




 KEY TAKEAWAY
KEY TAKEAWAYData Build Tool (dbt) empowers data analysts and engineers to create, manage, and test data transformations directly in the data warehouse. It simplifies transforming raw data into actionable insights, improving collaboration among data teams, and accelerating data pipeline deployments.
Steps to Get Started with dbt:
- Step 1: Prepare: Ensure SQL + Git basics; pick your warehouse adapter.
- Step 2: Initialize: Create a dbt project; configure profiles/targets.
- Step 3: Build Models: Add models/, use ref() and macros for reuse.
- Step 4: Add Tests: YAML schema tests + custom SQL tests.
- Step 5: Document & Run: Generate docs/lineage; schedule jobs (Cloud) or orchestrate.
Despite all the ELT tools available out there, businesses still struggle with data modeling. Data Build Tool(dbt) is a robust, open-source tool based on SQL that changes how organizations write, test, and deploy data transformations.
We think empowering analysts to own the data transformation pipeline is the only way to build a productive analytics team at scale. dbt makes it easier to do data modeling the right way, and harder to do it the wrong way.
James Densmore, HubSpot, Director of Data Infrastructure
It is specifically designed for data analysts, engineers, and scientists who work with large amounts of data stored in data warehouses and other data storage systems. This article will provide a deep understanding of the Data Build Tool(dbt), explaining what it is, how it works, and why it is becoming increasingly popular among data professionals.
Table of Contents
What is Data Build Tool(dbt)?

dbt is a transformation workflow that allows any business analyst comfortable with SQL to design and implement their own data transformations. By eliminating the dependency on engineering teams for making changes in the pipelines, dbt allows analysts to collaborate on data models and deploy analytics code using software engineering best practices such as modularity, portability, CI/CD, and documentation. With features like version control, you can test your analytics code in development before deploying it to a production environment.
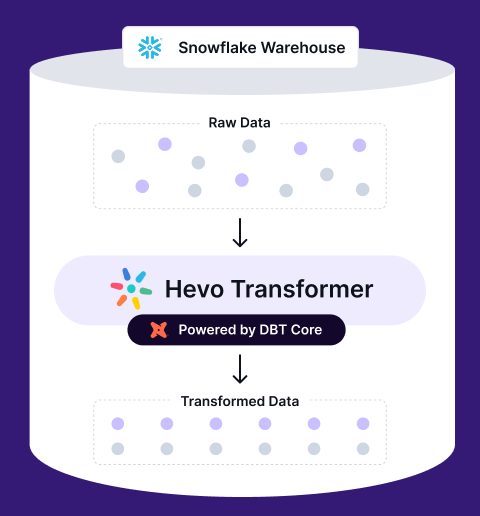
Unlock the full potential of dbt without the complexity! Hevo Transformer streamlines data transformations, automates workflows, and simplifies version control—so you can focus on insights, not infrastructure.
🔹 Instant Data Warehouse Integration – Connect in minutes, auto-fetch tables
🔹 Streamlined dbt Automation – Build, test, and run models with ease
🔹 Built-in Version Control – Collaborate seamlessly with Git integration
🔹 Faster Insights – Preview, transform, and push data instantly
Core Principles of dbt

dbt does data transformation and modeling based on certain core principles, such as:
- Data Warehouse centric: Once the raw data is ingested into the data warehouse, dbt uses its in-database transformation capabilities for heavy computations
- ELT Workflow: dbt does ELT on databases wherein data is first loaded and then transformed.
- SQL-based: It uses SQL as its domain-specific language. This enables direct transformation instead of dependence on externally controlled transformation languages or ELT tools based on GUIs
- Git-based version control: Usually, Git is involved in version control of dbt projects. This enables collaboration using pull requests and branch-based development.
- Data Testing: It enables custom data tests in SQL to be written for specific constraints. Its Schema test ensures data integrity.
- Model Dependencies: dbt models can refer to other models using the ref function. This allows the formation of a DAG (Directed Acyclic Graph) of dependencies, which can be used to run models in the right order.
dbt Architecture

Dbt uses SQL and Jinja2 to transform and model data. It is a command-line tool with a unique architecture having the following components:
- Command Line Interface: This enables you to run commands for transforming, testing, and documentation.
- Projects: It is the foundation of dbt, which consists of models, tests, snapshots, etc.
- Models: These are the SQL files that show transformation logic.
- Tests: dbt supports both built-in and custom testing to ensure data integrity. The below query restricts the bk_source_driver field from model “fact_interaction” to not have a NULL value of more than 5% of its values set.
- Auto-generation: It automatically generates a web-based documentation portal to visualize model metadata and lineage.
- In-database computation: The dbt tool can run SQL directly in the targeted data warehouse.
How does dbt work?

With the advent of ETL technology, where you first load the raw data to your warehouse and then transform, no-code automated tools like Hevo Data completely automated the process. They allow you to simply replicate raw data from multiple sources to your central repository. However, dbt data modeling (transformation) remains a big problem.
Businesses opt to go for a custom code using Airflow. This method is often inaccessible as it is totally written in Python and requires a large infrastructure. Or, they go for GUI(Graphical user interface) modeling with tools like Looker. These tools generally come with huge licensing fees and create a host of maintenance issues. This is where dbt comes in and acts as an orchestration layer on top of your data warehouse. The basic processes involved in dbt are as follows:
- Development: Using simple
SQL SELECTstatements, you can write modular transformations, build tables and views, and run models in order. You can also use Python packages for complex analysis. - Testing and Documentation: As you develop a model, you can first test it before sending it to production. dbt also dynamically generates detailed documentation consisting of validated assumptions, dependency graphs, and dynamic data dictionaries. You can quickly share these with all the stakeholders, promoting more data transparency.
- Deployment with Version Control: Deploy your code by going through the dev, stage, and prod environments. Enjoy Git-enabled version control to return to previous states. You can also have better visibility over your transformation workflows with in-app scheduling, logging, and alerting.
Check out our article on the Fivetran + dbt + Snowflake stack.
How Can I Get Started with dbt?
Before studying about dbt, we recommend the following three prerequisites:
Git: Since dbt Core uses git for all its operations, knowledge of git is necessary. You may take a course on GIT Workflow, GIT Branching, and Collaborative Work. Many great choices are open to you online; take a look and find one you like.
SQL: Because dbt employs SQL as its primary language to accomplish modifications, you must be skilled in SQL SELECT statements. If you don’t have this background, many online courses are available, so look for one that will provide you with the foundation you need to begin learning dbt.
Modeling: Data modeling, like any other data transformation tool, requires a plan. This will be crucial for code reuse, drill-down, and performance optimization. Don’t merely follow your data sources’ models; we advocate translating data into the business’s language and structure. Modeling is vital for structuring your project and achieving long-term success.
How Does dbt Differ From Other Transformation Tools?
There is no single data transformation tool like dbt that does it all. Let’s see how dbt differs from other complementary tools in the market, such as Airflow, Talend, Apache Spark, Hevo, etc.
| Feature | dbt | Apache Spark | Talend | Airflow | Hevo |
| Focus | Data transformation and modeling | Big data processing and analytics | Data integration and transformation | Orchestration of workflows | Data integration, ETL, and Data transformation |
| Data Processing | SQL-based transformations | Distributed computing for large datasets | ETL processes with a graphical interface | Orchestrates tasks, not direct transformation | Real-time data ingestion and transformation |
| Ease of Use | Simple, SQL-centric approach | Requires advanced programming knowledge | User-friendly with visual tools | Needs Python/other code for tasks | No-code interface, easy to use |
| Language | SQL | Scala, Python, Java | Java, SQL, Talend-specific language | Python | No-code with predefined integrations |
| Real-Time Processing | No, batch processing | Yes, it supports real-time data processing | Yes, it supports real-time and batch | Yes, it can be integrated with real-time systems | Yes, real-time data pipelines |
| Scalability | Works well for medium to large datasets | Highly scalable for massive datasets | Scalable for enterprise use | Scalable with proper configuration | Highly scalable, handles large volumes |
| Community Support | Strong open-source community | Large, active community | Strong community and enterprise support | Large open-source community | Excellent community and customer support |
| Deployment | Cloud-based or on-premise | Cloud-based or on-premise | Cloud-based or on-premise | Cloud-based or on-premise | Cloud-based or on-premise |
How to Integrate dbt with the Hevo Workflow
Step 1: Connect the dbt projects
Connect the dbt projects you have created in any Git repository and run the dbt models on your destination data. You can configure dbt projects for destinations such as PostgreSQL, BigQuery, Amazon Redshift, Snowflake, and Databricks.
Step 2: Schedule your DBT project
- Running all the models together
- Running all models individually
- Triggering when any event is loaded to the destination table
Step 3: Integrate dbt project with Hevo
After completing the activity log, integrate your dbt project with Hevo Workflow.
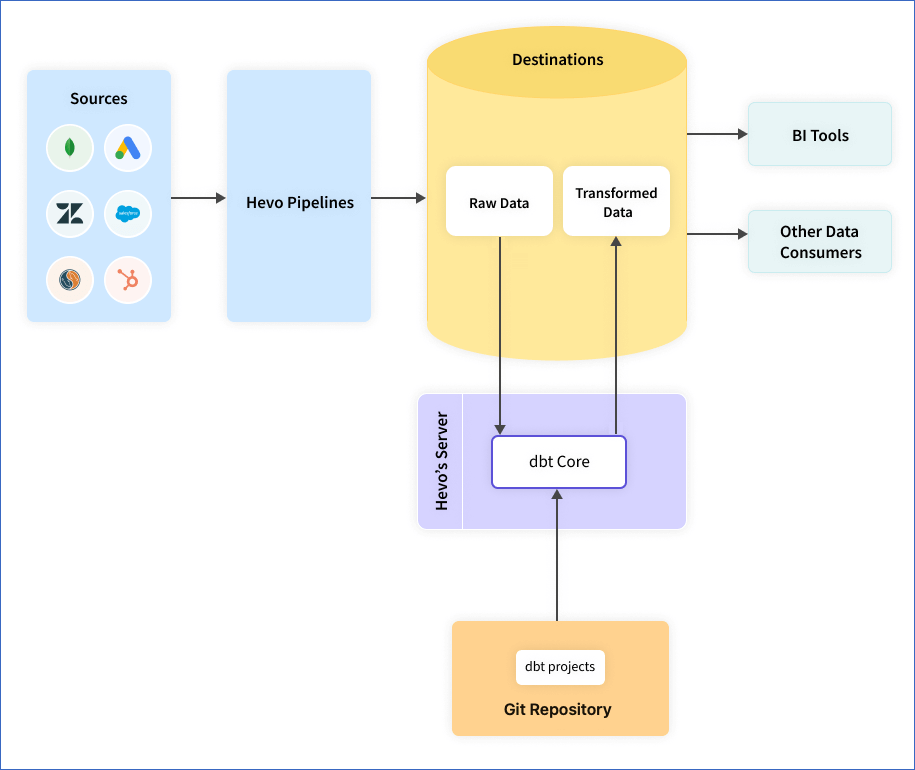
Check out our documentation to learn more about dbt models.
The dbt project consists of resources such as models, seeds, snapshots, docs, etc.
As the modern data stack evolves through mergers like Fivetran and dbt, Hevo remains your open, adaptable alternative — giving you full control over how your data moves and transforms. Experience Hevo for free today!
How Can You Use dbt to Enhance Your Data Pipelines
The data build tool takes complete care of both data modeling and testing. You can easily leverage its features in your ELT pipeline, as it allows you to do the following:
- With dbt, you don’t need much coding experience, as it allows you to perform custom transformations using simple
SQL SELECTstatements. - dbt Cloud offers you continuous integration where you only need to push the components that change rather than the entire repository when there are necessary changes to deploy. The seamless integration with GitHub provides complete automation of your continuous integration pipelines.
- You can write Macros in Jinja as a reusable code that can be referred to multiple times.
- As the documentation gets automatically generated, dbt creates lineage graphs of the data pipeline, showing what the data describes and how it maps to business logic.
- dbt allows you to schedule production refreshes in whatever sequence your business needs.
- You get many prebuilt testing modules in dbt, including unique, not null, referential integrity, and accepted value testing. Carrying out a test becomes completely effortless, as you can reference the test under the same YAML file used for documentation for a given table or schema.
Benefits of the dbt Tool
dbt offers a complete set of eye-catching advantages that make it a powerful data transformation tool:
1. SQL-Based Transformation
- dbt lets you write transformation logic directly in SQL, a language familiar to most data analysts and engineers. It lets you create discrete data models, transforming raw data into target datasets while organizing and materializing frequently used business logic efficiently.
2. Jinja for Enhanced SQL Functionality
- dbt uses Jinja, a lightweight templating language, to extend SQL functionality.
- You can leverage control structures like For Loops to simplify repetitive queries.
- Reusable SQL code can be shared through macros, reducing redundancy.
- With Jinja, dbt effectively turns your project into a SQL programming environment.
3. Ref and Dependency Management
- The ref function in dbt allows you to control the execution order of models, ensuring dependencies are handled seamlessly.
- dbt acts as an orchestration layer on top of your data warehouse, pushing all calculations to the database level. This ensures faster, more secure, and easier maintenance of the transformation process.
4. Data Snapshots
- dbt provides a snapshot feature that captures raw data at specific points in time. This is particularly useful for reconstructing past values and tracking historical changes.
5. Testing and Data Integrity
- dbt simplifies data quality checks.
- Built-in tests for data integrity and validation.
- Custom tests are driven by business logic and are applied directly within YAML configuration files.
- Assertions about test results to improve SQL model accuracy.
6. Automated Scheduling
- dbt automates the scheduling of production refreshes at user-defined intervals, ensuring data is always up-to-date and reliable.
7. Version Control and Documentation
- With Git-enabled version control, dbt allows seamless collaboration and project versioning.
- It auto-generates model documentation that is easy to share with stakeholders and clearly shows dependencies and logic.
8. Community and Open-Source Ecosystem
- dbt is open-source and supported by an extensive library of resources, including installation guides, FAQs, and reference documents.
- Access to dbt packages allows users to leverage prebuilt models and macros to solve common problems efficiently.
Disadvantages of the dbt Tool
Now, let’s check out a few of the limitations of dbt:
- You still need data integration tools to extract and load data from multiple sources to your data warehouse, as dbt only takes care of the transformation part in ELT.
- Compared to tools offering a GUI, dbt is less user-friendly as it is SQL-based.
- You need sufficient technical expertise when you need to make changes to the boilerplate code at the backend.
- To keep the data transformation process as readable as possible in the UI, your data engineers must keep it clean and comprehensible.
dbt and Modern Data Stack: 5 Core Use Cases
dbt has become a popular data transformation tool that fits nicely with the current cloud-based modern data stack. Simplifying the data transformation, testing, and deployment process, dbt offers higher flexibility for all businesses as it offers support for multiple data warehouses:
It can run on top of the above data warehouses and can be effectively used for several business use cases, such as:
- Ensure Data Quality and Integrity: Using dbt, you can run tests to validate data and track its lineage to understand how it has been transformed over time.
- Following the software development best practices, dbt provides a consistent and standardized approach to data transformation and analysis.
- Enhanced Collaboration: dbt enhances collaboration and team communication by allowing analysts and engineers to work together on the same complex data models.
- Scalability: Allowing you to have a scalable data infrastructure, dbt can be used to define data models using SQL and then generate optimized SQL for your data warehouse.
dbt Best Practices
There are a few best practices you can follow for the best data transformation experience:
- While managing your dbt projects in version control, it is recommended that all code changes should be reviewed in a Pull Request before merging into the master. Go for a dev target when running dbt from your command line, and only run against a prod target when executing from a production deployment.
- A well-defined SQL style guide is a good practice for maintaining readability for multiple users in a dbt project.
- Instead of using the direct relation reference, you can use a ref function when selecting from another model.
- As your raw data structure might change over time, it is suggested to reference raw data in only one place to update your models when required easily.
- Renamed the field and tables to naming conventions you wish to use for analytics.
- Instead of having multiple common table expressions(CTEs) for complex projects, you can separate these CTEs into separate models that build on top of each other in dbt.
- You can group your models in directories, allowing you to easily run subsections of your DAG and communicate modeling steps to collaborators.
- Add tests to your projects to ensure the SQL is transforming the data as you expect.
dbt Cloud vs dbt Core
| dbt Core | dbt Cloud |
| Open-Source data transformation | A fully managed dbt experience |
| Open Source: Apache 2.0 | SaaS Managed |
| Interface via the CLI | Full IDE to develop and test your dbt Code |
| Orchestrate your Jobs, Logging, and AlertingIntegrated documentation, User auth/SSO | Orchestrate your Jobs, Logging and AlertingIntegrated documentation, User auth/SSO |
You might have seen two dbt products, i.e., dbt Cloud and dbt Core. But what’s the difference between them? Let’s take a closer look at the differences:
- dbt Core is a free, open-source, command-line tool that enables users to design their data models using SQL. It then converts these models into optimized SQL code that can be executed on data warehouses or other data storage systems.
- In contrast, dbt Cloud is a cloud-based solution that offers additional features and capabilities in addition to those offered by dbt Core. It provides a web interface for managing data models and also includes scheduling options, collaboration tools, and integrations with other data tools.
What dbt isn’t?
dbt is not a data warehouse or a database. Instead, it is a tool that can be combined with a data warehouse to make its functioning easier and manage data. Also, dbt is not a programming language. It uses programming-like syntax to specify and load and transform data in the data warehouse. It is also not a visualization tool. However, it can be used with visualization tools like Tableau or Looker to help you understand and analyze your data.
See how to connect dbt to Snowflake for optimized data management. Explore our detailed guide for straightforward instructions on setting up the integration.
Learn More About:
- dbt Commands
- dbt Incremental Models
- dbt SCD Type 2
- dbt Pricing
- dbt how to setup staging
- dbt Macros
- dbt full refresh
- dbt utils
- dbt defer
- dbt core vs dbt cloud
- dbt cicd
Conclusion
Finally, you now have the complete know-how of dbt. This article provided you with comprehensive information on what is dbt in data engineering, along with its use cases. Based on your business requirements, you can choose whether to opt for dbt as a data transformation solution or go for custom coding. As dbt supports most data warehouses, you can quickly onboard the tool and get started. However, there is still a gap that remains! You need to pull data from all your sources and load them into your data warehouse.
For cases when you rarely need to replicate data, your engineering team can easily do it. Though, for frequent and massive volumes of data transfers from multiple sources, your engineering team would need to constantly monitor and fix any data leaks. Or you can simply hop onto a smooth ride with cloud-based ELT solutions like Hevo Data, which automates the data integration process for you and runs your dbt projects to transform data present in your data warehouse. At this time, the dbt Core™ on Hevo is in BETA.
Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. Please reach out to Hevo Support or your account executive to enable it for your team. Check out the pricing details to understand which plan fulfills all your business needs.
FAQs
What is dbt, and why do teams adopt it?
dbt (Data Build Tool) is a SQL-first framework for transforming data inside your warehouse using models, tests, and documentation. It brings software-engineering rigor, version control, CI/CD, and modular code to analytics. Teams adopt dbt to standardize transformations, improve reliability, and accelerate delivery without building heavy custom pipelines.
How does dbt differ from ETL/ELT tools and orchestrators?
dbt focuses on T (transform) in ELT, compiling SQL and executing it in-database. ETL/ELT platforms handle extract/load (and sometimes GUI transforms), while orchestrators like Airflow schedule multi-system workflows. Many stacks pair Hevo (EL) + dbt (T) + a lightweight scheduler, keeping each layer specialized and maintainable.
Can non-engineers use dbt effectively?
Yes,if they know SQL. dbt’s SQL-first approach, plus Jinja macros, makes modeling accessible to analysts while remaining powerful for engineers. With tests, docs, and lineage built in, teams collaborate in Git and review changes via pull requests—raising quality without steep coding overhead.
What warehouses and workloads fit dbt best?
dbt supports major warehouses (Snowflake, BigQuery, Redshift, Databricks, Postgres, Synapse). It’s ideal for batch/incremental transformations, dimensional models, marts, and semantic layers. For streaming or massive Spark jobs, pair dbt with warehouse-native incremental strategies or complementary big-data frameworks as needed.
What are dbt’s main limitations?
dbt does not extract or load data; you still need an EL tool. It is SQL-centric, so complex non-SQL logic may require macros, Python models (where supported), or external jobs. Finally, good project hygiene (naming, tests, style guides) is essential to keep models readable at scale.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



