




Grafana is an open-source solution for running data analytics, pulling up metrics that make sense of the massive amount of data & to monitor our apps with the help of cool customizable dashboards. Grafana connects with every possible data source, commonly referred to as databases such as Graphite, Prometheus, Influx DB, ElasticSearch, MySQL, PostgreSQL, etc.
Grafana Snowflake Integration allows utilizing these dashboards for more detailed information. Snowflake is one of the few enterprise-ready cloud data warehouses that brings simplicity without sacrificing features. It automatically scales, both up and down, to get the right balance of performance vs. cost.
Snowflake’s claim to fame is that it separates compute from storage. This is significant because almost every other database, Redshift included, combines the two together, meaning you must size for your largest workload and incur the cost that comes with it.
Table of Contents
Introduction to Snowflake

Snowflake‘s Data Cloud is based on a cutting-edge data platform that is available as Software-as-a-Service (SaaS). Snowflake provides data storage, processing, and analytic solutions that are faster, easier to use, and more adaptable than traditional systems.
The Snowflake data platform isn’t based on any existing database or “big data” software platforms like Hadoop. Snowflake, on the other hand, combines a completely new SQL query engine with an innovative cloud-native architecture.
Snowflake gives all of the capability of an enterprise analytic database to the user, as well as a number of additional special features and capabilities.
Data Platform as a Cloud Service
Snowflake is a real software-as-a-service solution.
- More particular, there is no hardware to select, install, configure, or manage (virtual or actual).
- There isn’t much to install, configure, or administer in terms of software.
- Snowflake is in charge of ongoing maintenance, management, updates, and tweaking.
A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate data from 150+ Data Sources (including 60+ Free Data Sources) to a destination of your choice, such as Snowflake, in real-time in an effortless manner. Check out why Hevo is the Best:
- Live Support: The Hevo team is available round the clock to extend exceptional customer support through chat, E-Mail, and support calls.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
Introduction to Grafana

Grafana is more than just a collection of features. Switch between metrics, logs, and traces with ease. Connect data and get to the bottom of the problem more quickly and easily. The de-risk feature launches by reducing mean time to recovery (MTTR).
Give your people the resources they want. Leave the platform to us so you can focus on what you do best.
Unify your data, not your database
You don’t have to ingest data to a backend store or vendor database using Grafana. Grafana, on the other hand, takes a novel approach to offer a “single-pane-of-glass” by unifying all of your existing data, regardless of where it resides.
Data everyone can see
Grafana was created on the premise that data should be available to everyone in your company, not just the Ops person.
Flexibility and versatility
Any data may be translated and transformed into flexible and versatile dashboards. Grafana, unlike other technologies, allows you to create dashboards tailored to you and your team.
Grafana Snowflake Integration
You may query and view Snowflake data metrics from Grafana using the Snowflake data source plugin.
Grafana Snowflake Integration: Requirements
The following are the prerequisites for the Snowflake data source:
- With a valid license, Grafana Enterprise can be used.
- A Grafana user with the position of severing admin or org admin.
- A Snowflake user who has been assigned the right role.
- No specific role is required for this data source.
- The role of a Snowflake user determines whether or not the user has access to tables. Ensure that your user has the required roles in order to query your data.
Step 1: Configure Snowflake
A Snowflake user with a username and password is required to configure the Snowflake data source.
For this data source, Grafana recommends creating a new user with limited rights.
Step 2: Create a user
- To connect to Snowflake, you must either create a user or login with an existing one. All queries sent from Grafana will be executed by this user.
- You should construct numerous Snowflake data sources with various configurations if you want different users to run different queries/workloads.
- You must first connect to your Snowflake instance and run the CREATE USER command to create a user.
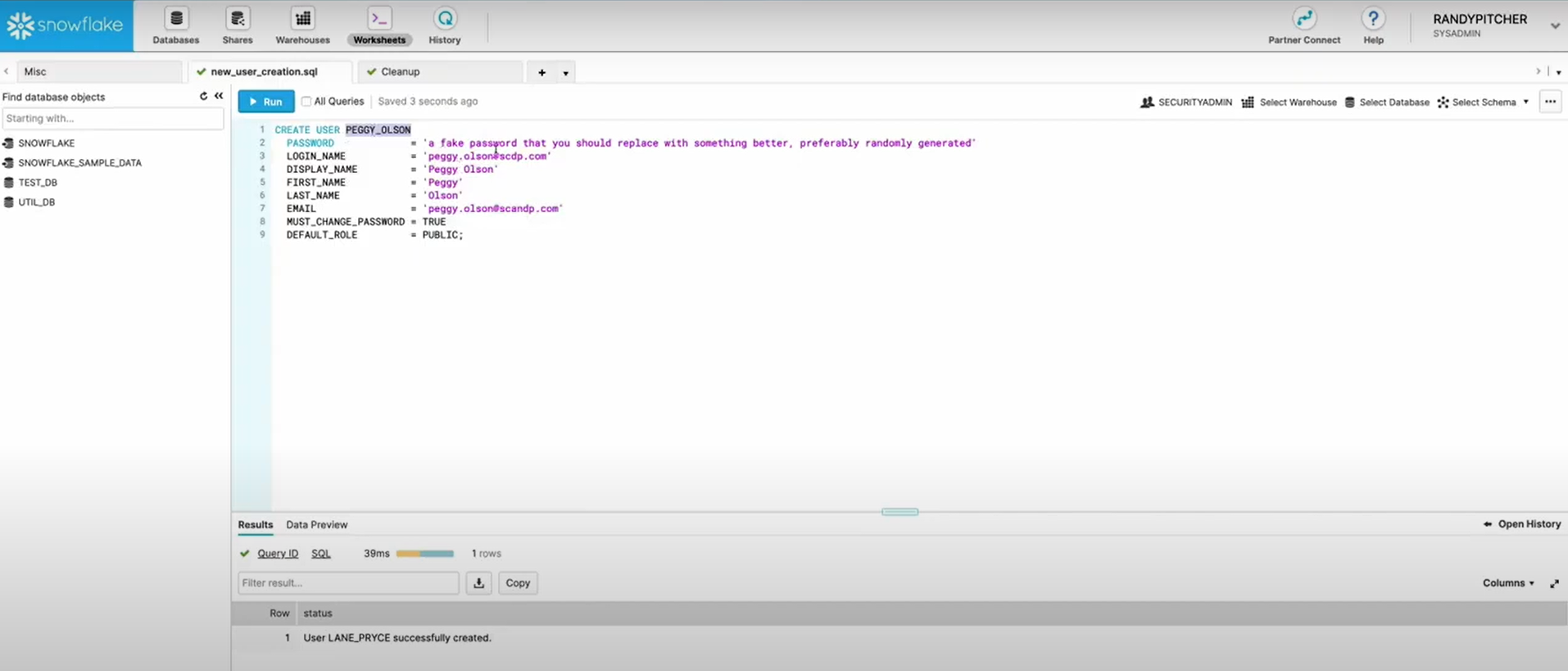
Step 3: Grant a role
- Now that the Snowflake user has been established, the GRANT ROLE command must be used to assign the user a role. When a user is given a role, the user is able to conduct the operations that the role authorizes.
- The user’s job determines which warehouses and tables he or she has access to.
Step 4: Configure the data source in Grafana
These are the same connection parameters that are used when performing Grafana Snowflake Integration
Fill in the following fields to create a data source:
- Name: A unique name for this Snowflake data source.
- Account: Account is the name of the Snowflake account that Snowflake has assigned to you. The account name is the complete string to the left of snowflakecomputing.com in the URL received from Snowflake after the account was provisioned. The region must be included in the account name if the Snowflake instance is not on us-west-2. xyz123.us-east-1 is an example. If the Snowflake instance is not hosted on Amazon Web Services, the account name must additionally mention the platform. xyz123.us-east-1.gcp is an example.
- Username: The username of the Snowflake account that will be queried.
- Password: The password for the account that will be query Snowflake
- Region: Account has been deprecated in favor of Region. The Snowflake instance’s region is specified via the region.
- Role: Taking on the role of This option enables users to connect to the Snowflake instance with a role that isn’t the user’s default. To be assumed, the role must still be granted to the user using the GRANT ROLE command.
- Warehouse: The default warehouse for queries is the warehouse.
- Database: The database that will be used by default for queries.
- Schema: The schema that will be used by default for queries.
Step 5: Configure the data source with provisioning
Grafana’s provisioning system allows you to configure data sources via config files.
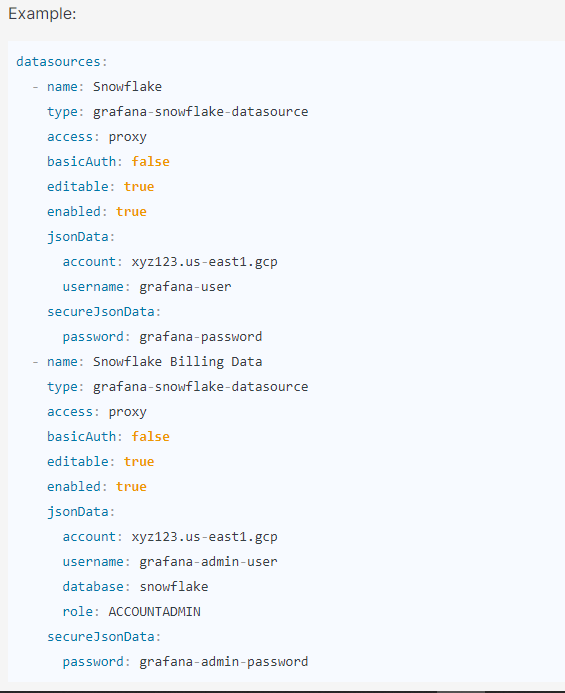
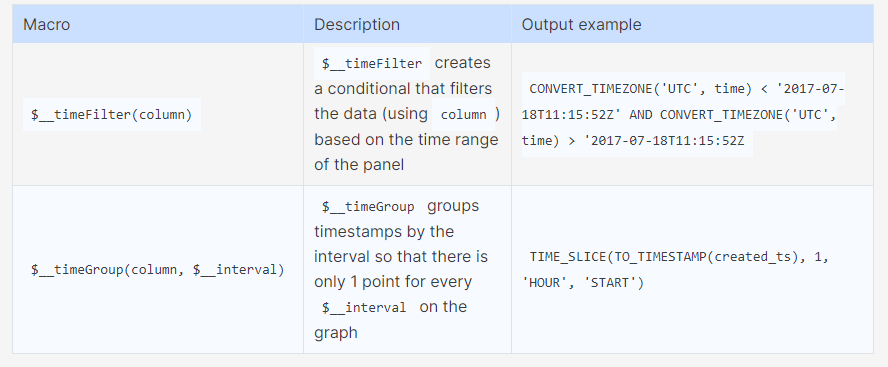
Step 6: Query the data source
The query editor that is given is a typical SQL query editor. Grafana has a few macros that can help you write more complicated time series queries.
Step 7: Inspecting the query
The complete rendered query, which can be copied/pasted directly into Snowflake, is accessible in the Query Inspector since Grafana supports macros that Snowflake does not.
Click the Query Inspector button to see the entire interpolated query, which will appear under the “Query” tab.
Conclusion
This Article gave a comprehensive overview of Grafana and Snowflake. It also gave a step-by-step guide on setting up Grafana Snowflake Integration.
While using Grafana Snowflake Integration is insightful, it is a hectic task to Set Up the proper environment. To make things easier, Hevo comes into the picture.
Hevo, being fully automated along with 150+ plug-and-play sources, will accommodate a variety of your use cases. Try a 14-day free trial and check out our unbeatable pricing to choose the best plan for your organization.
Frequently Asked Questions
1. Can I use Grafana dashboards to query large datasets in Snowflake?
Yes, but it’s recommended that you optimize queries and set appropriate timeouts to avoid performance bottlenecks when querying large data sets.
2. Can I apply Grafana transformations to Snowflake data?
Yes, Grafana makes the query results from Snowflake transformation and visual level adjustments before displaying them on dashboards.
3. What types of visualizations are available for Snowflake data in Grafana?
Grafana provides numerous visualizations like graph, table, heatmaps, and time series charts for Snowflake.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link
