

Apache Iceberg and Parquet are popular storage formats in the big data industry. However, they are also often confused terms. So today, we’ll compare these two storage formats, their features, and their unique capabilities.
Moreover, they are not competing technologies but complementary ones. They can be used together to maximize the use of both table and file formats. We’ll also discuss a real-world use case to illustrate how they can work together.
Apache Iceberg vs. Parquet is a comprehensive guide that outlines the characteristics of both storage formats and their differences. Without further ado, let’s dive in.
Table of Contents
Apache Parquet

Parquet was developed by Twitter and Cloudera and made open source by donating it to the Apache Foundation. It is designed to work well with popular big data frameworks like Apache Hadoop, Apache Spark, and others.
Like CSV or Excel files, Apache Parquet is also a file format. CSV files are set up in rows, while Parquet files are column-oriented. When you use column-based storage, each column’s values are stored together in contiguous memory locations.
Parquet’s unique columnar format quickly became popular because it is best suited for analytical tasks and is one of the fastest file formats to read data.
It is also popular for using compression and encoding techniques to use storage space efficiently. Storing a column’s values together saves similar data types, resulting in a higher compression ratio.
Querying Parquet data is faster because it fetches only the specific column values required to answer the query, not the entire row of data.
Apache Iceberg

Iceberg organizes a set of data files into a table format. It is designed to bring the simplicity of SQL to big data and offer a structured way to store and query data effectively in a distributed environment.
Netflix created Iceberg and donated it to the Apache Foundation in 2018. The idea is to improve performance, handle large-scale data, and offer database capabilities like ACID compliance to data files.
How exactly does the Iceberg store your data? Similar to Parquet, data is stored in files. However, we cannot store all the data in a single file. Hence, Iceberg organizes these data files into a table format. It maintains the metadata about each data file and defines the partitions based on columns, providing traditional database capabilities to data files. Read in-depth about Iceberg’s architecture.
Reading and writing to files is faster with Iceberg. When you insert data into an Iceberg table, its metadata files are updated accordingly.
When you later want to read the data, the iceberg first searches its metadata to find the specific data file and only queries it, reducing the number of I/O operations. This way, querying the Iceberg table is optimal.
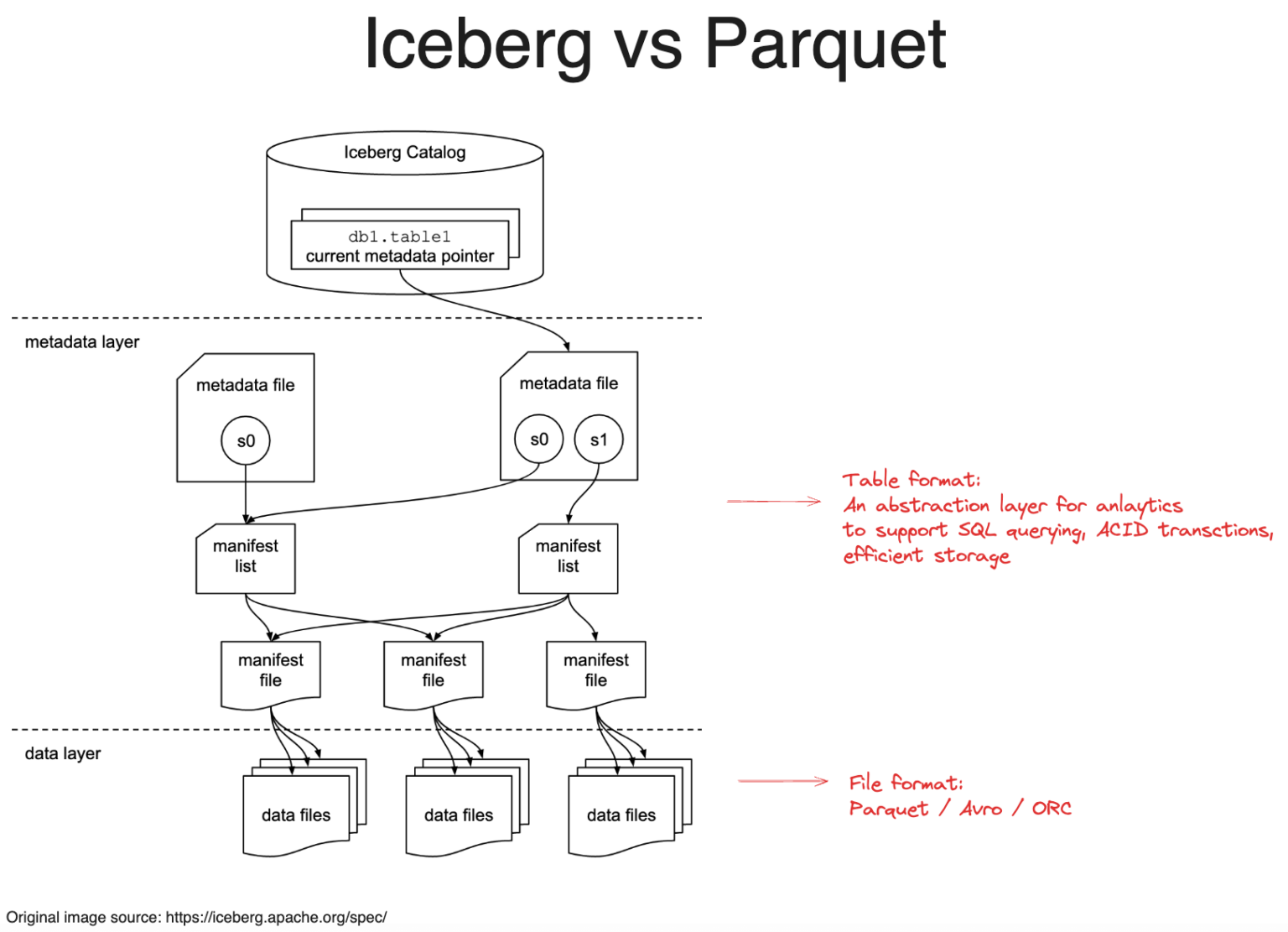
The below image compares Apache Iceberg’s table format and Parquet’s file format, highlighting how Iceberg manages metadata and data layers for advanced analytics.
Managing massive datasets just got easier! Hevo now supports Apache Iceberg as a destination, empowering you to build a high-performance, scalable data lakehouse effortlessly.
Why Iceberg?
- Faster Queries, Less Scanning – Iceberg’s smart metadata handling means Hevo loads only what’s needed.
- Schema & Partition Evolution – Adapt without breaking pipelines! Iceberg tracks change intelligently.
- ACID Transactions & Time Travel – Query historical data or roll back changes seamlessly.
With Hevo + Iceberg, unlock flexible, efficient, and reliable data management at scale. Ready to modernize your data stack? Try it today!
Get Started with Hevo for FreeFile Formats vs Table Formats
A file format represents how data is stored within a file. It defines how the data is organized and encoded on local disks or in distributed cloud environments like Amazon S3. For example, the CSV file format stores data as comma-separated values, and the Parquet file format is a column-oriented storage structure.
File format and table format are not two different worlds. When we say file format, we mean an individual file, like a Parquet file, ORC file, or even a text file. A table format, on the other hand, is an organized collection of these files.
In the table format, the abstraction layer shows the data files partitioned into columns, so SQL queries it as if it were a traditional database. This setup brings ACID properties and schema evolution capabilities to the storage system.
File formats represent a lower level of data storage, while table formats handle the abstraction layer by managing metadata and transactional consistency.
The file and table format choice depends on what you want to achieve. File format suffices for simple storage, but data needs to be organized in a table format for large-scale data and complex data processing tasks.
| Aspect | File Format | Table Format |
| Definition | Stores data in individual files (e.g., CSV, Parquet) | Organizes files with metadata and acts like a database |
| Storage | Local disks or cloud (e.g., S3) | Distributed storage, partitioned for SQL queries |
| ACID Support | Not inherently supported. | Supports ACID properties, providing data consistency. |
| Schema Evolution | Limited or manual schema handling. | It supports schema evolution and manages changes over time. |
Key Comparison: Iceberg vs Parquet
Now comes the core comparison between Iceberg and Parquet. Here’s a detailed table outlining their differences.
| Apache Parquet | Apache Iceberg | |
| Definition | Parquet is a columnar storage file format optimized for data storage and compression. | Iceberg is a table format for efficient querying and data management. |
| Schema evolution | Parquet supports adding and deleting columns in schema evolution. | Iceberg supports adding, deleting, renaming, and changing the data type of columns. It tracks the schema changes over time. |
| Metadata management | Stores basic metadata like the statistics of each column. | Iceberg maintains snapshots at different intervals, allowing you to restore the previous version in case of data loss. |
| ACID compliance | Doesn’t support ACID properties. | Native support for ACID properties, ensuring consistency, accuracy, and isolation during concurrent operations on the data. |
| Read and write operations | Efficient for read operations. | Optimizes both read and write operations |
Time travel | It doesn’t natively support time travel. | Iceberg maintains snapshots at different intervals of time, allowing you to restore the previous version in case of data loss. |
Parquet vs Iceberg: Detailed Comparison
Storage Format
Apache Parquet is a column-based file format. Generally, file formats focus on efficient data storage and compression.
So, the Parquet format leverages encoding techniques like dictionary encoding, run length encoding, or delta encoding for efficient space utilization. It also supports compression algorithms like Snappy, Gzip, and LZ4 for a high compression ratio and minimal file size.
On the other hand, Iceberg partitions data files into columns and provides a table structure, so it’s easy to query data using SQL. However, the data files are typically in formats like Parquet, ORC, etc.
Hence, Parquet focuses on the low-level storage format, while Iceberg adds logical layers to enable SQL querying and transactional consistency.
Query performance
The Parquet format offers efficient read operations. With a column-oriented format, Parquet minimizes the data accessed during query executions. This means you can read only the columns needed to answer a query instead of the entire row.
The Iceberg format improves query performance by pruning data files and evolving partitions. Before execution, pruning techniques filter out the data files needed for the query.
This initial filtering reduces the I/O operations required for execution. Moreover, any changes you make to the data update the partition schema without needing to rewrite the entire data set.
Schema evolution
Schema evolution means changing the structure of the table without interrupting existing data. Apache Iceberg and Parquet formats support schema evolution, but Iceberg is more robust and flexible than Parquet.
Iceberg supports in-place schema evolution just like SQL. It can evolve by changing nested structures and partition specifics as the data volume grows or shrinks, all without performing costly operations like rewriting or migrating tables.
Parquet supports limited schema evolution. For example, you can add columns to the schema without rewriting the table. However, you cannot rename the columns. For this, you should add a new column with empty values and fill in data from the old column.
Apache Iceberg vs Parquet for Streaming Data
Streaming data means a continuous flow of high-volume data, which is highly popular in real-time analytics. Iceberg is designed to handle petabyte-scale data efficiently, making it suitable for constant streaming data.
Streaming data is written to target systems as generated, requiring continuous write operations. The Iceberg format processes efficient write operations while ensuring ACID compliance. That’s why the destination gets consistent and accurate data in real-time when Iceberg is used.
Moreover, streaming data frameworks like Apache Kafka and Apache Flink are highly compatible with Apache Iceberg. So it’s easy to ingest streaming data into Iceberg. The ingested data can be stored in Parquet format files for efficient storage and retrieval.
Schema and partition evolution of Iceberg helps remove downtime in the streaming data, ensuring continuous data flow.
Relationship between Parquet and Iceberg
Although Parquet and Iceberg storage formats can be different, they can easily blend together to form a solid data storage system.
Iceberg is an open table format, meaning it organizes a collection of files into a table format. However, each file will still be in some format, like Parquet or ORC.
Many modern architectures choose Parquet as their low-level storage structure and use Iceberg to provide a table format for a group of these Parquet files. That is, the actual data is stored in Parquet files, and Iceberg organizes these Parquet files into a table format.
Iceberg vs Parquet: Which One Should You Choose?
When deciding between Iceberg and Parquet, it’s important to consider your specific use case and needs. Here’s a simple breakdown:
1. Iceberg
- Best for managing large-scale, complex data with support for schema evolution and ACID transactions.
- Ideal for data lakes where you need efficient querying and versioning of datasets.
- Recommended when you need strong support for data governance, auditability, and incremental data loads.
2. Parquet
- A columnar storage format optimized for read-heavy workloads and analytics.
- Best for high-performance queries on large datasets.
- Works well with distributed processing frameworks like Apache Spark.
When to Use Both Together
- You can use Parquet as the storage format within an Iceberg table. Iceberg organizes your data, and Parquet stores the actual data in an efficient, compressed format.
- Use Iceberg for managing large datasets with versioning and transactional support, while leveraging Parquet for its performance in analytical queries.
Both can complement each other, with Iceberg managing the metadata and Parquet providing the efficient data storage for high-performance queries.
Conclusion
In conclusion, Apache Iceberg is in table format, while Parquet is in file format. Apache Iceberg excels at providing schema evolution, ACID compliance, and metadata management for data files.
Parquet format focuses on compression mechanisms and encoding techniques to maximize storage space utilization.
The choice between Iceberg and Parquet depends on your specific use case. Modern businesses can use Iceberg and Parquet for efficient data management and analytics.
To learn more about migrating data from various formats to multiple destinations, sign up for Hevo’s 14-day free trial.
FAQs
1. Does Iceberg use Parquet to store the data?
Iceberg is an open table format. It is not restricted to any specific file format and can provide table structure to any file format, such as ORC, Parquet, Avro, and more.
2. Which is better, Apache Iceberg or Parquet?
For simple storage and efficient column read operations, Parquet does the job. However, you must use Iceberg tables to bring SQL capabilities to the large-scale data.
3. Is Parquet columnar or hybrid?
Parquet is a columnar storage file format highly optimized for query performance and data processing.
4. Does Snowflake use Parquet?
Snowflake natively supports Apache Parquet format for data storage and querying, allowing users to create tables directly from Parquet files or load Parquet data into existing tables.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





