



Today, organizations rely on many technologies such as chatbots, social media platforms, emails, and more to communicate with customers. But, all these technologies lack the human touch that customers mostly want. As every customer interaction is different, a human touch becomes essential to address problems. Therefore, organizations use Front to build strong customer relations and provide human interaction.
In this article, you will learn how to connect Front to Redshift in two methods and the limitations of connecting Front to Redshift.
Table of Contents
Prerequisites
- Fundamental knowledge of AWS cloud
- An Active Amazon Redshift cluster with endpoint and port.
- Properly configured VPC
What is Front?

Developed in 2013, Front is a communication hub that helps organizations strengthen customer relationships. It offers organizations to deliver an experience their customers can rave about. Front enables organizations to let clients be at the center of all operations for professional service teams, right from support to marketing and development.
It allows organizations to collect customer data from different channels such as emails, texts, social media, WhatsApp, calls, and more on one platform. This enables teams in organizations to collaborate and respond to their customers in real-time. Front also offers organizations automated workflows and analytics features, which can analyze data and provide a complete 360 view of all the customer data.
Key Features of Front
- Automated integrations: Front consists of no-code automation and integration capabilities, which can replace the complexity of the manual integration processes. It contains a library of integration that allows you to connect Front to your favorite tools, CRM, chatbots, and more.
- Win more Customers: As Front allows organizations to collect data from different sources such as emails, texts, calls, WhatsApp, and more, organizations quickly resolve customers’ issues, thereby keeping them happy.
- Collaboration: Front allows organizations to access customer data across different channels in one place in the team inbox. It ensures that every user in a team can access every message.
What is Amazon Redshift?
Developed in 2012, Amazon Redshift is a popular, fully scalable, and reliable data warehouse. Organizations can start using Amazon Redshift with a set of nodes called Amazon clusters. The Amazon clusters can be managed by Amazon Command Line Interface or Redshift Console. Amazon Redshift consists of a column-oriented database, which helps organizations in connecting SQL-based clients like BI tools for quick analysis.
Amazon Redshift also allows organizations to manage clusters programmatically by using Amazon Redshift Query API or AWS Software Development Kit.
Key Features of Amazon Redshift
- ANSI-SQL: Amazon Redshift is based on ANSI-SQL, which uses industry-standard ODBC and JDBC connections, enabling you to use your existing SQL clients and BI tools. You can seamlessly query files like CSV, JSON, ORC, Avro, Parquet, and more with ANSI-SQL.
- AQUA (Advanced Query Accelerator): Amazon Redshift consists of a distributed and hardware-accelerated cache known as AQUA. It speeds up Amazon Redshift up to 10x compared to other enterprise cloud data warehouses.
- Robust Security: Amazon Redshift enables users to secure data warehouses without an additional cost. With Amazon Redshift, users can configure firewalls to control network access with a specific data warehouse cluster.
- Result Caching: The result caching feature of Amazon Redshift can deliver a sub-second response time for repeated queries. When a query is executed in Amazon Redshift, it can search the cache to get any search results from the previous queries.
- Fast Performance: Amazon Redshift offers fast performance due to its unique features such as massively parallel processing, columnar data storage, result caching, query optimizer, data compression, compiled code, and more.
Method 1: Connecting Front to Redshift using Hevo
Hevo Data, an Automated Data Pipeline, provides you a hassle-free solution to connect Front to Redshift within minutes with an easy-to-use no-code interface. Hevo is fully managed and completely automates the process of not only loading data from Xero but also enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
GET STARTED WITH HEVO FOR FREEMethod 2: Connecting Front to Redshift using CSV
This method would be time-consuming and somewhat tedious to implement. Users will have to write custom codes to enable two processes, exporting data from Front and importing data into Redshift through CSV Files. This method is suitable for users with a technical background.
Methods of Connecting Front to Redshift
Method 1: Connecting Front to Redshift using Hevo
Hevo provides Amazon Redshift as a Destination for loading/transferring data from any Source system, which also includes Front.
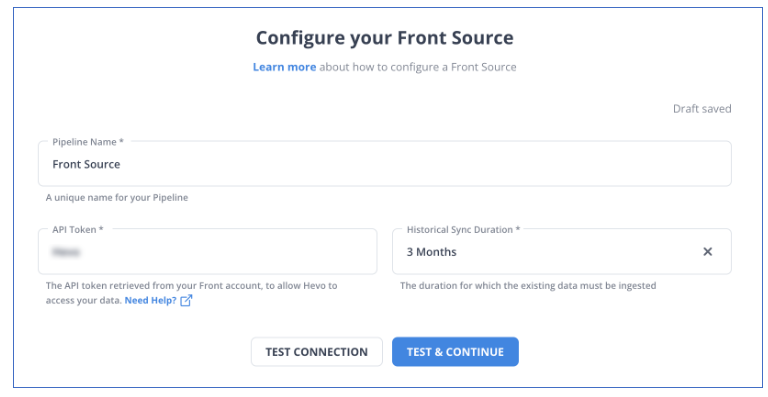
Step 1: Configuring Front as a Source
Step 2: Configuring Amazon Redshift as a Destination
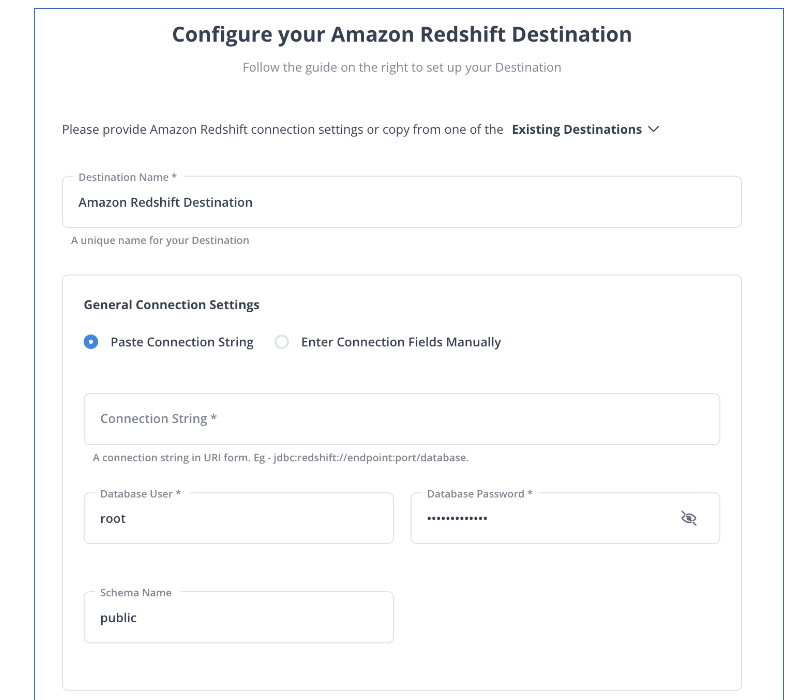
Hence, the data will be replicated to your destination.
Check out what makes Hevo amazing:
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: Hevo has in-built integrations for 100+ sources (with 40+ free sources) that can help you scale your data infrastructure as required.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Method 2: Connecting Front to Redshift using CSV
To connect Front to Redshift, you must export Front data and then import it to Amazon Redshift.
Step 1: Exporting Front data
The first step in Front to Redshift Integration is to export data from Front. It is assumed that you have signed in to Front. Front allows you to connect your workspace by using Gmail accounts. After setting your workspace, you can create shared inboxes, collaborate with your teams, add message templates and create rules in Front.
Follow the below steps to export Front report data to a csv file.
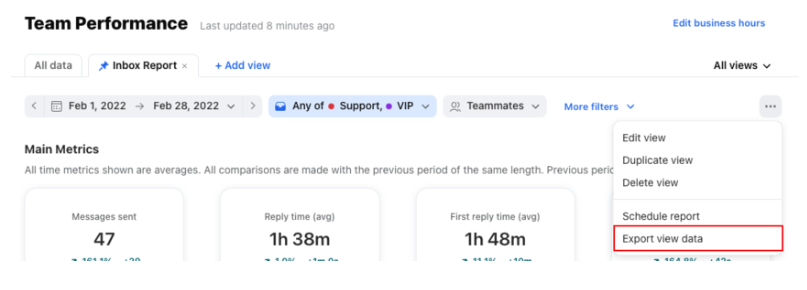
- Step 1.1: Click on the three dots on the top right of the report view and select Export View Data.
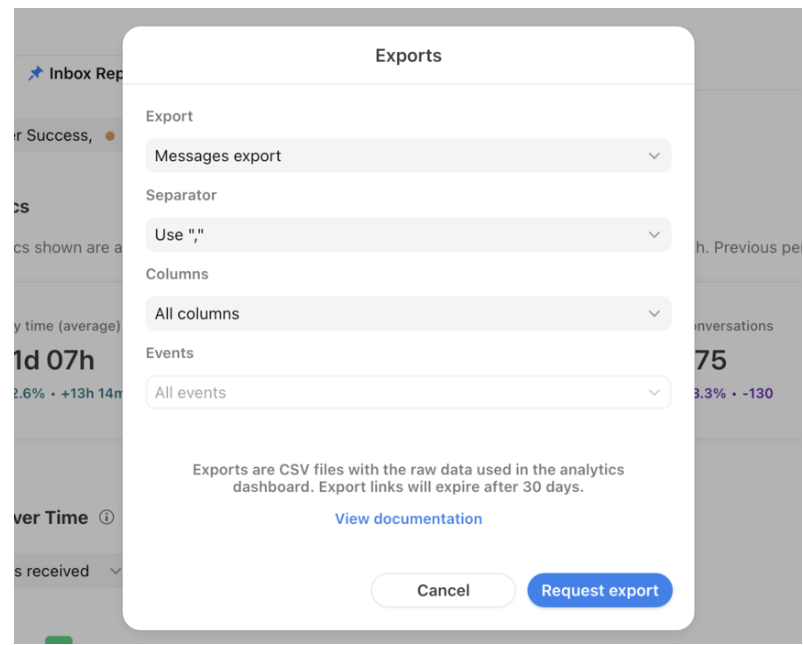
- Step 1.2: Select your export type in the Export field and click on Request export.
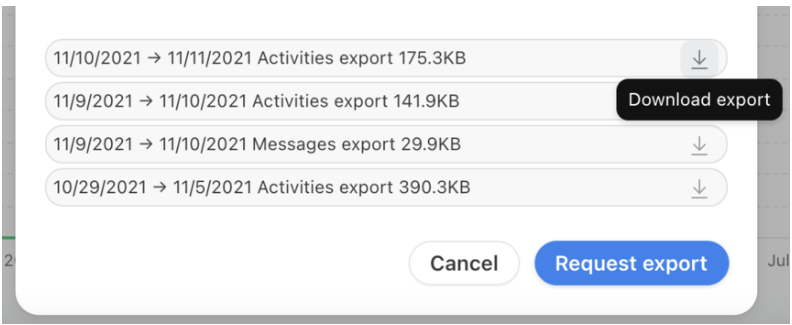
- Step 1.3: At the bottom of the pop-up screen, you can see the prepared exports, which are ready to be downloaded. Click on the Download export arrow icon to save the export to your computer.
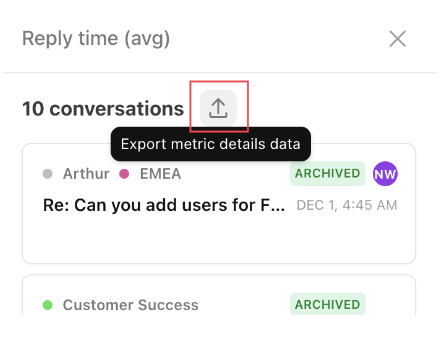
Front even allows you to export metric details to view all the conversations included in the specific metric in your report. Follow the below steps to export metric details.
- Step 1: Click on the metric in your report to pull up the metric details.
- Step 2: Click on the export icon at the top list of conversations.
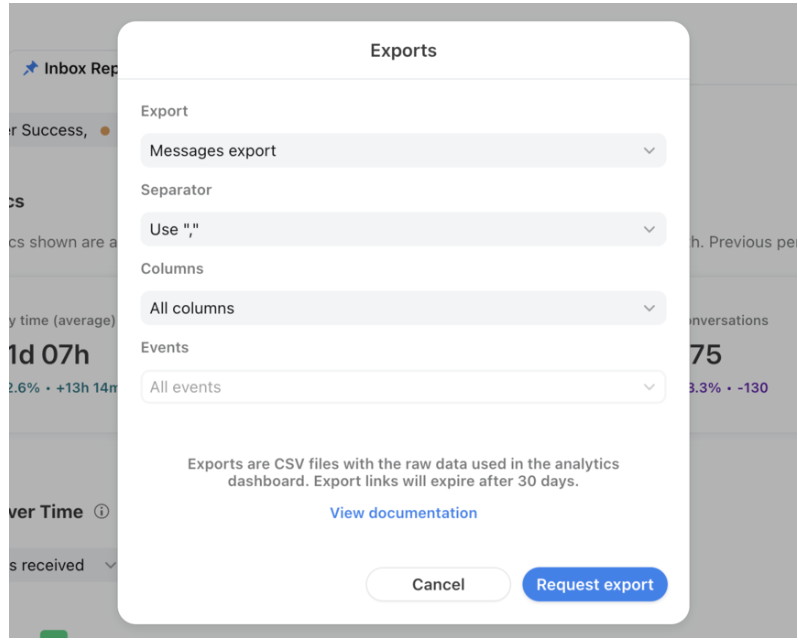
- Step 3: Select your export type in the Export Field and then click on the Request export.
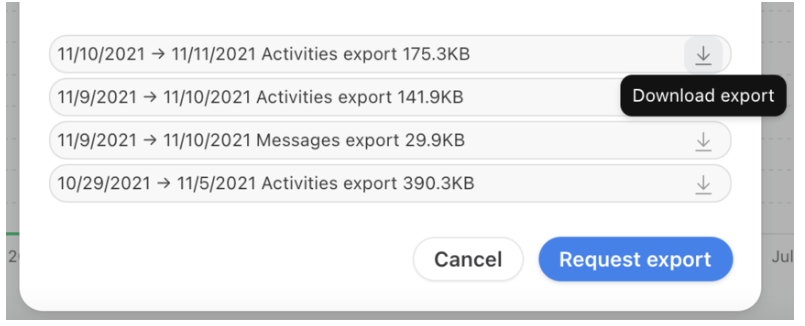
- Step 4: You can see the prepared exports at the bottom of the pop-screen. Click on the Download export arrow icon to save the export.
Front also enables users to export data from individual charts and tables in your reports. The csv file can contain the same pre-calculated metrics you can see in the corresponding chart or table on your dashboard.
Click on the export icon at the top right of the table to download its data.
Step 2: Importing data to Amazon Redshift
The next step in Front to Redshift Integration is to import the data to Redshift. Using the COPY command, you can import data to Amazon Redshift from Amazon S3 buckets.
You can start by creating an Amazon S3 bucket to store your Front data. Follow the below steps for loading a csv file to Amazon Redshift.
- Step 2.1: Please navigate to the csv file you want to import into the Amazon Redshift and load it to the Amazon S3 bucket. Zip the csv file.
- Step 2.2: When the file is in the Amazon S3 bucket, you can use the COPY command to load it to the desired table.
COPY <schema-name>.<table-name> (<ordered-list-of-columns>) FROM '<manifest-file-s3-url>'
CREDENTIALS'aws_access_key_id=<key>;aws_secret_access_key=<secret-key>' GZIP MANIFEST;You must use the ‘csv’ keyword in the COPY command to make Amazon Redshift identify the file format in Front to Redshift Integration, as shown below.
COPY table_name (col1, col2, col3, col4)
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV;
COPY table_name (col1, col2, col3, col4)
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV
INGOREHEADER 1;Limitations of Connecting Front to Redshift
Exporting Front data and importing it to Amazon Redshift manually seems easy, but in reality, this process does not allow users to work with real-time data. Therefore, users can use standard APIs to connect Front to Redshift. But, you need a strong technical team to work with APIs. As a result, to overcome all such issues, users can use third-party ETL tools like Hevo data, which allows seamless and autonomous integration between Front and Amazon Redshift.

Conclusion
In this article, you learn how to connect Front to Redshift. Front allows organizations to help their teams ensure that every customer interaction is strengthened. Many organizations use Front to bring their customer data to a unified platform to analyze it using Front Analytics. However, to obtain an in-depth analysis, you can store Front data in a centralized repository like Amazon Redshift that can be used with powerful BI tools for gaining meaningful insights and better decision-making.
If you are from non-technical background or are new in the game of data warehouse and analytics, Hevo Data can help! Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also, checkout our unbeatable pricing to choose the best plan for your organization.
Frequently Asked Questions
1. Is Redshift SQL or NoSQL?
Amazon Redshift is a SQL data warehouse. It supports structured data and does big queries, analytics, and report, so it is more like a relational database than a NoSQL.
2. What is the Google equivalent of Redshift?
The version of Amazon Redshift in Google is called BigQuery. It acts as a fully-managed, serverless data warehouse that lets SQL queries perform fast and large-scale data analytics across huge datasets, almost the same type of functionality found in Redshift.
3. Is Redshift OLAP or OLTP?
Amazon Redshift is an OLAP system. It is for big analytical workloads, complex queries, and big data reporting. Accordingly, it is best suited to handle large datasets rather than transactional loads, which are usual in OLTP systems.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





