




What if someone asked you some incredibly specific questions regarding your customers. With this in mind, this post dives into Big Data Analytics and Queries. Specifically, it is designed to make you understand Federated Query BigQuery.
Say, how many clients does your business have? How many of these customers are actively engaged with your business? How many clients are in specific regions? Federated queries offer a powerful solution to these questions by enabling you to seamlessly query data across these disparate sources as if they were a single unified dataset.
Table of Contents
What is Federated Query?
At their core, federated queries are a type of query that combines data from multiple sources within a single query execution. Instead of moving data from its original location, federated queries leverage specialized software (federation engines) to execute the query across distributed sources and return the combined results.
This approach makes it appear as if the data is located in one place, simplifying access and analysis. Federated queries are commonly used to retrieve and analyze data from various sources, such as databases and other data repositories, enabling seamless integration for comprehensive insights.
Key Benefits of Federated Queries
- Data Integration without Data Movement: Avoids the overhead and potential data inconsistencies associated with data replication or ETL (Extract, Transform, Load) processes.
- Improved Data Accessibility: It provides a unified view of data across diverse sources, making it easier for analysts to access and analyze the needed information.
- Enhanced Data Governance: Allows organizations to maintain data in its original location, improving data security and compliance with regulations like GDPR.
- Scalability and Performance: It can improve query performance by distributing the processing load across multiple systems, especially for large-scale datasets.
- Reduced Data Silos: Breaks down data silos and fosters a more holistic view of organizational data
Understanding the Essentials of Federated Queries
Federated queries simplify accessing data from multiple sources. Here are some important aspects to know:
- Syntax: Federated queries resemble standard join queries but include additional details about the data’s location.
- Applications: These are commonly applied in business intelligence and data warehousing scenarios requiring a unified data from multiple sources.
- Significance: With the increasing dependence on online datasets, federated queries allow the integration of multiple datasets for a comprehensive view.
- Challenges: They increase source system loads and are known to require enough network bandwidth, computing power, and other resources to handle the load successfully.
What are BigQuery Federated Queries?
- When using data to make critical business decisions, you need information from different Data Marts, Warehouses, and Transactional Databases to draw the required statistics.
- Let’s take a situation where you work with BigQuery as your Data Warehouse and CloudSQL as your Relational Database. Y
- ou need to find a bridge between these two systems, right?
- Simply put, a way to send a query to an external Database and get the output in the form of a temporary table. These queries rely on the BigQuery Connection API to connect with an external Database.
In our case, we would use the EXTRENAL_QUERY function to connect with CloudSQL. We would then query the data in this platform and get the results as temporary tables.
Below is a sample of a Federated Query BigQuery:
SELECT * FROM EXTERNAL_QUERY
("test-fedquery-mysql", "SELECT customer_id, MIN(order date) AS first_order_date
FROM orders
GROUP BY customer_id;");Hevo makes BigQuery ETL effortless with its no-code data pipelines. Automate data ingestion, transformation, and loading seamlessly while enjoying real-time updates and robust data integrity. Transform your ETL process and focus on insights, not complexities.
Here’s why you should choose Hevo:
- 150+ sources, along with plug-and-play transformations
- Real-time data transfer with zero data loss
- 24/5 Live Support with real data engineers
Hevo has been rated 4.7/5 on Capterra. Know more about our 2000+ customers and give us a try.
Get Started with Hevo for FreeSetting Up Federated Query BigQuery
Step 1: Adding External Data Source
Navigate to BigQuery, select “Add Data” and click “External Data Source“.
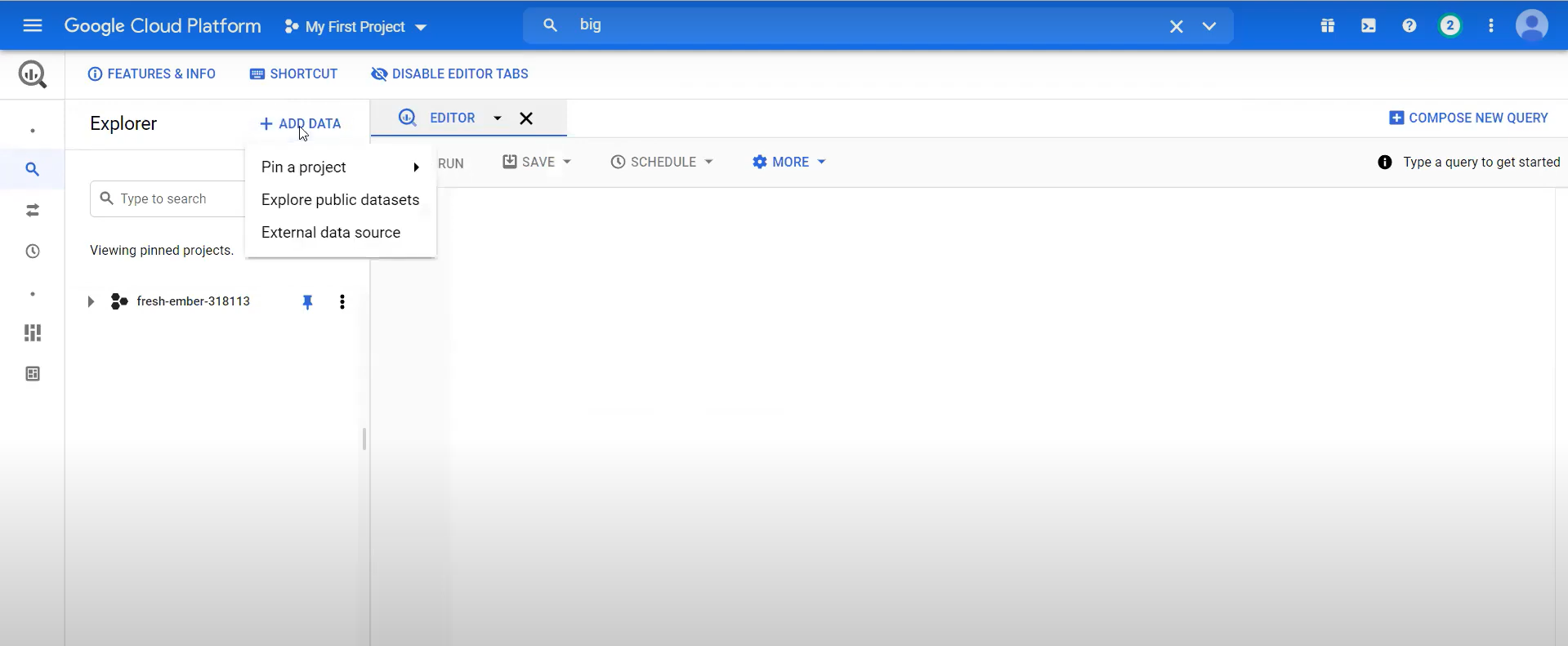
Step 2: Input Source Details
Key in the “External data source” credentials.
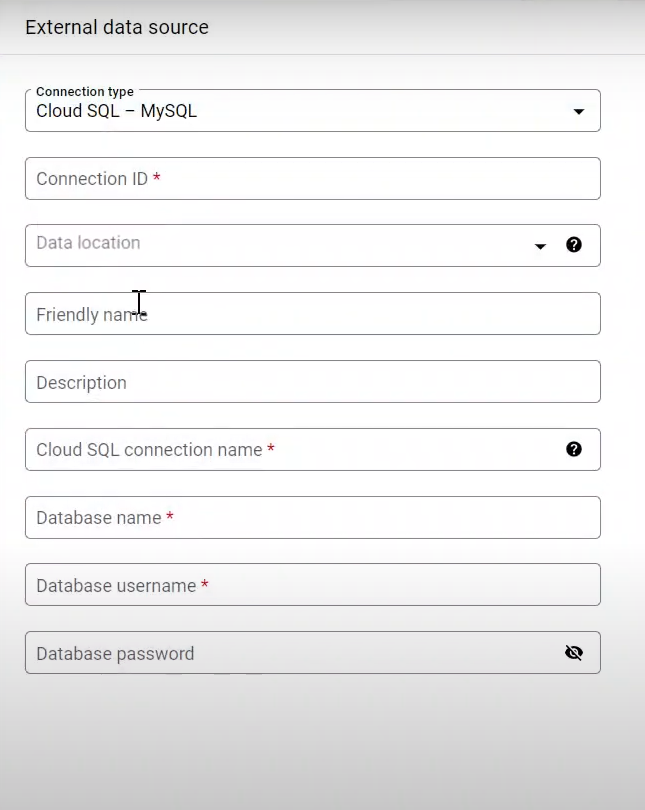
Step 3: Connect to Instance
Feel free to copy the Cloud SQL Instance ID from the SQL instance page under “Connection name“.
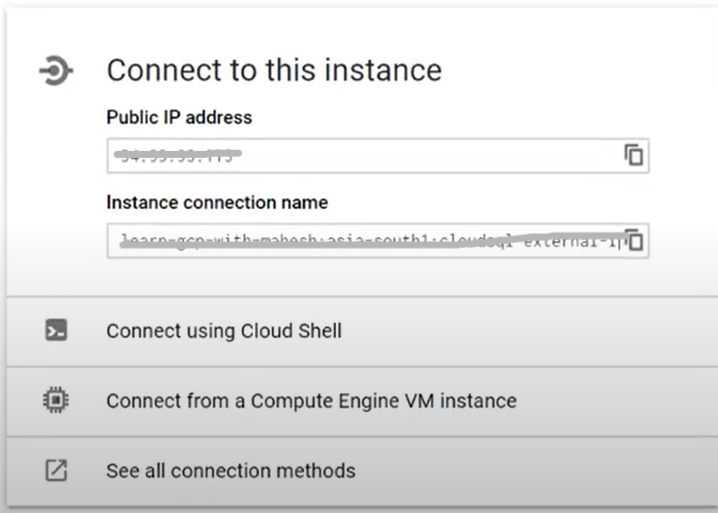
That’s it! By following the steps above. You have successfully set up a connection from Google BigQuery to an External Database using the Federated Query BigQuery.

Conclusion
In this post, you learnt what Google BigQuery is and some of the features it entails. More importantly, you learnt what Federated Query BigQuery is and how to implement them. Now, you stand a better chance to use Cloud SQL and Cloud Spanner together with Bug Query.
However, extracting data from a wide variety of sources and connecting to BigQuery is a tedious and time taking process but using a Data Integration tool like Hevo can perform this process with no effort and no time.
Sign up for a 14-day free trial today. Hevo offers plans & pricing for different use cases and business needs, check them out!
Frequently Asked Questions
1. What is a federated query in BigQuery?
A federated query in Google BigQuery allows you to run SQL queries across data stored in external sources without needing to move or import the data into BigQuery.
2. Is it posible to make a federated query from Cloud SQL to BigQuery?
Yes, it is possible to make a federated query from Cloud SQL to BigQuery.
3. What is federation query?
Federation query is another term used to describe the capability of querying data from various external sources as if it were part of your data warehouse or data lake.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



