

Unlock the full potential of your Elasticsearch data by integrating it seamlessly with Redshift. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Are you trying to connect Elasticsearch to Redshift? Have you looked all over the internet to find a solution for it? If yes, then this blog will answer all your queries. Elasticsearch is a modern analytics and search engine, while Redshift is a fully managed data warehouse by Amazon. Loading your data from Elasticsearch to Redshift will help you to take the data-driven solution. In this blog, you will learn how to connect Elasticsearch to Redshift using two different approaches. You will also learn about the limitations of using the custom method.
Table of Contents
Introduction to Elasticsearch

Elasticsearch is an open-source, distributed, search and analytics engine for all types of available data, such as numerical, textual, structured, etc. Elasticsearch was developed on Apache Lucene in 2010. It is well-known for its REST APIs, speed, scalability, distributed nature, etc. Elasticsearch is the central component of Elastic Stack, commonly known as ELK Stack (Elasticsearch, Logstask, Kibana). Elasticsearch is based on documents and is widely used in single-page applications. It uses indexing for running complex queries. It forms a collection of related documents where each document correlates with a set of keys and values.
Introduction to Amazon Redshift

Amazon Redshift is a fully managed, cloud-based data warehouse. It is fast, cost-effective, and scalable. Its basic architecture includes nodes and clusters. Nodes are a collection of computing resources, and these nodes organize, to form clusters. Each cluster contains at least one node, and one or more compute nodes. It is a column-oriented database, designed to connect to various sources, such as BI tools, databases, etc., and making data available in real-time. As it is based on PostgreSQL, you can use ODBC and JDBC to connect to third-party applications.
Elasticsearch and Redshift are two different data storage solutions as both of them have different structures. The process of loading data from Elasticsearch to Redshift is difficult because of their different structures. In this blog, you will learn about two different approaches to load data from Elasticsearch to Redshift.
Get Started with Hevo for FreeMethod 1: Elasticsearch to Redshift Using Hevo Data

Hevo is a No-code Data Pipeline. It supports pre-built data integrations from 100+ data sources, including Elasticsearch. Hevo offers a fully managed solution for your data migration process. It will automate your data flow in minutes without writing any line of code. Its fault-tolerant architecture makes sure that your data is secure and consistent. Hevo provides you with a truly efficient and fully automated solution to manage data in real-time and always have analysis-ready data at Redshift.
The steps to load data from Elasticsearch to Redshift using Hevo Data are as follow:
Step 1: Authenticate and connect Elasticsearch as your data source.
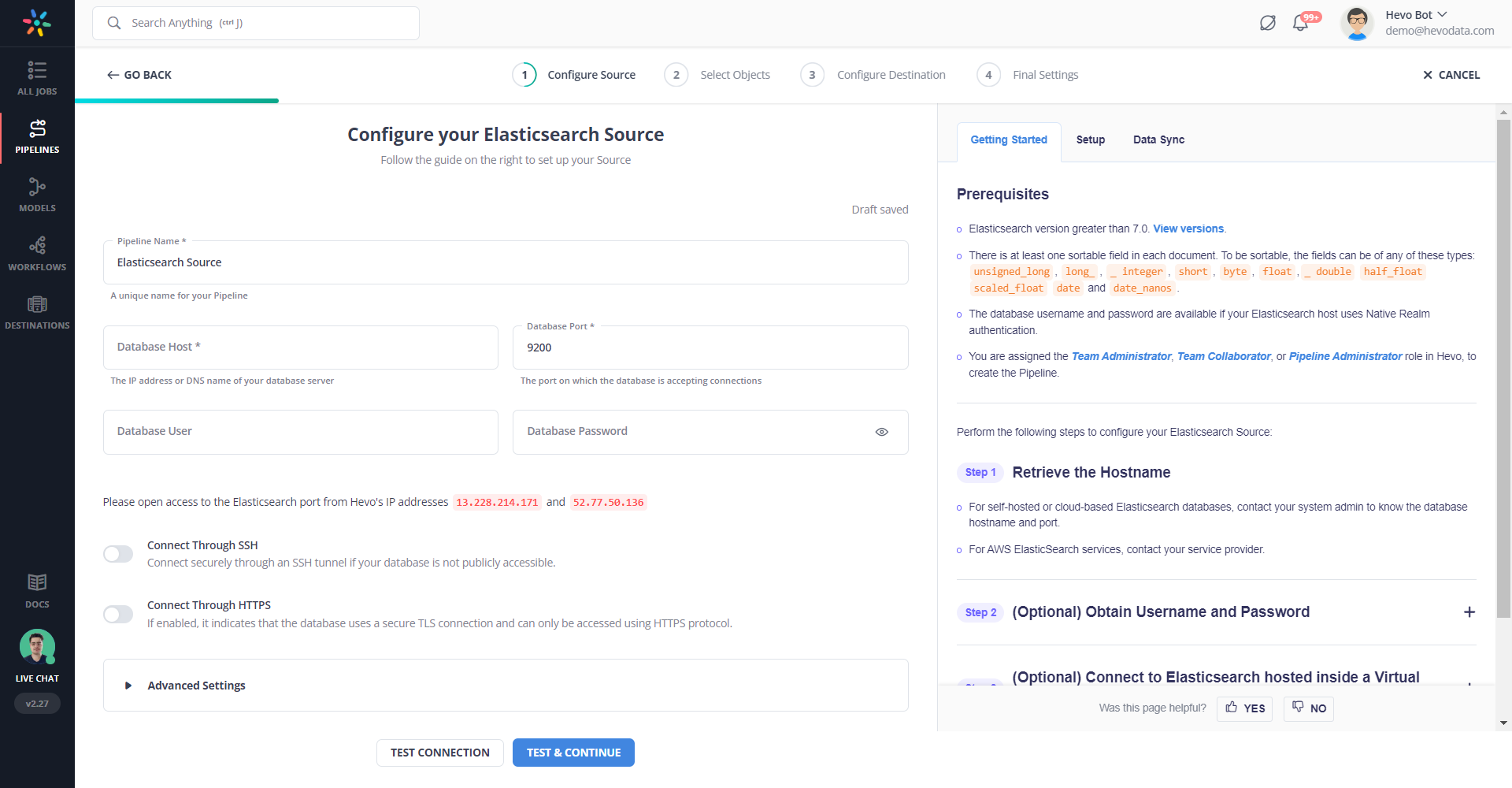
Step 2: Connect the Amazon Redshift as a destination to load your data.

Let’s look at some salient features of Hevo:
- Fully Managed: It requires no management and maintenance as Hevo is a fully automated platform.
- Data Transformation: It provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Real-Time: Hevo offers real-time data migration. So, your data is always ready for analysis.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Live Monitoring: Advanced monitoring gives you a one-stop view to watch all the activities that occur within pipelines.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Explore more about Hevo by signing up for a 14-day free trial today.
Method 2: Elasticsearch to Redshift Using S3
Loading data from Elasticsearch to Redshift is extremely difficult as they have a different structure. With the help of Amazon S3, you can load the data from Elasticsearch to S3 and then, from S3 to Redshift using a COPY command.
Steps to Load Data from Elasticsearch to Redshift Using S3
The following steps will guide you through this process:
Step 1: Load Data from Elasticsearch to S3
Step 2: Load Data from S3 to Redshift
Let’s discuss them in detail.
Step 1: Load Data from Elasticsearch to S3
You will use Logstash for loading data from Elasticsearch to S3. Logstash is a core element of the ELK stack. It is a server-side pipeline that can ingest data from various sources, process them and then deliver it to several destinations. With the help of some adjustments in the configuration parameters, you can export your data from an elastic index to a CSV or JSON. The latest version of Logstash includes S3 plugins that allow you to export data to S3 without any intermediate storage.
You need to install the Logstash plugin for Elasticsearch and S3 as it works on the data access and delivery plugin.
- Use the following command for installing the Logstash Elasticsearch plugin.
logstash-plugin install logstash-input-elasticsearch- Use the following command for installing the Logstash S3 plugin.
logstash-plugin install logstash-output-s3- Use the following configuration for Logstash execution and name it as ‘es_to_s3.conf’.
input {
elasticsearch {
hosts => "elastic_search_host"
index => "source_index_name"
query => '
{
"query": {
"match_all": {}
}
}
'
}
}
output {
s3{
access_key_id => "aws_access_key"
secret_access_key => "aws_secret_key"
bucket => "bucket_name"
}
}
You need to replace ‘elastic_search_host’ with the URL of your source Elasticsearch instance. The index key needs to have the index name as the value. The above query will try to match every document present in the index.
- Use the following command to execute the configuration file. This command will generate a JSON output that matches the query provided in the S3 location.
logstash -f es_to_s3.confVarious parameters can be adjusted in the S3 configuration to control variables. You can also refer to the detailed guide about the configuration parameters here.
Step 2: Load Data from S3 to Redshift
To load data from S3 to Redshift, you can use Redshift’s COPY command where S3 will act as a source to perform bulk data load. For the COPY command, you can use CSV, JSON, or ARVO as the source format. It is assumed that the target table is already created. The following COPY command loads a JSON file, created in the last step, from S3 to Redshift. You can read more about the COPY command from here.
copy <table_name> from 's3://<bucket_name>/<manifest_file>'
iam_role 'arn:aws:iam::<aws-account-id>:role/<role-name>'
region 'us-east-2';Voila! You have successfully loaded data from Elasticsearch to Redshift using S3.
Limitations of Using S3
Even though the above method is the simplest method to load data from Elasticsearch to Redshift without any external tool. It has the following limitations:
- This approach doesn’t support the real-time replication of data. You need to periodically send data from Elasticsearch to Redshift.
- The implicit data conversion in step 2 can cause data corruption if it is done without proper planning.
- It is a resource-intensive process, and it can hog the cluster depending upon the volume of data and the number of indexes that need to be copied.

Use Cases for Migrating your Elasticsearch Data to Redshift
- Data Warehousing for Business Intelligence: Elasticsearch excels at handling real-time search and analysis, but for in-depth business intelligence (BI) reporting, transferring data to Redshift helps centralize the data for querying.
- Historical Data Storage and Archiving: Elasticsearch is optimized for real-time data and might not be ideal for long-term data storage due to high costs or performance degradation. Transferring data to Redshift helps with archiving.
- Complex Analytics and Machine Learning: Elasticsearch supports basic analytics but lacks the deep querying capabilities and machine learning integration that Redshift offers.
- Batch Reporting and Data Summarization: Elasticsearch is often used for real-time search, but Redshift is better suited for batch reporting and summarizing large datasets.
Conclusion
In this blog, you have learned about Elasticsearch and Amazon Redshift in detail. You also learned about the two different ways to connect Elasticsearch to Redshift. If you want to load data from Elasticsearch to Redshift without using any external tool, you can use method 1. But, if you are looking for a fully automated real-time solution, then try Hevo
Hevo is a No-code Data Pipeline. It supports pre-built integration from 100+ data sources at a reasonable price. Hevo will completely automate your data flow from Elasticsearch to Redshift in real-time.
SIGN UP HERE FOR A 14-DAY FREE TRIALFrequently Asked Questions
1. How do I connect Redshift to Elasticsearch?
You can connect Redshift to Elasticsearch by exporting Redshift data to Amazon S3 and then using AWS Lambda or Amazon Glue to transfer the data to Elasticsearch.
2. How do I transfer data to Redshift?
Data can be transferred to Redshift using:
-COPY command from S3, DynamoDB, or other data sources.
-AWS Glue or AWS Data Pipeline for ETL processes.
-JDBC/ODBC connections for data loading via third-party tools.
3. How do I push data to AWS redshift?
You can push data to Redshift using the COPY command from Amazon S3, SQL Workbench for manual uploads, or ETL tools like AWS Glue, Hevo, or Informatica.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




