




Change Data Capture (CDC) is a well-known software design pattern for a system that monitors and records data changes so that other software can react to them. CDC captures row-level changes in database tables and sends them to a data streaming bus as change events. These change event streams may be read by applications, which can then access the changes in the sequence they occur. As a result, CDC aids in integrating old data storage with new cloud-native, event-driven systems. Today, there are many CDC tools, but Debezium is one of the most popular applications that records every event (insert, update, delete) from the source database and sends it to Kafka using connectors.
Upon a complete walkthrough of this article, you will gain a decent understanding of the steps on how to install and configure the Debezium MySQL connector. Read along!
Table of Contents
Understanding Debezium MySQL Connector
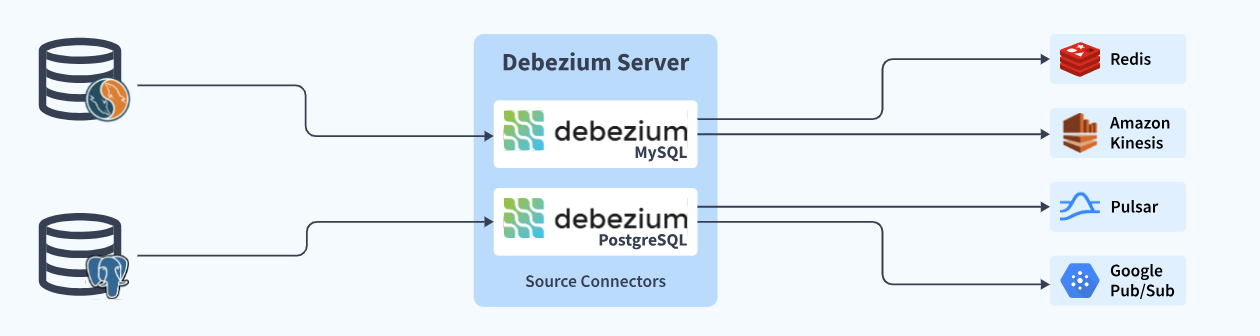
Debezium MySQL Connector is a source connector that can take a snapshot of existing data and track all row-level changes in databases on a MySQL server/cluster. It reads a consistent snapshot of all databases the first time it connects to a MySQL server. In other words, the MySQL connection takes an initial consistent snapshot of each of your databases because MySQL is often set up to remove binlogs after a defined length of time. The MySQL connection reads the binlog from the snapshot’s starting point.
When the snapshot is complete, the connector reads the changes committed to MySQL and creates INSERT, UPDATE, and DELETE events as needed. Each table’s events are stored in their own Kafka topic, where applications and services may readily access them.
The binary log (binlog) in MySQL records all database actions in the order in which they are committed. This includes both modifications to table schemas and changes to table data. The binlog is used by MySQL for replication and recovery.
The MySQL connector also ensures against event failure. The connector records the binlog position with each event as it reads the binlog and creates events. When a connector shuts down (for example, due to communication problems, network difficulties, or crashes), it reads the binlog from where it left off after being resumed. This implies if a snapshotting is not finished when the connector is stopped, a new snapshot will be started when the connector is restarted.
Learn more about Debezium SQL Server Connector.
Want to capture real-time inserts, updates, and deletes from your MySQL database? With Debezium and Hevo, you can build a robust change data capture (CDC) pipeline without the operational overhead.
With Hevo:
✅ Integrate Debezium MySQL connector seamlessly for row-level change tracking
✅ Stream CDC events to your destination (e.g., BigQuery, Snowflake) with zero data loss
✅ Auto-handle schema changes and ensure data consistency across systems
Trusted by 2000+ data professionals, including teams at Playtomic and Postman. Start streaming MySQL changes with Debezium and Hevo today!
Get Started with Hevo for FreeSetting up the Debezium MySQL Connector
Before the Debezium MySQL connector can be used to track changes on a MySQL server, it must be configured to use row-level binary logging and have a database user with the required permissions. If MySQL is set up to utilize global transaction identifiers (GTIDs), the Debezium connector can reconnect more quickly if one of the MySQL servers goes down. GTIDs were introduced in MySQL 5.6.5 and are used to uniquely identify a transaction that takes place on a specific server within a cluster. The use of GTIDs substantially simplifies replication and makes it easy to verify that masters and slaves are in sync.
All INSERT, UPDATE, and DELETE operations from a single table are written to a single Kafka topic using the Debezium MySQL connection. The following is the Kafka topic naming convention:
serverName.databaseName.tableNameThere are some MySQL setup tasks required before you can install and run a Debezium connector:
A) Creating User
A MySQL user account is required for a Debezium MySQL connector. All databases for which the Debezium MySQL connector captures updates must have proper permissions for this MySQL user.
- Create the MySQL user:
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';- Grant the required permissions to the user:
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';- Finalize the user’s permissions:
mysql> FLUSH PRIVILEGES;B) Enabling binlog
For MySQL replication, binary logging must be enabled.
- Check whether the log-bin option is already on:
mysql> SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::"
FROM information_schema.global_variables WHERE variable_name='log_bin';- If it is OFF, configure your MySQL server configuration file with the following properties, which are described below:
server-id = 223344
log_bin = mysql-bin
binlog_format = ROW
binlog_row_image = FULL
expire_logs_days = 10Here,
- server-id: Each server and replication client in MySQL cluster must have a unique server-id value.
- log_bin: Its value is the base name of the binlog file series.
- binlog_format: The binlog-format must be set to ROW or row.
- binlog_row_image: The binlog_row_image must be set to FULL or full.
- expire_logs_days: This indicates the number of days during which the binlog file will be automatically removed. The default value is 0, implying that there will be no automated removal.
- Confirm your changes by checking the binlog status once more:
mysql> SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::"
FROM information_schema.global_variables WHERE variable_name='log_bin';C) Configuring Sessions Timeouts
Your established connection might timeout while the tables are being read when an initial consistent snapshot is taken for big databases. The interactive timeout and wait timeout parameters in your MySQL configuration file can be used to prevent this occurrence.
- Configure interactive_timeout:
mysql> interactive_timeout=<duration-in-seconds>- Configure wait_timeout:
mysql> wait_timeout=<duration-in-seconds>D) Enabling Query Log Events
Enabling the binlog_rows_query_log_events option in the MySQL configuration file lets you see the original SQL statement for each binlog event.
mysql> binlog_rows_query_log_events=ONHere, ON refers to enabled status.
Installing the Debezium MySQL connector
You need to download the JAR, extract it to your Kafka Connect environment, and ensure the plug-in’s parent directory is specified in your Kafka Connect environment to install the Debezium MySQL connector. However, ensure you have Zookeeper, Kafka, and Kafka Connect installed before proceeding. You must also have MySQL Server installed and configured.
- Download the Debezium MySQL Connector plug-in.
- In your Kafka Connect environment, extract the files.
- In Kafka Connect’s plugin.path, add the directory containing the JAR files.
- Configure the connector and add it to your Kafka Connect cluster’s settings.
- Start the Kafka Connect procedure again. This guarantees that the new JARs are recognized.


Configuring the Debezium MySQL connector
The Debezium MySQL connector is typically configured in a .yaml file via the connector’s configuration settings.
- Set the connector’s “name” in the a.yaml file.
- Set the setup parameters for your Debezium MySQL connector that you need.
Adding Connector Configuration
Configure a connector configuration and add it to your Kafka Connect cluster to start using a MySQL connector.
- Construct a Debezium MySQL connector setup.
- To add that connector configuration to your Kafka Connect cluster, use the Kafka Connect REST API.
When the Debezium MySQL connector first starts up, it takes a consistent snapshot of the MySQL databases for which it is configured. After that, the connection generates data change events for row-level operations and streams change event records to Kafka topics.
Gather more info on Debezium MySQL Connector.
Conclusion
In this article, you learned about the need to leverage CDC tools and the basics of Debezium. You also learned that the Debezium MySQL connector monitors the table structure, takes snapshots, converts binlog events to Debezium change events, and keeps track of where those events are stored in Kafka.
Migrating large volumes of data from MySQL to a cloud-based data warehouse is a time-consuming and inefficient operation, but with a data integration tool like Hevo Data, you can do it in no time and with no effort.
Sign up for a 14-day free trial with Hevo and experience seamless MySQL CDC on a no-code platform. Hevo offers plans & pricing for different use cases and business needs; check them out!
FAQ on Debezium MySQL Connector
What is Debezium MySQL?
Debezium MySQL is a connector for Debezium that captures changes (inserts, updates, deletes) from MySQL databases and streams them in real-time to Apache Kafka, enabling change data capture (CDC) for MySQL.
Is Debezium Part of Kafka?
Debezium is not part of Kafka itself but integrates with Kafka through Kafka Connect, providing CDC capabilities and streaming changes to Kafka topics.
Why Do We Use Debezium?
We use Debezium to enable real-time data streaming and change data capture from databases, allowing for efficient data synchronization, replication, and integration with other systems.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



