

In recent years, Apache Iceberg has seen considerable advancements that highlights its growing importance. Major tech companies like Google, Snowflake, and Databricks have increasingly embraced this table format.
- Google integrated Iceberg into BigLake and BigQuery, thus making it a leading choice for open-format lakehouses.
- Snowflake has significantly boosted the performance of Iceberg tables and is set to introduce REST catalog support, further enhancing its compatibility across various platforms.
- Databricks has also announced its plans to support Iceberg, reflecting its escalating acceptance within the industry.
This trend, driven by major tech companies, highlights a transformative shift in the data warehousing landscape as Iceberg gains traction.
In this blog, we will explore how data management and machine learning applications are powered by the Iceberg architecture. We will delve into its core features and demonstrate how Iceberg enhances data and ML workflows through practical examples and industry use cases.
Unlock a more efficient way to manage large datasets. Hevo now supports Apache Iceberg, enabling a scalable and high-performance data lakehouse.
Why Apache Iceberg?
- Optimized Performance – Reduce scan times with intelligent metadata management.
- Schema & Partition Evolution – Adapt your data structure without breaking workflows.
- ACID Transactions & Time Travel – Ensure data consistency and easily retrieve past versions.
Take control of your data with Hevo and Apache Iceberg. Get started for free!
Get Started with Hevo for FreeTable of Contents
Exploring the Iceberg architecture layer-by-layer
Apache Iceberg is a revolutionary table format designed to bring high performance and reliability to big data workloads. Its architecture is divided into several layers, each playing a crucial role in managing and processing large datasets efficiently. Let us explore the Iceberg architecture layers in depth as shown in the figure below:

1. Data layer: The core of storage
The core of Iceberg’s architecture is its data layer, the fundamental component responsible for storage. This layer holds the actual data files, which can be formatted as Parquet, ORC, or Avro, and are generally stored in distributed storage systems such as HDFS, S3, or ADLS. The data layer which is positioned at the base of the architecture, provides the crucial foundation for the subsequent layers. Its key functions are efficient storage management, which ensures that the organization is handling large datasets with high efficiency, and support for diverse file formats, guaranteeing compatibility and performance across various data formats. It also helps reduce storage needs and enhances read/write operations.
2. Manifest files
Manifest files function as the metadata catalog for the data layer, detailing all data files and their associated metadata. They monitor the manifest lists, which contain vital information about the table’s schema, partitions, snapshots, and current state. These files store the metadata in JSON file format.
3. Manifest lists
Manifest lists are nothing but the metadata aggregator. This means that they keep track of the manifest files, and record their locations, partition details, and the range of partition columns they cover. Stored in Avro file format, each manifest list file acts as a snapshot of the Iceberg table, including snapshot details identified by a unique ‘snapshot_id.’
4. Metadata layer: The central coordinator
The metadata layer, which is the central coordinator, acts as the central repository for all the table-related information, managing a snapshot of the table’s schema, partitioning, and version history. It is at the top of the architecture and acts as the primary coordinator for all metadata activities. It helps in schema management, which tracks schema evolution to ensure both backward and forward compatibility; snapshot management, which oversees table snapshots to facilitate time travel and consistent query results; and partition specification, which maintains details about table partitioning to optimize data access.
5. Catalog
The catalog layer is the entry point for users and applications to interact with Iceberg tables. It is basically the user interface. It provides an interface for creating, deleting, and managing tables. As shown in the figure, it is at the topmost level of the architecture, hence, signifying its role as the interface between users/applications and the Iceberg architecture.
This layer helps in creating, deleting, and managing the Iceberg tables. It ensures that the tasks are performed efficiently. Additionally, it provides APIs that enable seamless interaction between users and applications with the tables, facilitating smooth and effective data operations.
Integrating all the layers
- Apache Iceberg’s layered structure and comprehensive architecture promote efficient data management and superior performance.
- Each layer serves a distinct purpose, from raw data storage to user interaction, forming a cohesive system.
- The architecture provides a robust framework that manages complex data workflows effectively.
- Understanding this architecture reveals Iceberg’s design principles and its approach to modern data lake challenges.
- By leveraging its layered approach, Iceberg offers reliable, scalable, and high-performance data management solutions.
Enhancing Data Lakes with Iceberg by bridging the gap between flexibility and reliability
The integration of Apache Iceberg with traditional data warehouses introduces sophisticated features that enhance the capabilities of traditional data warehouses. This significantly improved the reliability and performance of contemporary data analytics. Traditional data warehouses are known for their robust infrastructure and optimized performance capabilities. They excel at SQL query optimization and stringent query controls, which ensures high levels of data security and consistency across various operations.
Traditional data warehouses offer several advantages, including well-established table structures that provide a reliable base for efficient data storage and querying. They are known for optimized performance, enabling rapid data retrieval for time-sensitive analytical tasks. Strong access controls protect data integrity by restricting access to authorized personnel. Additionally, query isolation prevents conflicts and maintains data accuracy.
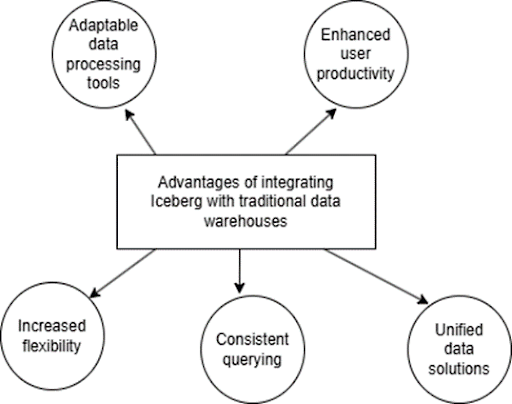
The Advantages of Integrating Iceberg with Data Warehouses
- Supports Modern Workflows: Iceberg enables data warehouses to handle current workflows, like parallel data loading and real-time processing, which are essential for today’s data needs.
- Flexible Data Processing: By connecting different data environments, Iceberg provides flexibility to work across tools and adapt to various data requirements.
- Improves Data Reliability: Iceberg’s features help keep data accurate and reliable, which is crucial for trusted data use.
- Enables Consistent Querying Across Tools: With Iceberg, users can query data consistently across different tools, from BI dashboards to Spark, making data analysis more flexible.
- Unified Data Solution: Iceberg combines the strengths of data lakes and warehouses, providing a seamless solution for managing and processing data across various areas.
Building a Data and ML Application with Iceberg
In this section, we will take an example table ‘customer_data’, to build a data and ML application using Iceberg to perform ‘Customer Segmentation’ at Amazon, aimed at targeted marketing and personalized recommendations.
Environment Setup
Set up a Spark session with Iceberg configurations.
Ingesting the Data into Iceberg
For ingesting data into Iceberg, we will create a table by partitioning based on ‘transaction_date’ for better query performance.
spark.sql("""
CREATE TABLE spark_catalog.defaul.customer_data (
customer_id BIGINT,
transaction_data STRING,
transaction_amount DOUBLE,
category STRING
)
USING iceberg
PARTITIONED BY (transaction_date)
""")Querying the Data
Aggregate the customer data by counting transactions for each customer:
customer_df = spark.sql("""
SELECT customer_id, COUNT(*) as transaction_count
FROM spark_catalog.default.customer_data
GROUP BY customer_id
""")
customer_df.show()The output will be something like this:
+------------------+------------------+
| customer_id | transaction_count|
+------------------+------------------+
| 12345678| 10|
| 87654321| 15|
| 11223344| 22|
+------------------+------------------+Optimize the query performance by filtering the data by date:
customer_df = spark.sql("""
SELECT * FROM spark_catalog.default.customer_data
WHERE tranasction_date >= '2023-01-01'
""")
customer_df.show()The output will be:
+------------------+------------------+------------------+--------+
| customer_id | transaction_date |transaction_amount|category|
+------------------+------------------+------------------+--------+
| 12345678| 2023-01-05| 50.0| Books|
| 87654321| 2023-02-10| 100.0| Toys|
| 11223344| 2023-03-15| 75.0| Games|
+------------------+------------------+------------------+--------+Integrating Iceberg with ML Pipelines
Feature Engineering: Prepare data by combining relevant columns into feature vectors.
from pyapark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=["transaction_count", "transaction_amount"],
outputCol="features")
customer_features = assembler.transform(customer_df)Model training using K-Means clustering will help identify distinct customer groups based on the transaction count and the transaction amount. We are segmenting customers into 5 groups:
from pysprak.ml.clustering import KMeans
kmeans = Kmeans().setK(5).setSeed(1)
model = kmeans.fit(customer_features)
predictions = model.transform(customer_features)
predictions.show()Here we are segmenting customers into 5 groups and each customer will be assigned a label corresponding to one of these 5 clusters (0, 1, 2, 3, or 4).
The output:
+------------+------------------+------------------+--------+------------+---------+
|customer_id| transaction_count|transaction_amount|category | features|prediction|
+------------+------------------+------------------+--------+------------+---------+
| 12345678| 10| 50.0| Books| [10.0,50.0]| 0|
| 87654321| 15| 100.0| Toys|[15.0,100.0]| 1|
| 11223344| 22| 75.0| Games| [22.0,75.0]| 2|
+------------+------------------+------------------+--------+------------+---------+For the above output:
- Cluster 0 might represent customers with moderate transaction counts (10 transactions) and moderate transaction amounts ($50.0), possibly interested in books.
- Cluster 1 might represent customers with higher transaction counts (15 transactions) and higher transaction amounts ($100.0), likely interested in toys.
- Cluster 2 might represent customers with high transaction counts (22 transactions) and moderate transaction amounts ($75.0), possibly interested in games.
For feature store management, save and load feature data for consistent inputs in ML workflows.
Case Studies of Companies using Iceberg to Power Data and ML Applications
- Apache Iceberg-powered data lake architecture at Amazon on Amazon Web Services (AWS)
Amazon has embraced Apache Iceberg as a pivotal component within its AWS ecosystem, leveraging its advanced capabilities to manage expansive analytic datasets stored on Amazon S3. The distinctive open table format of Iceberg captures detailed metadata and facilitates seamless integration with leading compute engines such as Spark, Trino, and Hive. This integration empowers Amazon EMR to provision clusters efficiently without additional setup, enhancing operational agility and scalability.
The recent enhancement of Athena with ACID transactions powered by Iceberg underscores Amazon’s commitment to bolstering transactional capabilities within their analytics offerings. This strategic adoption enables Amazon to effectively handle schema evolution, time travel queries, and complex data operations while ensuring data integrity and query performance at scale. By utilizing Iceberg, Amazon meets the evolving demands of modern data lakes and optimizes cost efficiency and operational effectiveness across their analytics workflows.
Read more about AWS Big Data
- The data cloud at Snowflake leverages Apache Iceberg for scalable and secure analytics
Snowflake has integrated Apache Iceberg into its Data Cloud platform, empowering organizations to handle expansive and complex data workloads using various file formats, including Parquet, Avro, ORC, JSON, and XML. Snowflake’s internal, fully managed table format simplifies storage maintenance with features like encryption, transactional consistency, versioning, fail-safe, and time travel. However, some organizations prefer or are required to store data externally in open formats due to regulatory or other constraints.
With the introduction of Iceberg tables, Snowflake combines the high performance and familiar query semantics of its native tables with the flexibility of customer-managed cloud storage. This integration, currently in public preview, allows Snowflake users to leverage the open table format of Iceberg, which captures detailed metadata and supports advanced data management capabilities.
Snowflake users can now overcome common data barriers, such as siloed data and inefficient data sharing. The platform enables secure sharing of complex data sets both internally and with external partners, and facilitates large-scale analytics tasks on massive data sets quickly and efficiently. By adopting Iceberg Tables, Snowflake ensures that organizations can achieve optimal performance, scalability, and data governance while maintaining the flexibility of open storage formats.

What innovative solutions will you create with Iceberg?
- Segmentation That Evolves Over Time: With the schema evolution capabilities of Iceberg, you can model your customer segmentation, which would automatically change with new incoming data on the fly, with no need for manual refreshing of configuration.
- Smarter Machine Learning Workflows: With time travel in Iceberg, access real-time data along with historical data in one place to better observe the evolution of patterns in your data and refine your machine learning models.
Getting started with Iceberg isn’t about getting started- it’s about setting up your data operations for flexibility and knowing what’s next.
The Iceberg advantage: What’s next for you?
Apache Iceberg is revolutionizing modern data architectures with its robust design and advanced features. Its scalable metadata layer, sophisticated data layout, and comprehensive API support deliver unmatched efficiency and reliability for data and ML applications.
We’ve seen a clear shift from legacy data lake and warehousing solutions to Iceberg. With improvements in schema evolution, partitioning, time travel, scalability, and interoperability, companies are now building large-scale ingestion architectures around Iceberg and open-source tools like Spark. This shift underscores the need for flexible and performant data management solutions.
Organizations leveraging Iceberg streamline data processing workflows, enhance data integrity, and drive insightful analytics. Its compatibility with engines like Apache Spark and Flink, ACID transactions, and schema evolution capabilities make Iceberg a cornerstone for scalable, high-performing data lakes.
Future-proof your data operations with Hevo’s comprehensive data integration platform. Even if you’re not using Iceberg, our solutions ensure smooth data handling and integration across your entire ecosystem. Register for a personalized demo, no credit card required.
Try Hevo’s 14-day trial and experience seamless integration.
Frequently Asked Questions
1. What is the Iceberg format architecture?
Apache Iceberg is a table format architecture for huge analytic datasets, designed for high performance. It includes features like ACID transactions, schema evolution, partitioning, and efficient metadata handling to optimize data lake management and enhance query performance.
2. What is Iceberg used for?
Apache Iceberg is used for managing large-scale tabular data in data lakes, providing capabilities like versioned data, schema evolution, and efficient querying to support data warehousing and machine learning applications.
3. Does Iceberg use parquet?
Yes, Apache Iceberg can use Parquet as one of its file formats for storing data.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




