

Since data acts as the new oil of businesses, it becomes crucial to collect, maintain, and analyze the data. Nowadays, data is growing exponentially, and it’s becoming a challenge to collect, maintain, load, and analyze data using traditional data warehouse technology. To tackle these challenges, BigQuery is playing a vital role by providing exceptional speed of data storage.
In this blog, you will go through Google BigQuery create table command, its usage, and examples. Furthermore, the blog will explain 4 easy methods using which you can create your own Tables in Google BigQuery. Also, the blog will explore how to query and load data in Google BigQuery easily. Read along to learn more about the Google BigQueryCreate Table command!
Table of Contents
What is Google BigQuery?

Google BigQuery is a highly Scalable Data Warehouse solution to store and query the data in a matter of seconds. BigQuery stores data in columnar format. It is a serverless Cloud-based Data Warehouse that allows users to perform the ETL process on data with the help of some SQL queries. BigQuery supports massive data loading in real-time.
Unlike its counterparts, BigQuery is serverless and therefore dynamic, which means users don’t need to provision or manage hardware. BigQuery is built in a way that is best suited for complex queries and analytics.
The peculiarity of this Data Warehouse is that it is linked to other Google services like Spreadsheets, Google Drive, etc., making BigQuery a very attractive and maintenance-free option for the companies and available in all places where Google Cloud is present.
To learn more bout Google BigQuery.
What are Google BigQuery Tables?
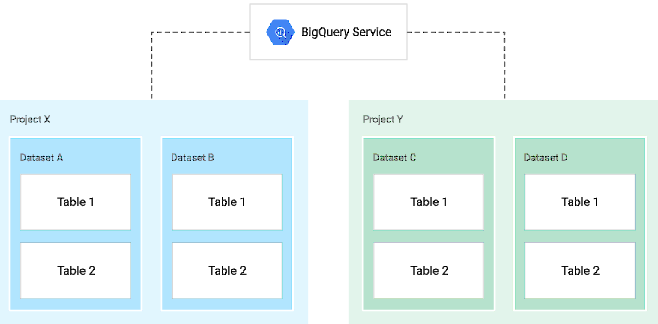
The BigQuery table contains records, organized in rows and each row has fields (also known as columns). Every table has a schema that describes the table details, such as column name, their data type, nullability, column description, clustering columns, partition column, and other details.
You can specify table schema at the time of table creation, or you can create a table using another table when it gets populated.
BigQuery table types are described below:
- Native tables: Table data stored in BigQuery native storage.
- External tables: It is not a physical table. It points to the files present at GCS (Google Cloud Storage), Google Drive, or any other GCP (Google Cloud Platform) storage options.
- Views: It is a virtual table. It is created using a query on top of BigQuery native tables.
To learn more about Google Bigquery Tables.
BigQuery Create Table Process

Before diving into the BigQuery Create Table process, you need to create a Dataset, which contains both Tables and Views. In this section, you will go through the following:
Table Naming Guidelines
Before creating a table in Google BigQuery you must understand the proper naming convention used for the Tables. The following guidelines must be followed while naming a Google BigQuery Table:
- The name of the Table must be unique in the Dataset but can be the same in different Datasets.
- Table name length can be 1024 characters long and can have a lower case, upper case letter, number, and underscore.
Methods to Implement the BigQuery Create Table Command
Below are the permissions required to execute the BigQuery Create Table command:
- bigquery.dataEditor
- bigquery.dataOwner
- bigquery. admin
Particularly in this article, you will explore the command-line tool to Create, Load, and View the BigQuery Table data.
To use the BigQuery Create Table command, you can use any of the following methods:
- Method 1: Using bq mk Command
- Method 2: Using YAML Definition File
- Method 3: Using API
- Method 4: Using WebUI
- Method 5: Uploading Data from CSV
- Method 6: Uploading Data from Google Sheets
- Method 7: Using SQL to Create BigQuery Table
Method 1: Using bq mk Command
The bq command-line tool is based on Python Programming Language and can be used to implement BigQuery Create Table Command. The bq command-line tool works with the following format:
bq COMMAND [FLAGS] [ARGUMENTS]The above syntax allows 2 kinds of flags:
- Global flags: These flags can easily be used with all bq commands.
- Command-specific flags: they are allowed with some specific bq commands only.
Steps to create a table in BigQuery using the bq mk command are listed below:
Step 1: Create a Dataset, if required.
bq mk test_datasetStep 2: Create a Table in the test_dataset Dataset.
bq mk --table --expiration 36000 --description "test table" bigquery_project_id:test_dataset.test_table sr_no:INT64,name:STRING,DOB:DATEMethod 2: Using YAML Definition File
The steps to create a table in BigQuery using the YAML definition file are listed below. Please refer to Google documentation for more details.
- Create a YAML file, refer to the below example and upload it into Google Cloud shell.
resources:
- name: TestTableYAML
type: bigquery.v2.table
properties:
datasetId: test_dataset
tableReference:
projectId: testgcpproject
tableId: TestTableYAML
description: TestTableYAML
labels:
apigateway: not-applicable
build_date: 2458647
bus_contact: lahu
businessregion: us
cloudzone: google-us
company: lahu
costcenter: finance
country: india
dataclassification: dc2
department: product-development
eol_date: not-applicable
group: application-delivery
lifecycle: development
organization: lahu
prj_code: data_analytics
productversion: 1
project: gcp-cloud-data-lake
resourcename: location-table
service: gcp-cloud-datawarehouse
sla: silver
status: development
support_contact: lahu
tech_contact: lahu
tier: bigquery
schema:
fields:
- mode: nullable
name: ID
type: string
- mode: nullable
name: UserName
type: string
- mode: nullable
name: FullName
type: string
- mode: nullable
name: UserGroupID
type: string
- mode: nullable
name: create_date_time
type: datetime
- mode: nullable
name: update_date_time
type: datetime
Execute the following command to execute a Table in Google BigQuery.
gcloud deployment-manager deployments create testtableyaml --config TestTableYAML.yamlMethod 3: Using API
If you want to implement the BigQuery Create Table command using the BigQuery API, you will need to send a JSON-formatted configuration string to the API of your choice. The jobs.insert API call can be used to insert a new Table in your Database. This method involves the following terminology:
- query: It is the actual SQL query written in the proper syntax which will create the desired Table.
- destinationTable: It is a collection space that contains multiple sub-fields to instruct the API about the location, where the query results must be saved.
- projectId: It is the unique id of the project to which the data will be exported.
- datasetId: It is the name of the dataset to which data will be export.
- tableId: It is the name of the table to which data will be exported. This Can either represent an existing table or a new one.
- createDisposition: It determines how the API will create the new Table.
- writeDisposition: It determines how the API writes new data to the table.
- WRITE_APPEND: It indicates that new data will be appended to the already existing data.
The below image shows the API options provided by Google BigQuery.

Method 4: Using WebUI
Using BigQuery WebUI to execute Create Table command makes it very easy to specify a destination table for your query result. The following steps are required to implement this method:
- Step 1: You must ensure that the Project and Dataset that you wish to treat as the destination already exist.
- Step 2: Write a Query in the normal syntax, but before executing it using the Run Query button, click on the Show Options button.
- Step 3: You will view the Destination Table section. In that, click Select Table and then a popup will ask you to choose the Project, Dataset, and specify the Table Name to use as your destination.
- Step 4: Click on Run Query and once the query is executed, the results will be appended to the table that you have specified in the previous steps.
The Google BigQuery classic WebUI is shown in the below image.

Method 5: Uploading Data from CSV
Using the GCP Console, you may construct a table in BigQuery from a CSV file. This approach simultaneously generates the table and inserts records.
On the left-hand side of the console, select the dataset. It’s the sandbox dataset in this instance.
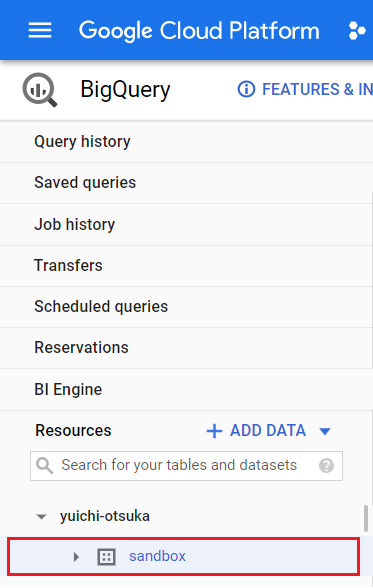
More information about the dataset will appear in the bottom-right part of your console after you select it. The Create table window will appear when you click that button.
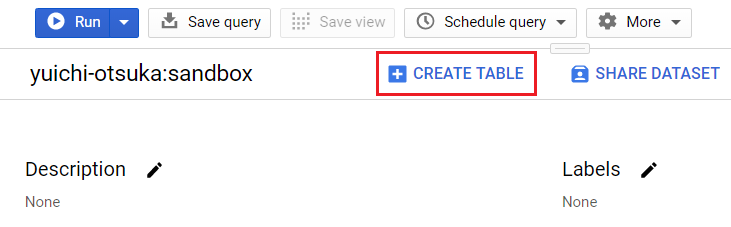
Select the Create Table option.
Source
- Upload / Drive (if in a Google Drive) to make a table
- Choose a file or a drive URI: choose your own file / link to a Google Drive file
- CSV file format
Destination
- Look for a project.
- Choose a name for your project.
- Name of dataset: choose your dataset
- Choose your own table name.
Method 6: Uploading Data from Google Sheets
Using the GCP Console, you can easily construct a table in BigQuery from a Google Sheets file. You can enter the records at the same time that you create the table. You will now see more details in the bottom-right portion of your console after selecting the dataset.
Select the Create Table option. The Create table window will appear when you click that button.
Source
- Table made from Drive.
- Choose Drive URI: the file’s URL
- File format: Google Sheet
- Sheet range: indicate your sheet and
- leave the range blank (defaults to the first sheet)
- 1st Sheet (sheet range only)
- (sheet + cell range) For Ex.: Sheet1!A1:G8
Destination
- Look for a project.
- Choose a name for your project.
- Name of dataset: choose your dataset
- Choose your own table name.
Method 7: Using SQL to Create BigQuery Table
You’ll use one of the available datasets for these simple examples, notably the GDELT Book Dataset, which contains millions of public domain books.
The query you’ll use as an example is designed to extract a few values (title, date, creator, and so on) from all tables in the dataset where the BookMeta Creator field CONTAINS the name of the author we’re looking for (Herman Melville):
SELECT
BookMeta_Title,
BookMeta_Date,
BookMeta_Creator,
BookMeta_Language,
BookMeta_Publisher
FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(d{4})") BETWEEN "1800" AND "2020"'))
WHERE
BookMeta_Creator CONTAINS "Herman Melville"The outcomes are as expected:
[
{
"BookMeta_Title": "Typee, a Romance of the South Seas",
"BookMeta_Date": "1920",
"BookMeta_Creator": "Herman Melville",
"BookMeta_Language": "English",
"BookMeta_Publisher": "Harcourt, Brace and Howe"
},
{
"BookMeta_Title": "Typee: A Real Romance of the South Sea",
"BookMeta_Date": "1892",
"BookMeta_Creator": "Herman Melville , Arthur Stedman",
"BookMeta_Language": "English",
"BookMeta_Publisher": "the Page companypublishers"
},
{
"BookMeta_Title": "Typee: A Peep at Polynesian Life, During a Four Months' Residence in the Valley of the Marquesas",
"BookMeta_Date": "1850",
"BookMeta_Creator": "Herman Melville",
"BookMeta_Language": "English",
"BookMeta_Publisher": "G. Routledge"
},
...
]Understanding the Essential Google BigQuery Table Commands
1. Show Table Schema in BigQuery
To show table schema in BigQuery, you need to execute the following command:
Syntax:
bq show --schema --format=prettyjson gcp_project_id:dataset_name.table_nameWhere
- gcp_project_id is your project ID.
- dataset_name is the name of the dataset.
- table_name is the name of the table.
Example:
bq show --schema --format=prettyjson bigquerylascoot:test_dataset.test_tableThe below image shows an instance of table schema in BigQuery.
2. Load the Data to the BigQuery Table
You can load a variety of data to BigQuery tables, such as CSV, Parquet, JSON, ORC, AVRO, etc. Here, you will see how to load CSV data to the table using the command-line tool.
bq --location=data_center_location load --source_format=source_data_format dataset_name.table_name path_to_source_file table_schemaWhere:
- location: It specifies the data center location.
- format: It specifies the source data format.
- dataset_name: It specifies the name of the dataset.
- table_name: It specifies the table name in which you want to load data.
- path_to_source_file: It specifies the path of the data file, for example, Google Cloud storage bucket URI (fully qualified) or your local file system file path.
- table_schema: It specifies the schema of the target table. Here, you can specify –autodetect schema option to automatically detect the schema of the target table.
Example: Sample data file contains below data “mydata.csv”.
1,ABC,1995-05-102,DEF,1996-10-103,PQR,1997-06-084,XYZ,1998-05-125,ABCD,1998-07-10The bq load command to load data in BigQuery is as follows:
bq load --source_format=CSV test_dataset.test_table mydata.csv sr_no:INT64,name:STRING,DOB:DATEThe following image shows the process of Loading Data into the BigQuery Table.

3. Interact with the Table in BigQuery
There are many options to interact with tables. Here, you are going to explore the command line options, i.e., bq query:
Creates a query job for the provided SQL query statement.
For example: Select the count of the table using the bq query command-line tool.
bq query --use_legacy_sql=false "select count(1) from test_dataset.test_table"Select the data from the table.
bq query --use_legacy_sql=false "select * from test_dataset.test_table"The below image shows the process of extracting data from BigQuery Table using SQL query.

Learn More About:
Conclusion
In this blog, you have learned about the Google BigQuery create table command, its usage, and examples. You also learned about how to query a table or load data in BigQuery. If you are looking for a data pipeline that automatically loads data in BigQuery, then try Hevo.
FAQ on BigQuery Create Table Command
How to create a table in Google BigQuery?
1. Go to Google Cloud console
2. Go to BigQuery
3. Select Dataset
4. Select Create Table
Is BigQuery a SQL or NoSQL?
Google BigQuery is a SQL-based data warehouse.
What BigQuery is used for?
1. Data Warehousing
2. Serverless Data Analysis
3. Real-time Data Analysis
4. Machine Learning
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



