

When you want the data to be continuously available for use and processing, periodic data capture and movement are not useful, and that’s when you need real-time data sync between systems. That can be accomplished with the help of ‘DynamoDB Streams’ to set up a data streaming pipeline.
This article is all about how you can sync the data in real-time using DynamoDB Streams. You will understand the entire infrastructure that is required to set up the sync between source and destination. You will go through the process step-by-step with examples.
Let’s take a look at this in detail.
Table of Contents
What are DynamoDB Streams?
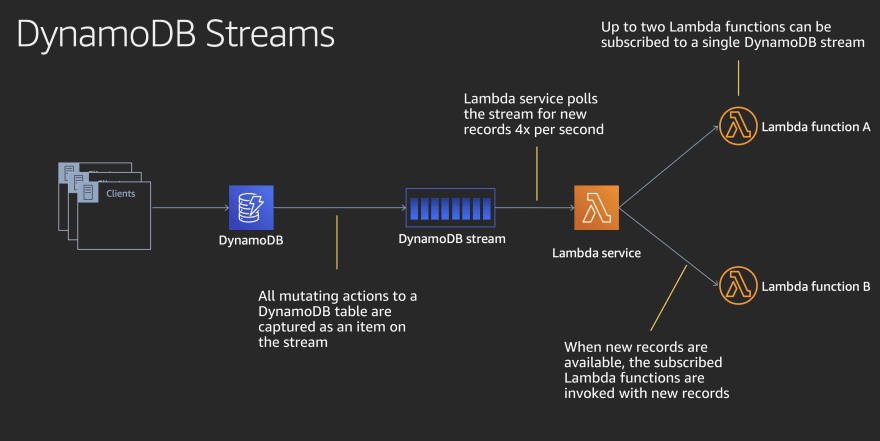
DynamoDB database system originated from the principles of Dynamo, a progenitor of NoSQL, and introduces the power of the cloud to the NoSQL database world. It falls under non-relational databases.
The streams are a feature of DynamoDB that emits events when record modifications occur on a DynamoDB table. The events can be of any type -insert, update, or remove and carry the content of the rows being modified.
You can perform the customization on the streams, let’s say you want to see the record before event and after the event so the change in the data is identifiable. The order of events is in sequential order as the modifications happen.
Hevo can be your go-to tool if you’re looking for Data Replication from 150+ Data Sources (including 60+ Free Data Sources) into Amazon Redshift, Snowflake, and many other databases and warehouse systems. Hevo supports Real-time streaming. To further streamline and prepare your data for analysis, you can process and enrich Raw Granular Data using Hevo’s robust & built-in Transformation Layer without writing a single line of code!
With Hevo in place, you can reduce your Data Extraction, Cleaning, Preparation, and Enrichment time & effort by many folds! In addition, Hevo’s native integration with BI & Analytics Tools such as Tableau will empower you to mine your replicated data and easily employ Predictive Analytics to get actionable insights. With Hevo as one of the DynamoDB ETL tools replication of data becomes easier.
Get Started with Hevo for FreeWhat are the Benefits Of DynamoDB Streams?
Let’s look at some benefits of DynamoDB Streams:
- Well suited for distributed systems’ infrastructure.
- Faster and more efficient processing.
- Better availability and scalability.
- Enhanced performance.
What are the Use Cases of DynamoDB Streams?
DynamoDB Streams have a wide range of applications. Here are some examples of how DynamoDB streams may be used.
- Invalidate a cache immediately.
- Update the materialized view to reflect the write-side modifications.
- Update a search index in real-time.
- Modify and update the dashboard in real time.
- Perform on-the-fly aggregations and store the results in a different table.
- Use the Transactional Outbox pattern in Microservices.
Example Use Case: Aggregating data into another table
Let’s imagine you have a lot of data and want to keep the count of tasks for each list in the ‘todoTaskCount‘ table for caching purposes. When a new task is added to the list, this table must be updated so that the application user may view the updated task count. The following is the table schema:
| Partition Key | Attribute 1 |
|---|---|
| ListId | TaskCount |
| 1 | 2 |
| 1 | 2 |
Every time there is a change in the `todoListTask`table, a stream event is generated and handled by Lambda to update the aggregate table. The system architecture looks like this:

To begin, you’ll make a new table called ‘todoTaskCount.’ Then, on this ‘todoListTask‘ table, you will enable DynamoDB Streams with only new photos (because you don’t need to see the old values). Finally, you will construct the Lambda function and assign the appropriate IAM roles to it.
Prerequisites
It would be helpful if you have an idea about the following areas before you want to learn the real-time data sync using DynamoDB Streams.
- DynamoDB as a source system.
- AWS Lambda function.
- Any other system like CloudWatch, ElasticSearch, RDS, MySQL, or DynamDB itself as a destination. In this article, you will consider CloudWatch as a destination system where the data will be synced.
- Knowledge about Node.js.
- You will use CLI to run commands.
How to Set Up Real-Time Data Sync?
You will quickly take a look at how the data will flow along with the systems involved.
Whenever the CRUD operation happens on the DynamoDB table, the change is recorded in the form of events in the DynamoDB Stream. The Lambda function then connects to the other system and sends the data accordingly to that destination system.
Below are the high-level details of the setup without many technicalities to understand it at a glance.
- Enable the DynamoDB Stream in the DynamoDB Console.
- Read change events that are occurring on the table in real time. Every time an insertion happens, you can get an event.
- Hook up a Lambda to DynamDB Stream. Every time an event occurs, you have a Lamda that gets involved.
- Lamda’s arguments are the content of the change that occurred.
- Replicate the content in the data store. (The other system could be CloudWatch, DynamoDB, SNS, Kinesis, etc, depending on the use case).
Now let’s dig into all of these steps by step with pieces of code that you can understand in detail.
- Step 1: Create IAM Role
- Step 2: Create AWS Lambda Function
- Step 3: Run Lambda Create-Function
- Step 4: Create DynamoDB Table
- Step 5: Enable DynamoDB Streams
- Step 6: Event Mapping Of Lambda Function
- Step 7: Set CRUD Operations
- Step 8: Sync Data In Real-Time
Step 1: Create IAM Role
In the AWS management console, you will need an IAM role to execute the Lambda function. Let’s create an IAM role first for the AWS Lambda entity.
IAM role for entity AWS Lambda:
role name: lambda-dynamodb-role
policy with permission: AWSLambdaDynamoDBExecutionRole.

Step 2: Create AWS Lambda Function
Now you will create an AWS Lambda function for which you will use Node.js to write code. The Node.js is one of the languages supported in the AWS Lambda function.
Please note that you can use any other language supported in the Lambda function.
Let’s create index.js with the following piece of code and compress it using any compress utility. The file can be compressed with any tool that you may have or want to use.
console.log('Loading function');
exports.handler = function(event, context, callback) {
console.log(JSON.stringify(event, null, 2));
event.Records.forEach(function(record) {
console.log(record.eventID);
console.log(record.eventName);
console.log('DynamoDB Record: %j', record.dynamodb);
});
callback(null, "message");
};You will do it using the java jar command. Here is the command that you will use in the CLI tool:
jar -cfM function.zip index.jsIf you look at the command closely, you have mentioned which file needs to be compressed and what would be the name of the compressed file.

Step 3: Run Lambda Create-Function
You will now run Lambda create-function CLI command with IAM role ARN:
aws lambda create-function --function-name ProcessDynamoDBRecords --zip-file fileb://function.zip --handler index.handler --runtime nodejs8.10 --role arn:aws:iam::392821317968:role/lambda-dynamodb-roleARN needs to be taken from the role that you created in the AWS console.

Once you run the command, the lambda function will be created, and you need to test it by invoking the function. Here is the command for the same:
aws lambda invoke --function-name ProcessDynamoDBRecords --payload file://input.txt outputfile.txtThis command will take the sample DynamoDB data, which is there in the input.txt. The same will be passed to the lambda function, which will then write the output in the outputfile.txt as per the input file and function execution.
This step is just for testing to ensure that your function is working as expected. It has no relation to the real-time data sync that you are covering in this blog.
Step 4: Create DynamoDB Table
Next step is to create a DynamoDB table with following details:
Table name: lambda-dynamodb-stream
Primary key: id (number)

Step 5: Enable DynamoDB Streams
Now enable the DynamoDB Stream as shown below:

Once the stream is enabled by clicking on the “Manage Stream” button, copy the Latest Stream ARN as shown in the screenshot:

Step 6: Event Mapping Of Lambda Function
The Latest Stream ARN copied in the previous step will be used to create event mapping of the Lambda function with the stream.
aws lambda create-event-source-mapping --function-name ProcessDynamoDBRecords --batch-size 100 --starting-position LATEST --event-source arn:aws:dynamodb:ap-south-1:392821317968:table/lambda-dynamodb-stream/stream/2019-06-29T12:39:47.680This means that if any event happens, it will cause the function to be triggered, to execute which can then sync the data to the destination system.
Verify the list of event mapping by executing the following commands.
aws lambda list-event-source-mappings
aws lambda list-event-source-mappings --function-name ProcessDynamoDBRecordsStep 7: Set CRUD Operations
Now you have set up everything. You need to try CRUD operations on the DynamoDB table.
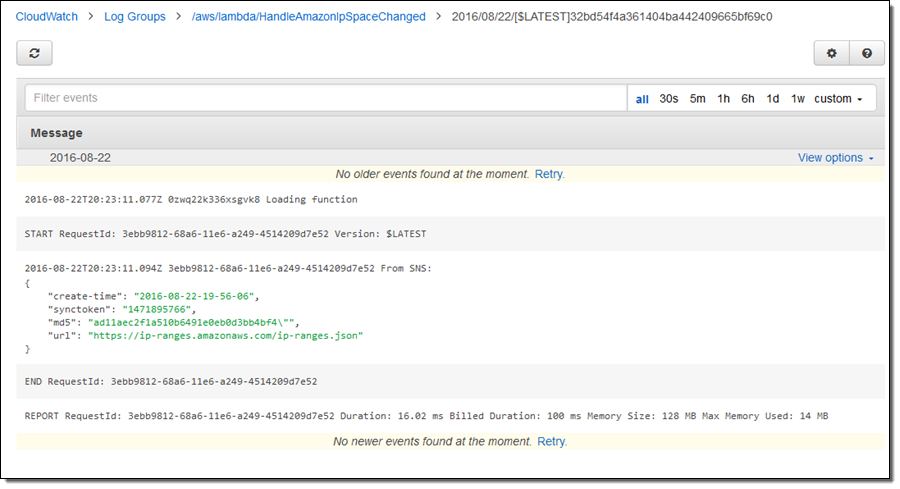
See whether the data logs are getting captured in the AWS CloudWatch dashboard, which is made available for monitoring and insights.
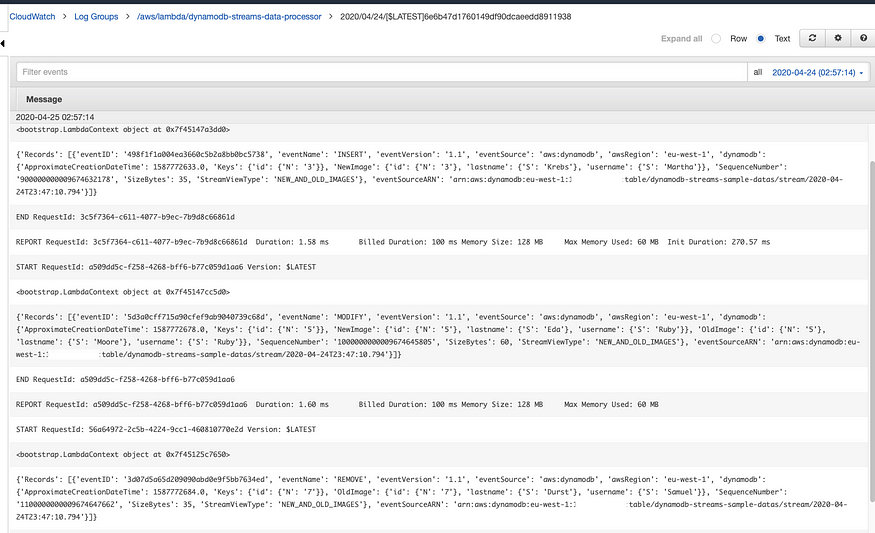
Step 8: Sync Data In Real-Time
You will see the data inserted into the table on DynamoDB is being synced in real-time in the CloudWatch logs as shown in the screenshot below:
What is the Anatomy of DynamoDB Streams?
Shards
Shards make up the Stream. Each Shard is made up of Records, each of which corresponds to a single data update in the stream’s table.
AWS creates and deletes shards automatically. Shards can also split into several shards on their own, and this happens without human intervention.
Contents of a Stream Record
Furthermore, while constructing a stream, you have limited options for what data should be sent to it. Among the possibilities are:
- OLD_IMAGE: Stream records will have an item that hasn’t been changed.
- NEW_IMAGE: After an item has been updated, stream records will contain it.
- NEW_AND_OLD_IMAGES: Stream records will include snapshots taken before and after the change.
- KEYS_ONLY: The name says it all.
What is DynamoDB Lambda Trigger?
Due to its event-driven nature, DynamoDB Streams pairs nicely with AWS Lambda. The scale is in proportion to the amount of data pushed through the stream, and streams are only used when data needs to be processed.
To subscribe your Lambda function to DynamoDB streams in Serverless Framework, use the following syntax:
functions:
compute:
handler: handler.compute
events:
- stream: arn:aws:dynamodb:region:XXXXXX:table/foo/stream/1970-01-01T00:00:00.000
- stream:
type: dynamodb
arn:
Fn::GetAtt: [MyDynamoDbTable, StreamArn]
- stream:
type: dynamodb
arn:
Fn::ImportValue: MyExportedDynamoDbStreamArnId
The following is an example of an event that will be provided to your Lambda function:
[
{
"eventID": "fe981bbed304aaa4e666c0ecdc2f6666",
"eventName": "MODIFY",
"eventVersion": "1.1",
"eventSource": "aws:dynamodb",
"awsRegion": "us-east-1",
"dynamodb": {
"ApproximateCreationDateTime": 1576516897,
"Keys": {
"sk": {
"S": "sk"
},
"pk": {
"S": "pk"
}
},
"NewImage": {
"sk": {
"S": "sk"
},
"pk": {
"S": "pk"
},
"List": {
"L": [
{
"S": "FirstString"
},
{
"S": "SecondString"
}
]
},
"Map": {
"M": {
"Name": {
"S": "Rafal"
},
"Age": {
"N": "30"
}
}
},
"IntegerNumber": {
"N": "223344"
},
"String": {
"S": "Lorem Ipsum"
},
"StringSet": {
"SS": ["Test1", "Test2"]
}
},
"SequenceNumber": "125319600000000013310543218",
"SizeBytes": 200,
"StreamViewType": "NEW_IMAGE"
},
"eventSourceARN": "arn:aws:dynamodb:us-east-1:1234567890:table/my-test-table/stream/2021-12-02T00:00:00.000"
}
]There are a few key elements to remember about this event:
- INSERT, MODIFY, or REMOVE are the three possible values for the eventName property.
- The main key of the record that was edited by dynamodb is stored in the dynamodb.Keys property.
- The new values of the record that were updated are stored in the NewImage attribute. It’s important to note that this data is in DynamoDB JSON format rather than regular JSON. To convert it to normal JSON, use a tool like Jeremy Daly’s dynamodb-streams-processor.

How is DynamoDB Streams better than Kinesis Streams?
Think of real-time analytics with Apache Flink when you hear the term “data analytics.” Video streams are simple to understand because their applications revolve around video processing and machine learning. In contrast to Kinesis, DynamoDB Streams creates a log of changes made, which can then be used to activate other services.
What are the Best Practices for DynamoDB Streams?
- Be aware of the solution’s eventual consistency. The events generated by DynamoDB Streams are near-real-time but not real-time. The time of the event and the time of the event delivery will be separated by a little amount of time.
- Be careful of the limitations: events in the stream are only kept for 24 hours, and only two processes can read from a single stream shard at the same time.
- Use one Lambda function per DynamoDB Stream to ensure the optimal separation of responsibilities. It will assist you in keeping IAM permissions to a minimum.
- Deal with failures. Wrap the entire processing mechanism in a try/catch clause, save unsuccessful events in a DLQ (Dead Letter Queue), and try again later.
- Across regions, standardize the settings and indexes used in Global tables (e.g., TTL, local, or global secondary index; provisioned throughput).
- Since TTL does not happen in real-time, use a ‘expires’ table property to filter for expired objects.
Conclusion
With the above benefits, the DynamoDB Streams stand out with efficiency and performance. However, one needs to write custom code to manage the data changes and deal with keeping the data warehousing engines in sync wherever there are changes in business requirements. So, if you don’t want to deal with the hassle of setting up code, try Hevo. Explore different DynamoDB CDC methods to track real-time changes.
Hevo is a No-code Data Pipeline. It can migrate the data from DynamoDB to your desired data warehouse in minutes. It offers hassle-free data integration from 150+ data sources.
Explore Hevo’s 14-day free trial and see the difference! You can also have a look at the pricing that will help you choose the right plan for your business needs!
Let us know about your experience with DynamoDB Streams in the comment section below.
FAQ on DynamoDB Streams
How to sync data in DynamoDB?
To sync data in DynamoDB:
– Use DynamoDB Streams to capture changes.
– Implement a process to read and apply these changes to another data store or system.
Is DynamoDB synchronous?
No, DynamoDB is not synchronous by default. It uses eventually consistent reads and supports strongly consistent reads, but these options are chosen by the user when making requests.
Is DynamoDB automatically replicated?
Yes, DynamoDB automatically replicates data across multiple Availability Zones within a region to provide high availability and fault tolerance.
How long does data stay in DynamoDB?
In DynamoDB, data remains stored indefinitely until explicitly deleted by the application or by using automated data management features like Time to Live (TTL) settings.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





