

Imagine you are managing a rapidly growing e-commerce platform. That platform generates a large amount of data related to transactions, customer interactions, product details, feedback, and more. Azure Database for MySQL can efficiently handle your transactional data. But as your business grows, so does the associated data, making it difficult to process and analyze these big datasets.
AWS Redshift is a data warehouse that can help you tackle these challenges. Redshift’s columnar storage and massive parallel processing architecture (MPP) assist you in handling large-scale workloads smoothly and quickly. By migrating your data from Azure MySQL to Redshift, you can improve your operational performance and gain deeper customer insights.
This article will explore the methods for smoothly integrating data from Azure MySQL to Redshift. Let’s get started.
Table of Contents
Why Integrate Data from Azure MySQL to Redshift?
Data migration from Azure MySQL to Redshift offers several advantages that can significantly benefit organizations.
- Redshift has columnar storage, where data is stored in columns. Columnar storage allows Redshift to access only the columns needed for querying.
- Redshift’s massively parallel processing architecture allows you to handle large volumes of data in a highly concurrent environment.
- Redshift supports SQL querying for data transformation operations, providing a suitable format for data analysis, modeling, and reporting.
- After ingesting data from Azure MySQL to Redshift, you may want to perform different operations. Redshift allows you to take snapshots of a data warehouse at specific points in time and roll back in case of data loss, corruption, and more.
- It also has an automatic node failover and backup functionality, ensuring minimal downtime and data reliability in case of node failure.
Use Hevo’s no-code data pipeline platform, which can help you automate, simplify, and enrich your data replication process in a few clicks. You can extract and load data from 150+ Data Sources, including Azure MySQL straight into your Data Warehouse, such as Redshift or any Database.
Why Hevo?
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: Our team is available round the clock to extend exceptional support to our customers through Chat, Email, and Support Calls.
- Automapping: Hevo provides you with an automapping feature to automatically map your schema.
Explore Hevo’s features and discover why it is rated 4.3 on G2 and 4.7 on Software Advice for its seamless data integration. Try out the 14-day free trial today to experience hassle-free data integration.
Get Started with Hevo for FreeOverview of Azure MySQL
Azure MySQL is a fully managed database service developed by Microsoft. This means that Microsoft handles tasks related to database management so that users can focus on applications and data. Azure MySQL is also compatible with MySQL applications and tools, making it easy for developers to migrate to Azure MySQL without applying significant changes.
Overview of Amazon Redshift
Amazon Redshift is a fully managed warehouse service provided by Amazon. It allows you to modernize your data analytics workloads and deliver insights through robust features such as automated distribution, query optimization, data integration, and scalability. Redshift also seamlessly integrates with various BI tools to streamline your data workflows.
How to Integrate Azure MySQL to Redshift
Method 1: Integrating Data from Azure MySQL to Redshift Using Hevo
Hevo is a real-time ELT platform streamlining your data integration process with no-code, cost-effective, and flexible data pipelines. The data pipeline can be set up quickly and with minimal effort. Hevo also provides 150+ data sources from which you can export data to your desired destination.
Benefits of Using Hevo
- Data Transformation: Hevo offers two types of data transformation: Python-based and drag-and-drop.This feature helps you clean and enrich your source data before ingesting it into your desired destination, making it analysis-ready.
- Incremental Loading: Hevo’s incremental loading allows you to load only recently modified and updated source data into your destination instead of loading all the data again.
- Automated Schema Mapping: This feature automatically reads and replicates the source schema to the targeted destination.
Now, let’s look at the steps to connect and load data from Azure MySQL to Redshift by building a data pipeline in Hevo.
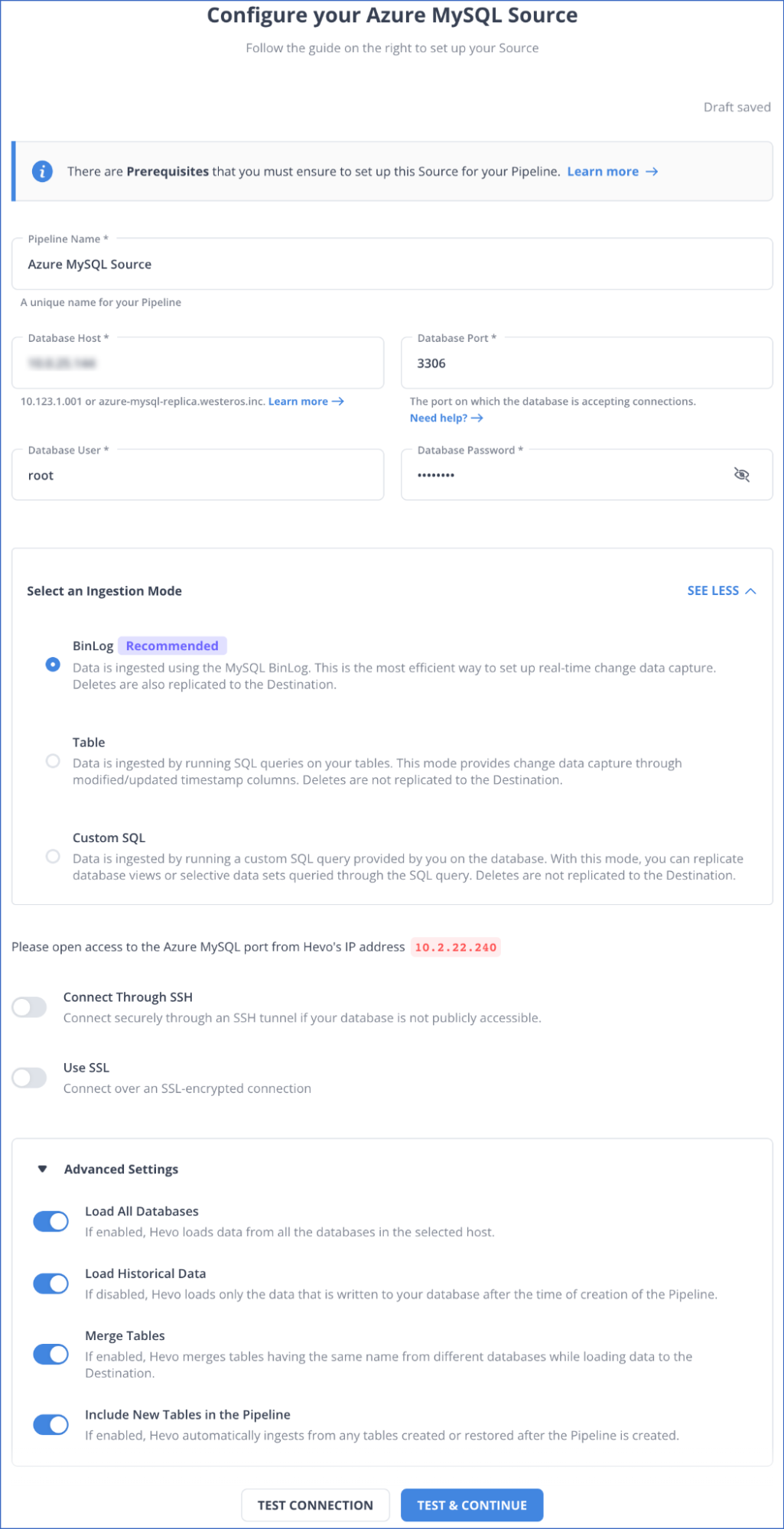
Step 1: Configure Azure MySQL as Your Source
Prerequisites
- Check if your Azure MySQL database is running.
- The MySQL version that you are using should be 5.7 or higher.
- Enable Binary Log Replication if the data pipeline is in BinLog mode.
- Check if your Hevo’s IP addresses are Whitelisted.
- Create a Database user and Grant select and replication privileges to them.
- Check if your source instance’s database hostname and port number are available.
- To create a data pipeline in Hevo, you must be assigned the role of Team Collaborator, Team Administrator, or Pipeline Administrator.
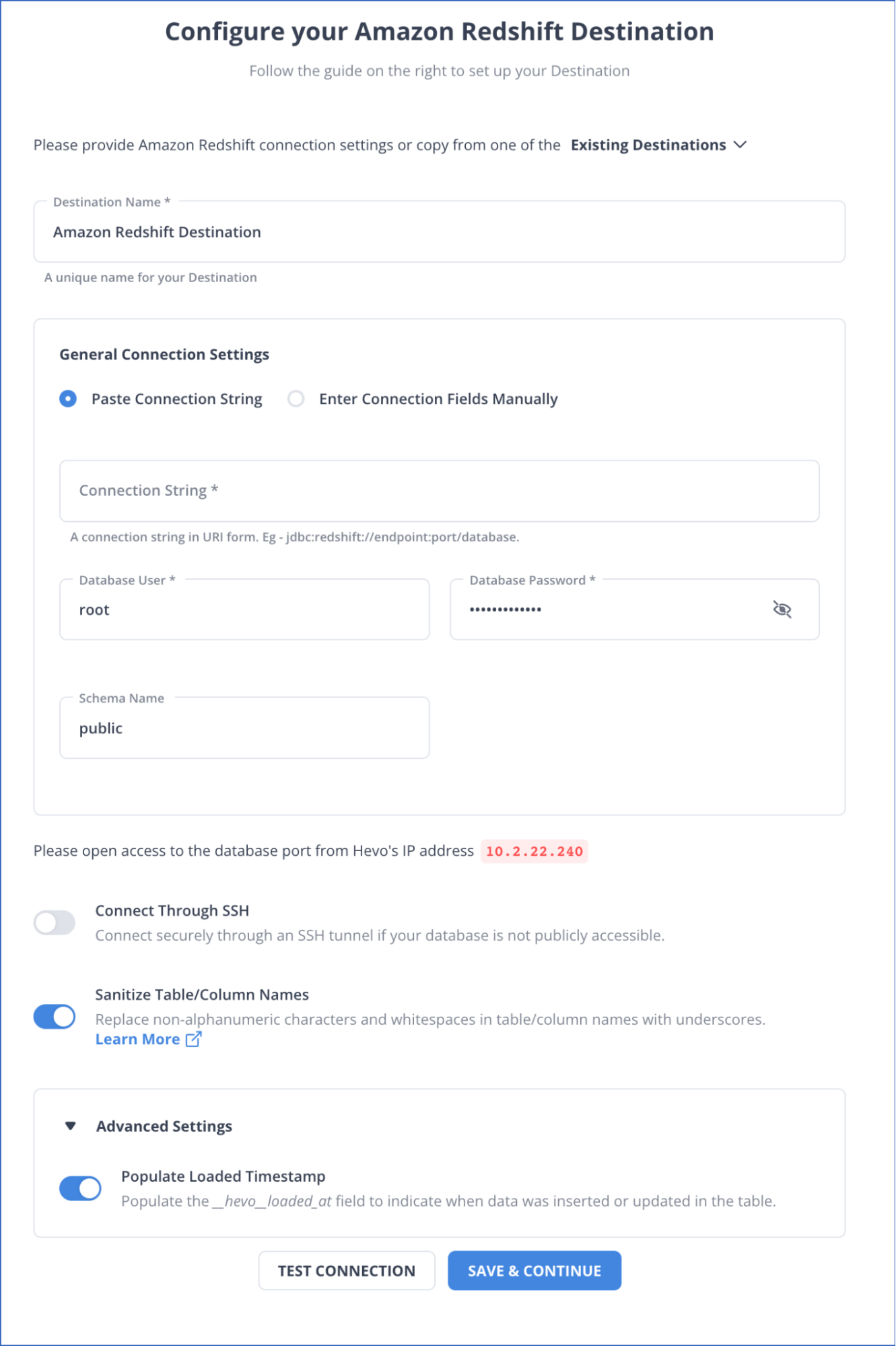
Step 2: Configure Amazon Redshift as Your Destination
Prerequisites
- Set up and check if your Amazon Redshift instance is running.
- Check if your Amazon Database instance for Redshift is available.
- Check if your database hostname and port number for the Redshift instance are available.
- Create a database user and grant SELECT privileges.
- You should be assigned any administrative role except for the Billing Administrator to create the destination in Hevo.
Hence, your data will be replicated from Azure MySQL to Redshift.
Method 2: Export Data from Azure MySQL to Redshift File Using CSV File
Step 1: Export Azure MySQL Data to a CSV File
You can export Azure MySQL data to a CSV file using MySQL Workbench.
Prerequisites
- Connect your MySQL workbench to your MySQL database, which is hosted on Azure.
- Provide details on setting the connection, such as the username and password.
You can access the Data Export Wizard from the Navigator pane on your MySQL Workbench to export data to a CSV File.
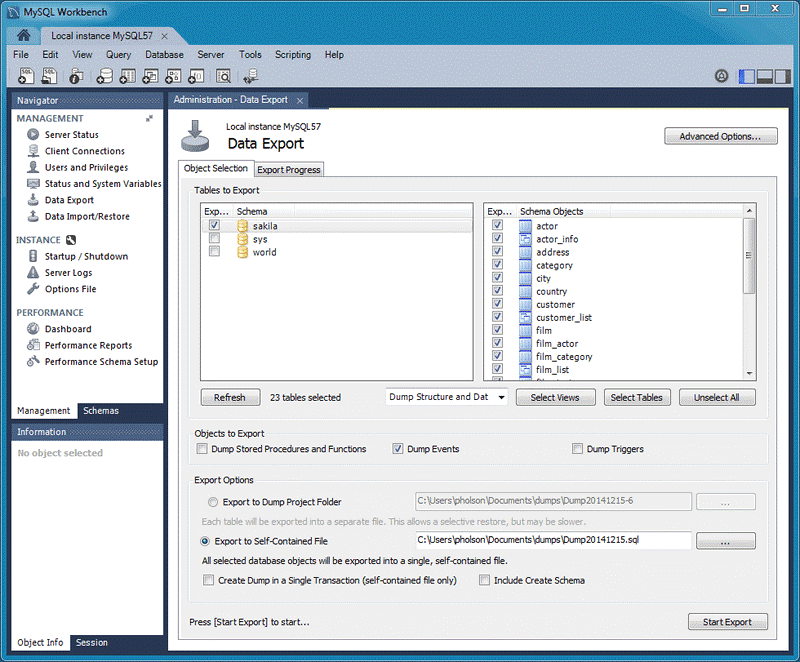
Follow the steps below:
- Go to the Navigator Pane and select the Data Export Wizard.
- Select all the schemas you want to export to the CSV file in the Data Export window.
- Choose a database object to export and configure the other related options.
- Select Refresh to load all the objects that are present.
- Click on Start Export to export and save data to a CSV file.
Step 2: Import Data from a CSV File to AWS S3 Bucket
Prerequisites
- Create a user and grant permissions to create an S3 bucket and access data from it.
- Grant COPY command permissions to the user to read the file object in the S3 bucket.
- Download and extract the CSV files from your local system.
- Create an Amazon S3 bucket in the same AWS region as your cluster.
- Create a folder where the S3 bucket will be stored.
Follow the steps below to upload the data from the CSV file to the S3 bucket.
- Go to the Upload wizard and select the Add Files option.
- Select the CSV file that you want to upload from your local system.
- Select the Upload option to load the files in your S3 bucket.
Step 3: Export Data from a S3 Bucket to Amazon Redshift Instance
Prerequisites
- Check if you have the necessary IAM role permissions to upload data into your Redshift Instance.
- Create and Launch the Amazon Redshift cluster along with database tables.
- Check if you have an SQL client, such as the Redshift console query editor.
You can create tables in your database and copy data into them using the COPY command on the Amazon Redshift query editor.
Load Data to Your Redshift Database Instance from an S3 Bucket
- Load the data from the S3 bucket to the Redshift table and execute the command below.
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options] Here:
- table_name refers to the targeted table in your Redshift DB instance.
- column_list refers to the column in the targeted tables where you want to map the data.
- data_source refers to the data path of the data file.
- access_credentials refers to the AWS access credentials that are required for authorization.
Limitations for Method: Export Data from Azure MySQL to Redshift File Using CSV File
- If you want to import data in a CSV file using the data wizard on the MySQL workbench, you need to manually configure mapping options and column selection. This can be difficult for individuals who are unfamiliar with data wizards’ functionalities.
- You need Insert privileges and other permissions to use the COPY command with the Amazon Redshift cluster. Configuring and maintaining access rights in an environment where users have varied levels of data access can be challenging.
- You cannot directly import the data from CSV files to the Amazon database instance for Redshift, making the process more lengthy and complicated.

Use Cases
- Sales Analysis: You can consolidate and transform your data to perform complex data analysis to identify trends or recurring patterns, manage inventory, and more.
- Financial Data Aggregation: By integrating data from Azure MySQL to Redshift, you can run queries on your financial data to detect risks and fraud, analyze investment portfolios, generate compliance reports, and more.
- Marketing Data Analysis: By moving data from Azure MySQL to Redshift, you can customize your marketing campaigns, identify high-value customer segments, and optimize your campaign spending.
Here are some other migrations that you may need:
Conclusion
Integrating data from Azure MySQL to Redshift enables you to generate valuable insights with many practical uses across varied industries. You can integrate your Azure MySQL data either by using CSV files, which can be a complicated and lengthy process, or by using Hevo. Its automated no-code data pipeline enables seamless data integration between your source and destination.
Try a 14-day free trial and experience the feature-rich Hevo suite firsthand. Also checkout our unbeatable pricing to choose the best plan for your organization.
FAQs (Frequently Asked Questions)
1. How do I load new records and archive the old ones for Amazon Redshift?
To load the new record and achieve the old one, you might need to use a variation of Amazon Redshift. First, you must identify all the records that need archived and move them temporarily in the S3 Bucket using the Unloading method. Then, you can upload new records to the main table using Alter Append.
2. How can I upload the modified data from MySQL to Redshift?
You can use the Change Data Capture (CDC) technique to capture changes in MySQL data and apply them to the Redshift table. To use CDC, you must utilize a Binary log (Binlog) that allows you to capture streams and enable real-time replication.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





