo Transformer (Powered by dbt Core) simplifies dbt workflows, automates transformations, and streamlines model execution—all in one place.
- One-Click dbt Execution – Run and build models seamlessly.
- Automated dbt Workflows – Eliminate manual effort with smart scheduling.
- Built-in Version Control – Track and collaborate with Git integration.
- Instant Data Previews – Validate transformations before deployment
The basic syntax of the build command:
dbt buildWhat is dbt Run Command?
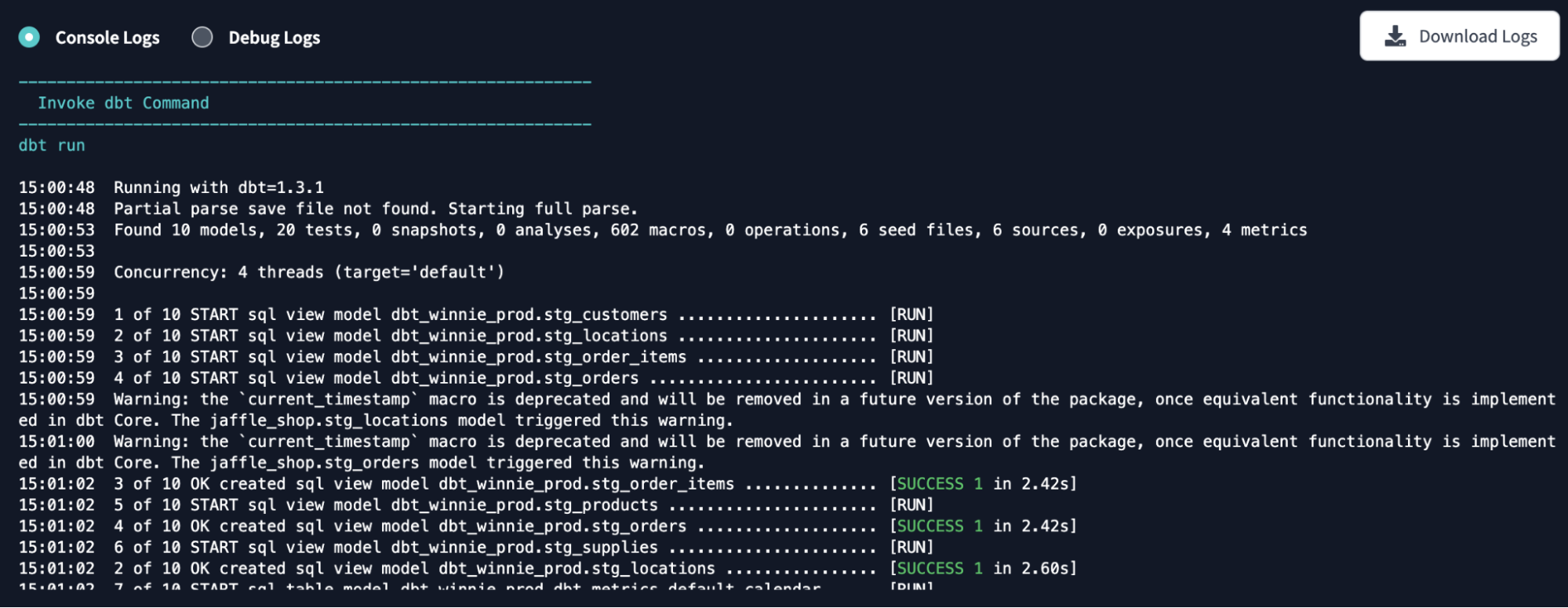
The dbt run command can execute compiled .sql files against the current target database. With this command, dbt can connect to the target database and run the relevant SQL to materialize all data models. In the dbt run, all the models run in the order defined by the dependency graph generated during compilation.
The basic syntax of the run command is:
dbt rundbt Build vs dbt Run: How Do They Differ?
Operating Principle
dbt run is one of the most powerful commands to run models for transforming the data. However, in the production environment, dbt run is avoided. The principle behind dbt run is to first run the models instead of testing them. The preferred production dbt command is to test the source, run models, test (excluding source), and then check for source freshness.
In the dbt build command, tests are a core part of the execution. If the test cases in upstream resources fail during dbt build, it will skip all the execution of the downstream resources entirely. However, you can still handle how dbt build should respond in case of test failures. But, the core principle is to skip downstream resources from getting impacted.
But, with dbt run, the operating principle is to run the models without checking for test cases before executing the models.
Data Quality
If you can slightly compromise data quality, the dbt run works fine for such use cases. However, the dbt build command is optimized to obtain better data quality.
Since dbt run doesn’t test the models, it can lead to processing data incorrectly. You might miss edge cases that could substantially hamper data quality when transformed without proper checks. During data transformation with dbt, you usually add test cases to check for null, missing, and unique values. You might miss validating tests while transforming with the dbt run command.
But, dbt build ensures that your test cases are validated before the transformation occurs in the downstream resources. Therefore, it is vital to understand your business requirements, especially regarding data quality, to choose between the two commands for running the models against the target datasets.
Customizability
This is similar to dbt run and dbt build since they both support flags to filter the resource during execution.
However, with dbt run, especially in production, flags are avoided to transform the data with only a few models. This is because dbt run can modify data without testing the resources. Individually running dbt models with the dbt run command can make changes you might not need. In a large-scale dbt project, debugging those unwanted changes made by dbt run becomes challenging.
As a result, dbt run is usually a stand-alone command in production. It is recommended to run all the models and then handle the errors individually. However, the dbt build command is preferred with flags as it allows you to check and execute resources in modularity.
Apart from flags, node selections in both dbt run and dbt build are almost identical. But, dbt build also supports –resource-type, which is used for the final filter (similar to the usage in the list command). –resource-type limits the dbt resources based on the type, like model or seeds.
With this selection, you can only run dbt build for a particular resource. However, dbt run doesn’t support –-resource-type selection.
Catalog Generation Capability
As the dbt build command generates a manifest file on execution, it is used to populate the docs site and perform state comparison. The manifest file contains the complete representations of the resource properties of the dbt project. The top-level keys to represent resources include nodes, metadata, sources, metrics, macros, child_map, and more.
The manifest file contains all the resources, even if you are running selected models or resources. However, you can still disable capturing all resources during dbt build execution.
On the other hand, the dbt run command is not used for catalog generation. Instead dbt run generates logs that can be used for debugging the code to optimize the transformation.
Execution
dbt run is preferred when there is a change in the schema of the incremental model or if you want to reprocess the logic changes in the models. But, dbt build incorporates test cases before execution, making it the preferred choice to leverage in the production environment.
In contrast, dbt run is a powerful command in the development environment to build the dbt project incrementally. Initially, dbt run was used as a standard in production, but over the years, the popularity of dbt build in production has led the dbt project to now allow you to set dbt build as the default in production.
Here’s a summary of the differences between dbt build vs run:
| Category | dbt Build | dbt Run |
| Operating Principles | Validates tests and then runs the downstream models | Runs prior to testing |
| Data Quality | You obtain the desired data quality | Can have data quality issues |
| Customizability | Has more customization than dbt run | –resource-type customization is missing |
| Execution | Used in production | Avoided in production |
| Catalog | Used in supporting documentation | Doesn’t support documentation |
Check out the detailed blog to compare Hevo vs dbt and Coalesce vs dbt to find the right solution for your data pipeline.
Conclusion
This article discusses the essential differences between the dbt build and dbt run commands. Although both these commands seem the same, as they are often interchangeable, they have significant differences.
The most noticeable difference is data quality requirements. dbt build to ensure you enhance the data quality, while dbt run can lead to data quality issues. Therefore, it is advised to use dbt build in production over dbt run.
To simplify the implementation of data pipelines, you can opt for cloud-based automated ETL tools like Hevo Data, which offers more than 150 plug-and-play integrations.
Saving countless hours of manual data cleaning & standardizing, Hevo Data’s pre-load data transformations get it done in minutes via a simple drag n-drop interface or your custom python scripts. No need to go to your data warehouse for post-load transformations. You can run complex SQL transformations from the comfort of Hevo’s interface and get your data in the final analysis-ready form.
FAQ DBT Build vs DBT Run
What does build do in dbt?
In dbt (data build tool), the dbt build command is a powerful command that runs multiple dbt tasks to help you build and maintain your data models. It is essentially a higher-level command that combines several dbt operations into a single step.
What is dbt run?
The dbt run command in dbt (data build tool) is used to execute your dbt models, which involves building or updating the tables or views defined in your dbt project.
Does dbt build run dbt snapshot?
Yes, the dbt build command does run dbt snapshots, along with other dbt tasks. Specifically, dbt build combines the functionality of several dbt commands into one comprehensive operation, including the execution of snapshots.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



