




Do you want to transfer your Elasticsearch data to Google BigQuery? Are you finding it challenging to connect Elasticsearch to BigQuery? If yes, then you’ve landed at the right place! This article will answer all your queries & relieve you of the stress of finding a truly efficient solution. Follow this step-by-step guide to master the skill of efficiently transferring your data to Google BigQuery from Elasticsearch.
It will help you take charge in a hassle-free way without compromising efficiency. This article aims at making the data export process as smooth as possible.
Upon a complete walkthrough of the content, you will be able to successfully set up a connection between Elasticsearch & Google BigQuery to seamlessly transfer data to Google BigQuery for a fruitful analysis in real-time. It will further help you build a customized ETL pipeline for your organization. Through this article, you will get a deep understanding of the tools and techniques, thus will help you hone your skills further.
Table of Contents
Overview of Elasticsearch
Elasticsearch is a distributed, open-source search and analytics engine built on Apache Lucene and developed in Java. At its core, Elasticsearch is a server that can process JSON requests & returns JSON data.
Elasticsearch allows you to store, search, and analyze huge volumes of data quickly, in real-time, and also returns answers in milliseconds.
Facing challenges migrating your data from Elasticsearch to BigQuery? Migrating your data can become seamless with Hevo’s no-code intuitive platform. With Hevo, you can:
- Automate Data Extraction: Effortlessly pull data from Elasticsearch(and other 60+ free sources).
- Transform Data effortlessly: Use Hevo’s drag-and-drop feature to transform data with just a few clicks.
- Seamless Data Loading: Quickly load your transformed data into your desired destinations, such as BigQuery.
Try Hevo and join a growing community of 2000+ data professionals who rely on us for seamless and efficient migrations.
Get Started with Hevo for FreePrimary Use Cases of Elasticsearch
- Infrastructure metrics & container monitoring
- Application Search
- Website Search
- Enterprise Search
- Logging & Log Analytics
- Security Analytics
- Business Analytics
Overview of BigQuery
BigQuery is a cloud-based data warehouse offered by Google under the Google Cloud Platform. BigQuery is a fully managed service that provides a scalable data warehouse architecture to execute SQL queries on massive data in near real-time.
It uses SQL as the programming language to perform powerful analytics and derive practical information from data.
Key Features of BigQuery
- Fault Tolerance: BigQuery offers replication that replicates data across multiple zones or multiple regions. It ensures consistent data availability when the region/zones go down.
- Scalable Architecture: BigQuery offers a petabyte scalable architecture, and is straightforward to scale as per needs.
- Faster Processing: BigQuery can execute SQL queries over petabytes of data in seconds. You can run analysis over millions of rows without worrying about scalability.
- Security: BigQuery provides the safety of sensitive data when data is in in-flight as well as at rest. The tables and the data are compressed and encrypted to ensure the utmost security.
- Real-Time Data Ingestion: BigQuery can perform real-time data analysis, thereby making it famous across all the IoT and Transaction platforms.
Method 1: Using Hevo Data, a No-code Data Pipeline
Step 1.1: Configure Elasticsearch as your Source

Refer to the Hevo documentation to help you connect Elasticsearch as a Source easily.
Step 1.2: Set BigQuery as your Destination

Key Features of Hevo Data
- Data Transformation: Hevo Data provides you the ability to transform your data for analysis with a simple Python-based drag-and-drop data transformation technique.
- Automated Schema Mapping: Hevo Data automatically arranges the destination schema to match the incoming data. It also lets you choose between Full and Incremental Mapping.
- Incremental Data Load: It ensures proper utilization of bandwidth both on the source and the destination by allowing real-time data transfer of the modified data.

Method 2: Using Google Dataflow
To illustrate how to integrate data from Elasticsearch to BigQuery, we are going to use a public dataset from Stack Overflow. With just a few steps, you can successfully ingest this data using Dataflow job.
Step 2.1: Log in to Google Cloud Platform
You can use your existing Google Account to log in; otherwise, you can create a new account.
- You can download the public dataset that I have used, or you can use your own dataset.
- Click on View Dataset.
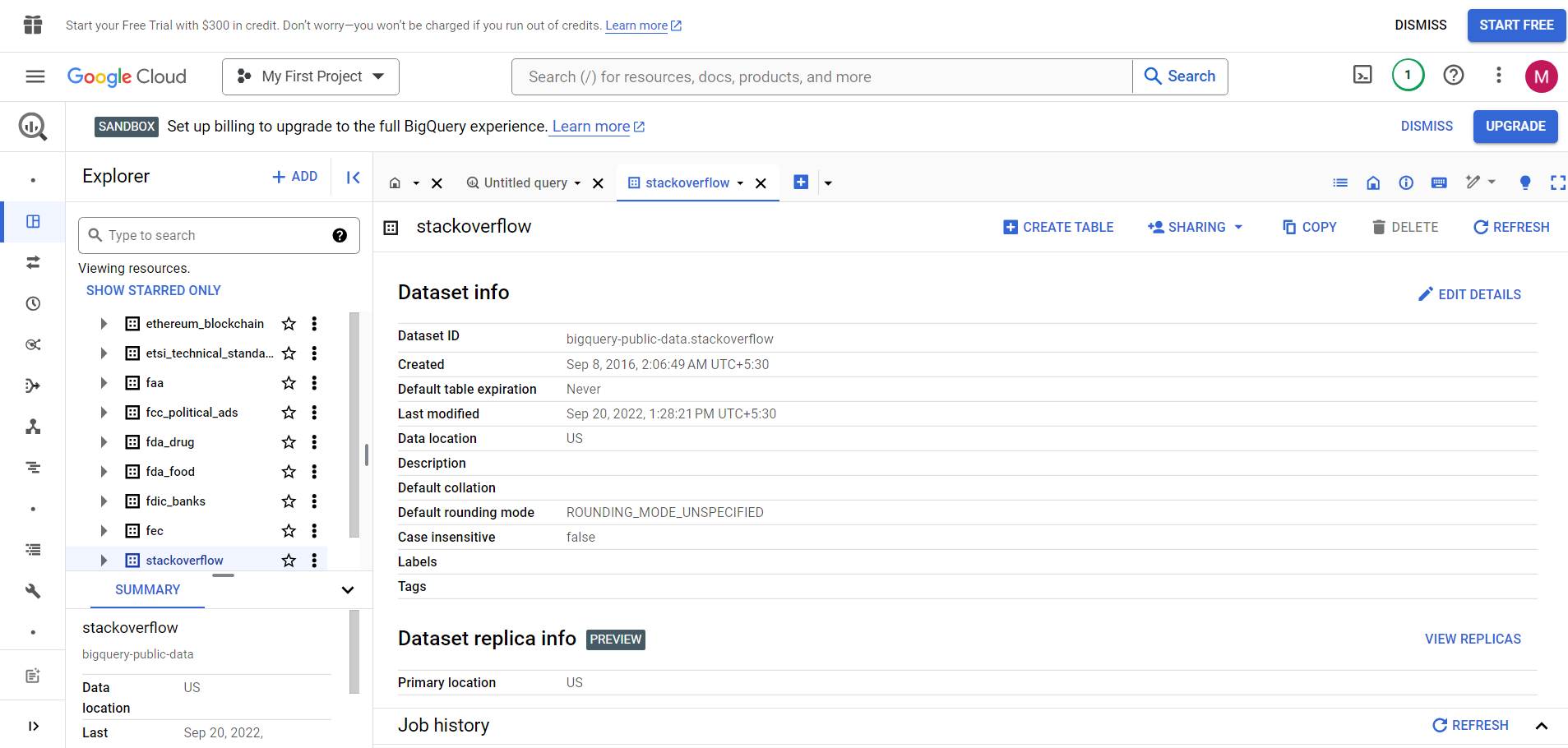
- Once you click on View Dataset, you will be redirected to BigQuery Studio.
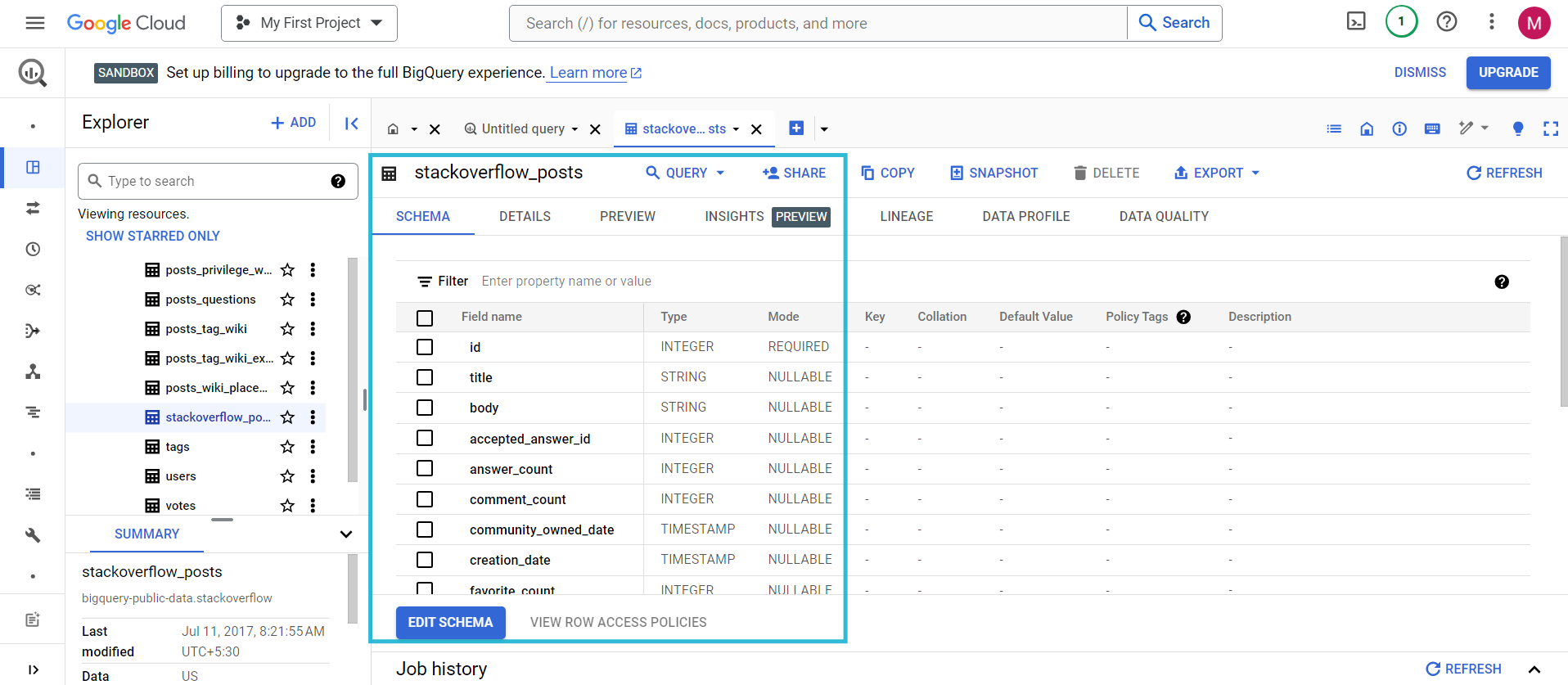
- You can search for the table stackoverflow_posts under the BigQuery dataset. It has columns like id, title, body, etc.
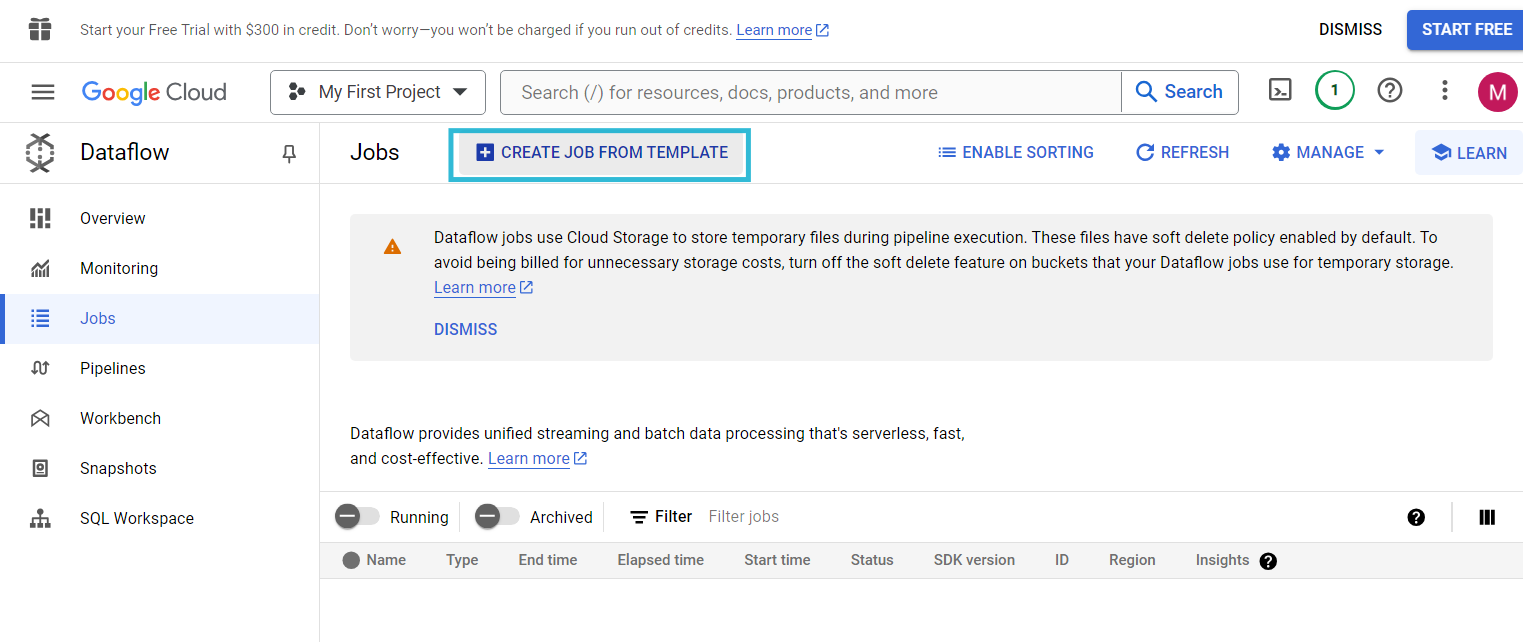
Step 2.2: Create a DataFlow Job
You can create a DataFlow Job to migrate data from BigQuery to ElasticSearch.
- Select BigQuery to ElasticSearch from the drop-down menu, which is one of Google’s provided templates.
- You can fill in the Job name and Regional endpoint as per your choice. I have given the Job name as stackoverflow_load, and the regional endpoint as us-central1(lowa).
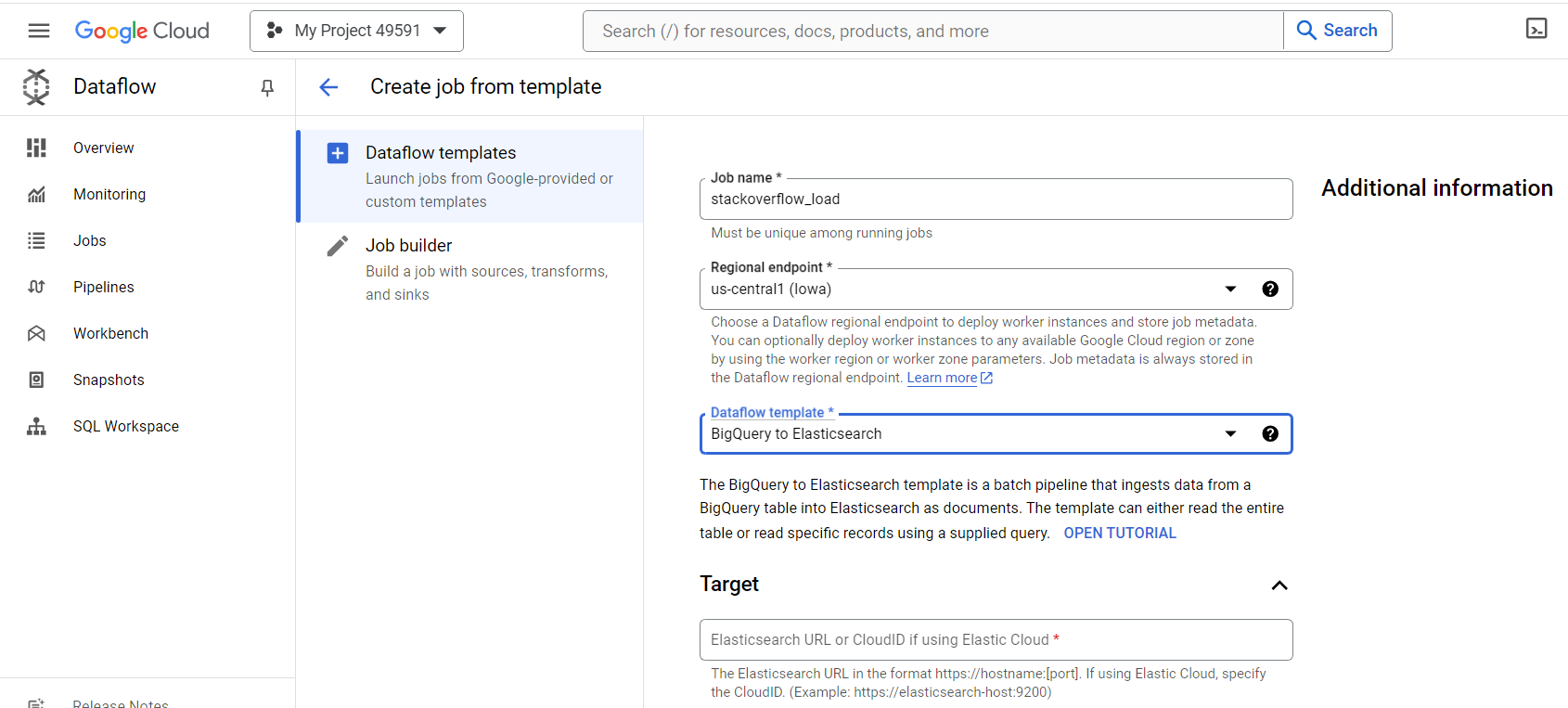
- If you don’t have an existing API key, you can create an API key.
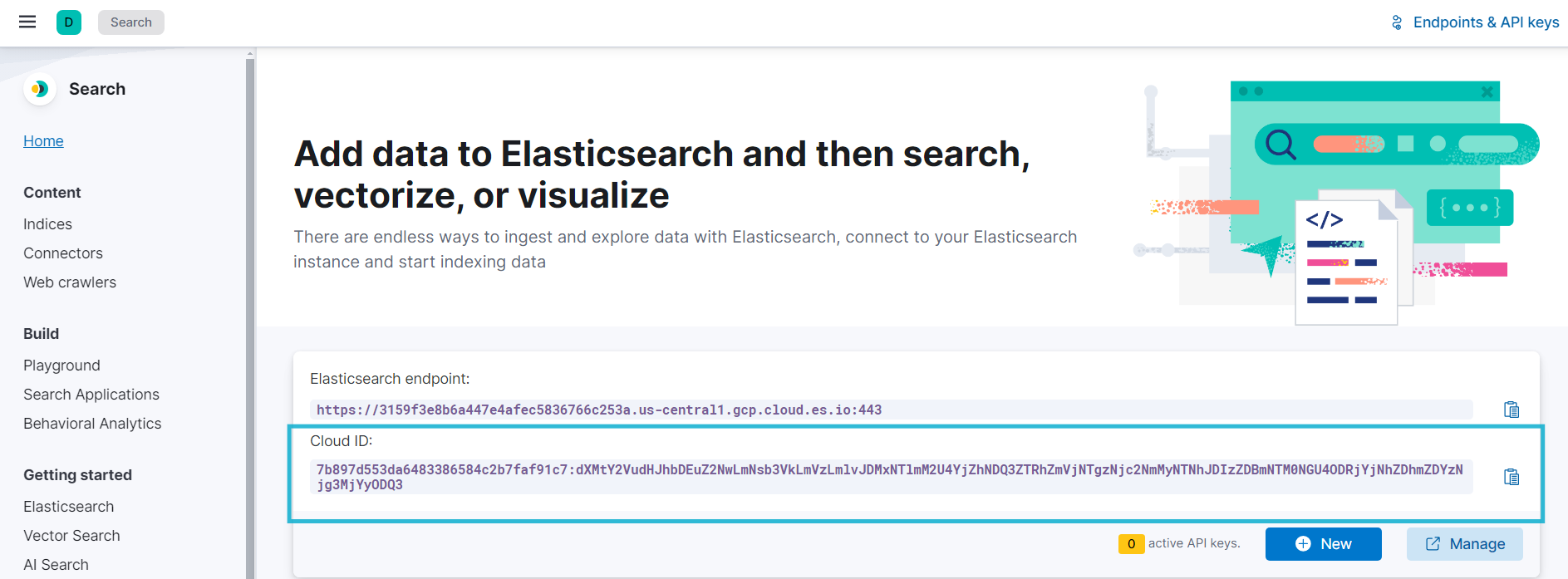
- The API Key would be a Base64-encoded key.
- Cloud ID will be shown when you create a new API key. I have highlighted the Cloud ID of my API key for your reference.
{
"id": "Qq3CypABgXuLDQJS7fph",
"name": "demo",
"expiration": 1726572690786,
<strong>"api_key": "mTrSpsIYQSqtPmeXbOtXAg,"</strong>
"encoded": "UXEzQ3lwQUJnWHVMRFFKUzdmcGg6bVRyU3BzSVlRU3F0UG1lWGJPdFhBZw==",
"beats_logstash_format": "Qq3CypABgXuLDQJS7fph:mTrSpsIYQSqtPmeXbOtXAg"
}
The highlighted is what your API key would like.
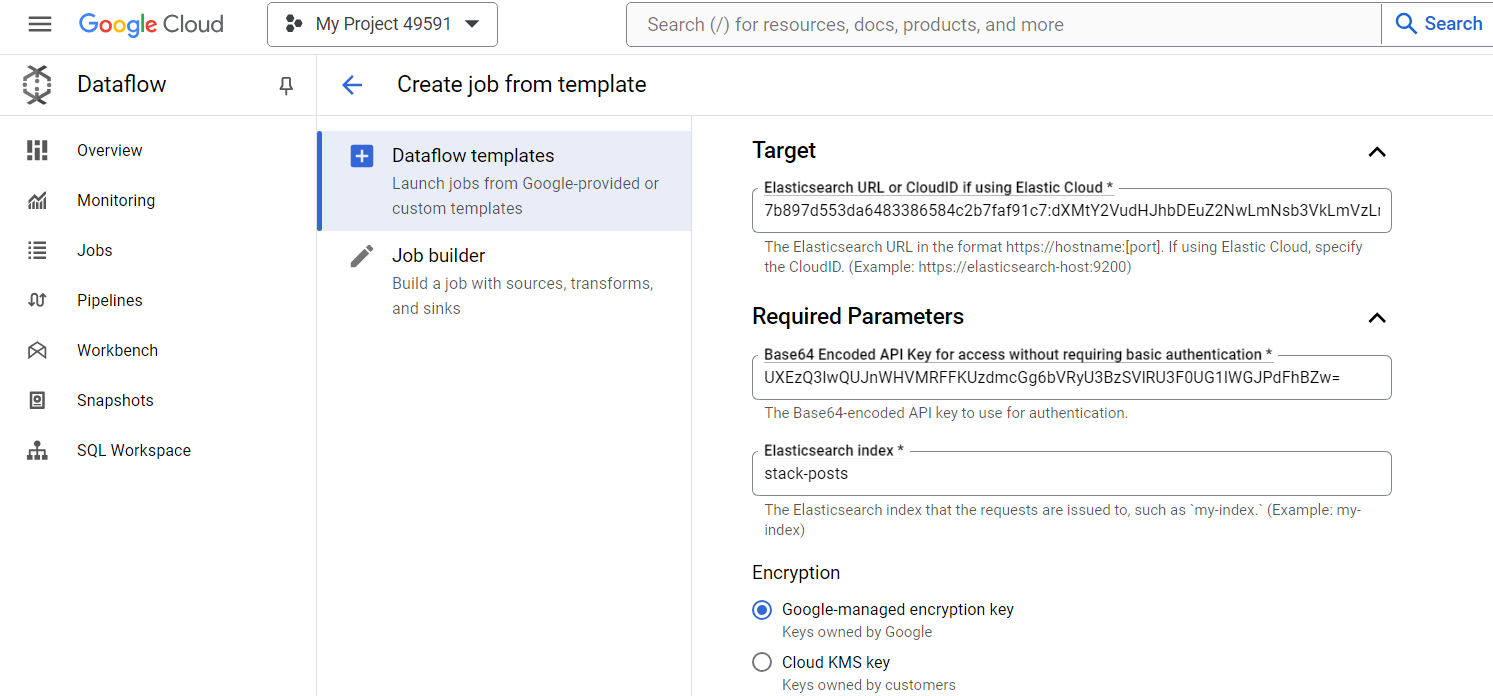
Step 2.3: Run the Job
Once you have filled in the necessary fields, check them once, and you can run the created job.
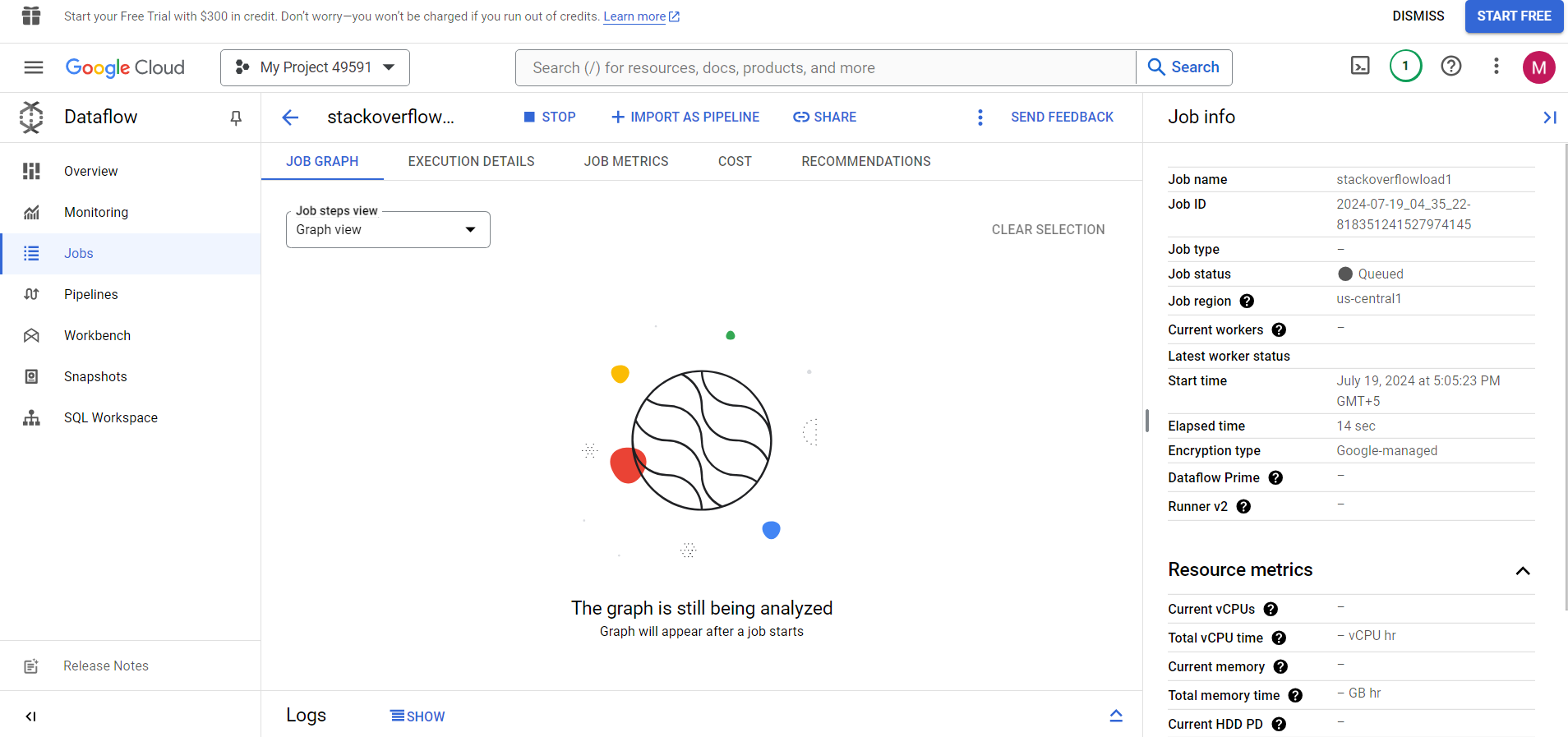
Step 2.4: Using ElasticsearchIO to Fetch Data from Elasticsearch
- The details can vary depending on the creation of an API key. I have attached my details for your reference.
- Once checked, you can now Click on ‘Run Job’ to start the batch processing dataflow.

Within a few minutes, you can visualize your data flowing into your Elasticsearch index.
Limitations of Using Google Dataflow
- Integrating Elasticsearch with Google BigQuery using Apache Beam & Google Dataflow requires you to write custom Kotlin-based code to fetch, transform, and then load data. Hence, you must have strong technical knowledge.
- Setting up a dedicated VPC network, NAT gateways, etc., can be a challenging task, especially for beginners as it requires you to have a deep understanding of how IP addresses & subnetting work.
- You must ensure that you provide all correct parameters, such as table name, schema, etc., as even a small error can result in the ETL process failing.
- It requires you to have a general idea of how different services, such as Apache Airflow, Beam, Google Dataflow, etc., work, resulting in a bottleneck, as many might not be aware of their operations.
Use Cases of BigQuery Elasticsearch Integration
- Data Analytics: Using Elasticsearch connector for BigQuery, you can analyze your business data in real time. BigQuery’s Machine Learning features enable you to generate insightful analytics about customers, campaigns, and marketing pipelines.
- Data Storage: Building ETL pipelines for Elasticsearch BigQuery makes the data storage and transformation process easier. You can store large amounts of data, for example, marketing data from multiple sources, in a centralized cloud-based location such as BigQuery. You can access and query the data without expensive storage hardware.
Also, check out more helpful resources to download data from an Elasticsearch Export to make working with Elasticsearch seamless.
Conclusion
This article teaches you how to connect Elasticsearch to BigQuery with ease. It provides in-depth knowledge about the concepts behind every step to help you understand and implement them efficiently. These methods, however, can be challenging, especially for a beginner & this is where Hevo saves the day. Hevo Data, a No-code Data Pipeline, helps you transfer data from a source of your choice in a fully-automated and secure manner without having to write the code repeatedly. This articles also sheds light on some BigQuery connector for Elasticsearch use cases.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
FAQs
1. How do I connect Elasticsearch to BigQuery?
To connect Elasticsearch to BigQuery:
1. Export data from Elasticsearch to a format like JSON or CSV.
2. Use BigQuery’s data import tools (such as Dataflow or the BigQuery web UI) to load the exported data into BigQuery.
2. How to store data in Elasticsearch?
To store data in Elasticsearch:
1. Use Elasticsearch’s RESTful API or one of its official clients (such as Elasticsearch Python client or Elasticsearch Java client).
2. Index documents by sending HTTP requests with JSON payloads containing the data to be stored.
3. Is BigQuery free?
BigQuery offers a free tier with some limitations, such as a monthly query processing limit and data storage limit. Beyond the free tier, usage is billed based on the amount of data processed by queries and stored in BigQuery.
4. Is Elasticsearch a database or not?
Elasticsearch is often categorized as a search and analytics engine rather than a traditional database.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



