
Imagine you’re managing a massive lake of data, but without a solid catalog, you find yourself:
- Facing difficulty in data discovery as data is scattered makes it hard to find what you need when needed.
- Experiencing performance bottlenecks, as queries take forever, slowing down your analysis.
- Dealing with inconsistent data, that is, updates and changes, is chaotic, leading to inaccurate insights and unreliable reports.
But, with an Iceberg Catalog in place, you can:
- Keep all your metadata in one place, making locating and accessing the data you need simple.
- Quickly retrieve data thanks to efficient metadata management, speeding up your analysis and insights.
- Maintain accurate and reliable data with robust transaction support, eliminating errors and improving confidence in your results.
An iceberg catalog is a sophisticated metadata management system for your data lake, meticulously tracking critical information such as data structure, lineage, and location.
This article will delve into all aspects you need to know about iceberg catalogs for effective data management.
Table of Contents
What is an Iceberg Catalog?
To manage and track metadata for large datasets efficiently, the Apache Iceberg framework consists of a key part called the iceberg catalog. It’s designed to keep track of all the important details, like how the data is structured, what it means, and its history. In 2017, smart folks at Netflix and Apple created Iceberg because they needed a better way to handle huge amounts of data than older systems like Apache Hive. The catalog ensures everything stays accurate and consistent, so you can trust your data is safe and reliable.
Now, how’s it different from regular data catalogs? While traditional catalogs are often used to manage data across different systems, Iceberg Catalogs are more focused. They’re specifically designed to handle the details of Iceberg tables. This means they can keep things running smoothly and efficiently within the Iceberg world. So, while other catalogs might help you find data from all sorts of places, Iceberg Catalogs are all about ensuring your Iceberg data is well-organized and easy to work with, without sacrificing speed or accuracy.
Managing massive datasets just got easier! Hevo now supports Apache Iceberg as a destination, empowering you to build a high-performance, scalable data lakehouse effortlessly.
Why Iceberg?
- Faster Queries, Less Scanning – Iceberg’s smart metadata handling means Hevo loads only what’s needed.
- Schema & Partition Evolution – Adapt without breaking pipelines! Iceberg tracks change intelligently.
- ACID Transactions & Time Travel – Query historical data or roll back changes seamlessly.
With Hevo + Iceberg, unlock flexible, efficient, and reliable data management at scale. Ready to modernize your data stack? Try it today!
Get Started with Hevo for FreeWhy Do You Need to Use Iceberg Catalog?
It’s all about making your data management easier and more efficient. It helps you keep track of your data with a clear structure, allowing for faster queries and better organization. Plus, it supports features like versioning and time travel, which means you can easily access previous versions of your data whenever you need to. Overall, using the iceberg catalog can save you time and hassle while ensuring your data is secure and easy to work with.
Technical Architecture of Iceberg Catalog
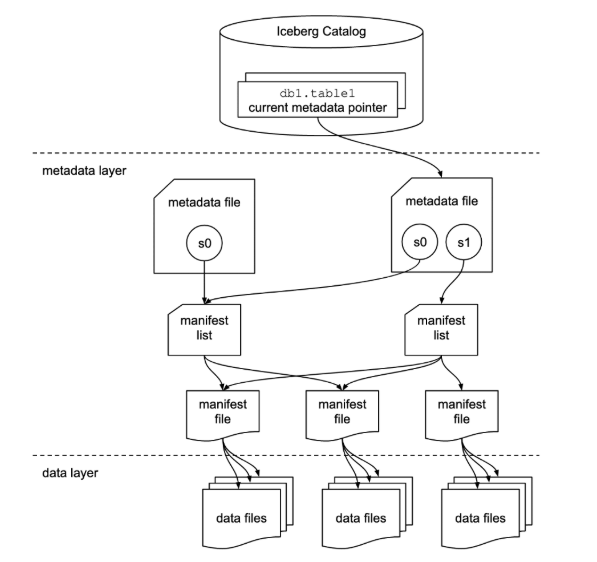
It can be integrated with various backend systems, making it a flexible and adaptable option for different processing engines supporting it.
To understand its internal structure, let’s explore the technical architecture that efficiently manages and accesses data:
- Catalog Layer:
This is the first point of contact for compute engines. It keeps track of the current metadata for each table, ensuring that data remains consistent. The catalog manages collections of tables, often organized into namespaces. - Metadata Layer:
This layer contains three main types of files:- Metadata Files: These files store important information about the table, such as its schema, location, and partition details.
- Manifest Lists: These are snapshots of the table at specific times and include a list of all manifest files and their partition information.
- Manifest Files: These files provide metadata at the file level, including statistics like row counts and details about each data file.
- Data Layer:
This is where the actual data is stored, supporting formats like Parquet, ORC, and Avro. Iceberg organizes data files to present them as a single table, allowing for efficient storage and processing.
When you run a query, the compute engine interacts with the catalog to find the current metadata. This leads to the metadata files, which point to manifest lists and manifest files, ultimately guiding you to the data in the data layer.
Types of Iceberg Catalogs
Understanding the different types of catalogs is super important because it helps you pick the right one for your data. Let’s take a look:
- Hadoop Catalog
This catalog stores metadata files in Hadoop Distributed File System (HDFS) or other Hadoop-compatible systems.
Benefits: It’s ideal for on-premise setups that already use Hadoop infrastructure, providing a familiar environment for users. - Hive Catalog
The Hive Catalog utilizes the Hive Metastore to manage metadata.
Benefits: If you already have Hive in place, this catalog is an excellent choice as it integrates seamlessly, allowing you to leverage existing data management tools. - AWS Glue Catalog
This catalog integrates with AWS Glue Data Catalog to manage metadata in cloud environments.
Benefits: It’s perfect for users in AWS, offering serverless management and easy scalability without worrying about infrastructure. - JDBC Catalog
The JDBC Catalog allows any JDBC-compatible database to serve as a catalog.
Benefits: This flexibility means you can use your existing databases for metadata management, making integrating various data sources easier. - Snowflake Catalog
Snowflake Data Catalog can act as an Iceberg catalog, combining its powerful query capabilities with Iceberg’s features.
Benefits: It provides full platform support with read and write access, simplifying maintenance and enhancing performance for large datasets. - Custom Implementations
You can also create custom catalogs tailored to your needs or proprietary systems.
Benefits: This option offers maximum flexibility, allowing you to design a catalog that perfectly fits your unique data architecture.
How to Choose the Right Catalog For Your Use Case?
Choosing the right catalog for your use case is crucial because selecting the wrong one can lead to severe headaches, like slow performance, difficulty accessing data, and extra maintenance work.
It’s essential to ask yourself:
- How will this catalog fit into my existing data setup?
- What specific needs does my team have?
- Will this catalog support my future growth?
Here’s how to choose the right catalog in simple steps:
- Assess your current data setup. Ask if you’re using cloud services like AWS or on-premise solutions. This will help you determine which catalog types are compatible with your infrastructure.
- Think about what you need from your catalog. Understand if you require high performance for large datasets or if ease of integration is more important. Knowing your priorities will guide your choice.
- Evaluate features as different catalogs offer various features. For example, some may support versioning and time travel, while others might focus on performance and scalability. Make a list of must-have features based on your requirements.
- Choose a catalog that can grow with your data needs. If you expect your data volume to increase significantly, look for catalogs that can handle large-scale operations without a hitch.
- Run a pilot project with a few catalogs to see how they perform in your environment. This hands-on experience can provide valuable insights into which catalog works best for you.
How To Implement Iceberg Catalog?
Before you implement an iceberg catalog, there are a few must-know steps to ensure a smooth process. Start by understanding your data architecture and how Iceberg fits into it. Followed by gathering the necessary tools and resources, like compatible storage systems and data processing engines.
Here, we’ll guide you through how to implement it with your data architecture or independently by simply following these steps:
- Set Up Your Environment
Choose a cloud provider or on-premises solution that supports Iceberg. Ensure you have the right tools installed, like Apache Spark or Flink. Follow the installation guides for your chosen tools to get everything ready for Iceberg. - Create Your Iceberg Tables
Define the schema for your data tables, including the columns and their data types. Use Iceberg’s API or SQL commands to create tables in your chosen environment. Make sure to specify partitioning options if needed. - Load Your Data
Move your existing data into the new Iceberg tables you created. Use data ingestion tools or scripts to load data from your source systems into the Iceberg tables, ensuring it matches the defined schema. - Manage Metadata
Keep track of your table metadata, which includes information about schema changes and snapshots. Use Iceberg’s built-in features to automatically manage metadata as you add or modify data in your tables. - Test Your Setup
Run queries against your Iceberg tables to ensure everything is working as expected. Use sample queries to check results’ performance and accuracy, making necessary adjustments. - Monitor and Optimize
Regularly check the performance of your catalog and make improvements where needed. Set up monitoring tools that track query performance and resource usage, allowing you to optimize as your data grows.
Challenges Associated with Iceberg Catalog
You may feel ready to enjoy its benefits once you integrate the catalog within your data architecture. However, it can also lead to challenges that might overwhelm you.
The top five challenges are:
- Integration Complexity: Connecting Iceberg with your existing data systems can be tricky, especially using different tools or cloud platforms.
- How to mitigate it: Take your time to plan the integration carefully. Use documentation and community resources to understand how Iceberg works with your current setup.
- Resource Management: Managing snapshots and metadata can consume a lot of resources, slowing down performance and increasing costs.
- How to mitigate it: Regularly monitor your resource usage and set limits on how many snapshots you keep. This will help balance performance and cost.
- Learning Curve: Understanding Iceberg’s features and architecture can be difficult for teams new to large-scale data systems.
- How to mitigate it: Provide training sessions or workshops for your team. Encourage them to explore Iceberg’s documentation and practice using it in a test environment.
- Operational Overhead: Maintaining Iceberg tables, like compacting metadata or managing schema changes, can require extra work and resources.
- How to mitigate it: Automate routine maintenance tasks where possible. Set up alerts for when manual intervention is needed so you can stay on top of things without constant monitoring.
Best Practices for Implementing Iceberg Catalog
Understanding and applying best practices is super important to setting up and managing iceberg catalogs effectively. At first, implementing catalogs can feel tricky, but it doesn’t have to be complicated!
Once you know the best practices, your data will stay organized, easy to find, and safe.
Here are seven simple tips to help you get it right:
- Pick the Right Catalog: Choose a catalog that fits your setup. If you’re using cloud services like AWS, go for catalogs like AWS Glue because they usually work better there.
- Keep Metadata Tidy: Metadata is like a map for your data. As your data grows, this map can get messy. Clean it up regularly to keep things running smoothly.
- Partition Your Tables: Partitioning is like organizing your data into folders based on how you search for it. Iceberg can do this automatically!
- Watch Your Snapshots: Snapshots are like save points in a game. They let you go back to previous versions of your data. But too many snapshots can slow things down.
Conclusion
Iceberg catalogs are essential because they help you:
- Organize your data easily.
- Speed up your queries.
- Keep your data consistent.
This is where its implementation and being aware of potential challenges become critical. Be vigilant about best practices like right catalog choice,” “metadata management,” and “regular maintenance.” to make the most of it. With these, you can gain valuable insights by making data more accessible and queries faster, helping you spot significant trends.
Have data integration questions? Contact our Hevo experts to take your data management journey from complex to straightforward.
FAQs
1. What is a catalog in Iceberg?
An Iceberg catalog is a system that manages metadata for datasets stored in Iceberg tables. It helps keep track of important information like table structure and data versions, making it easier to manage and query data.
2. Is Iceberg a catalog?
No, Iceberg itself is not a catalog; it is a table format for managing large datasets. However, it uses catalogs to store and manage metadata about the tables it creates.
3. What is the difference between the Iceberg catalog and the Hive catalog?
The Iceberg catalog specifically tracks metadata for Iceberg tables, while the Hive catalog is designed to manage metadata for tables in the Hive ecosystem. They serve different systems but can work together in some setups.
4. Is Iceberg better than Parquet?
Iceberg and Parquet serve different purposes; Iceberg is a table format that manages data efficiently, while Parquet is a columnar storage file format. They can be used together, with Iceberg organizing data stored in Parquet files for better performance.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





