



 Key Takeaways
Key TakeawaysTo connect Parquet files to PostgreSQL, you can use methods like foreign data wrappers such as DuckDB or pg_parquet, which enable reading and copying data directly from Parquet files.
Few methods covered in the blog are:
Method 1: Using DuckDB Foreign Data Wrapper (FDW)
Install the DuckDB FDW extension in PostgreSQL to create a foreign table that directly queries Parquet files, allowing for efficient data retrieval and integration into PostgreSQL without the need for intermediate storage.
Method 2: Using Python with Pandas and psycopg2
Utilize Python’s Pandas library to read Parquet files and the psycopg2 library to connect to PostgreSQL, enabling programmatic data transformation and insertion into PostgreSQL tables.
PostgreSQL is a database management system based on relational and object-oriented databases. To manage and modify complex data sets, it uses advanced SQL queries. Apache Parquet is a free, open-source column-oriented data file format that is compatible with the majority of data processing frameworks in the Hadoop environment. It has a striking resemblance to other column-oriented data storage formats available in Hadoop like ORC and RCfile.
This blog tells you about steps you can follow for Parquet to Postgres data migration. In addition to giving an overview on PostgreSQL and Parquet, it also sheds light on why Parquet is better than other Data Formats.
Table of Contents
Understanding the Basics of Parquet and Postgresql
- PostgreSQL: PostgreSQL is an open-source relational database management system that is popular for its reliability and scalability. It has the capabilities in managing structured data and is opted by many companies.
- Parquet: Parquet is an open-source columnar storage file format that can store and process big datasets effectively. It will be useful for analytical workloads and is a popular choice for data warehousing and data lakes.
- DuckDB: DuckDB is an open-source project which mainly focuses on analytical query processing. This can manage high-performance analytical workloads, and work with complex queries.
- DuckDB FDW: This is a foreign data wrapper extension to sync PostgreSQL to DuckDB databases.
What Types of Data are Imported in PostgreSQL?
PostgreSQL has an Import/Export tool built into dbForge Studio that supports file transfer between most frequently used data formats. It allows you to save templates for repetitive export and import tasks. With this, you can easily migrate data from other servers, customize import and export jobs, save templates for recurring scenarios, and populate new tables with data.
Data formats that are compatible with PostgreSQL are:
- Text
- HTML
- MS Excel
- XML
- CSV
- JSON
- Parquet
How To Import Parquet to PostgreSQL?
Here are a few ways you can integrate PostgreSQL Parquet:
- Parquet to PostgreSQL Integration: Querying Parquet Data as a PostgreSQL Database
- Parquet to PostgreSQL Integration: Using Spark Postgres Library
Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs.
Check Out Some of the Cool Features of Hevo:
- Transformations: Hevo provides preload transformations through Python code. It also allows you to run transformation code for each event in the Data Pipelines you set up. Hevo also offers drag-and-drop transformations like Date and Control Functions, JSON, and Event Manipulation, to name a few.
- Incremental Data Load: Hevo allows the transfer of modified data in real-time, ensuring efficient bandwidth utilization on both ends.
- Schema Management: Hevo eliminates the tedious task of schema management. It automatically detects the schema of source data and maps it to the destination schema.
Thousands of customers trust Hevo for their ETL process. Join them and experience seamless data migration.
GET STARTED WITH HEVO FOR FREEParquet to PostgreSQL Integration: Querying Parquet Data as a PostgreSQL Database
An ODBC driver makes use of Microsoft’s Open Database Connectivity (ODBC) interface, which allows applications to connect to data in database management systems using SQL as a standard. SQL Gateway is a secure ODBC proxy for remote data access. With SQL Gateway, your ODBC data sources behave like a standard SQL Server or MySQL database.
Using the SQL Gateway, the ODBC Driver for Parquet, and the MySQL foreign data wrapper from EnterpriseDB we can access Parquet data as a PostgreSQL database on Windows.
Steps to import Parquet to PostgreSQL:
- Configure Connection to Parquet: Specify the connection properties in an ODBC DSN (data source name). Microsoft ODBC Data Source Administrator can be used to create and configure ODBC DSNs. Then, Connect to your local Parquet files by setting the URI (Uniform resource identifier)connection properly to the location of the Parquet file.
- Start the Remoting Device: The MySQL remoting service is a daemon process that waits for clients’ incoming MySQL connections. You can set up and configure the MySQL remoting device in the SQL Gateway.
- Build the MySQL Foreign data wrapper: A Foreign Data Wrapper is a library that can communicate with an external data source while concealing the details of connecting to it and retrieving data from it. It can be installed as an extension to PostgreSQL without recompiling PostgreSQL. Building a Foreign Data Wrapper is essential for importing data from Parquet to PostgreSQL.
If you’re using PostgreSQL on a Unix-based system, you can install the mysql fdw using the PostgreSQL Extension Network (PGXN). Compile the extension if you’re using PostgreSQL on Windows to make sure you’re using the most recent version.
Building Extension from Visual Studio
Obtain Prerequisites
- Step 1: Step Install PostgreSQL.
- Step 2: If you’re using a 64-bit PostgreSQL installation, get libintl.h from the PostgreSQL source as libintl.h is not currently included in the PostgreSQL 64-bit installer.
- Step 3: Get the source code for the mysql fdw foreign data wrapper from Enterprise DB.
- Step 4: Install the MySQL Connector C.
Configure a Project
You’re now ready to compile the extension with Visual Studio as you’ve obtained the necessary software and source code.
Follow the steps to create a project using mysql_fdw source:
- Step 1: Create a new empty C++ project in Microsoft Visual studio.
- Step 2:Right-click Source Files and click on Add -> Existing Item In the Solution Explorer. Select all of the .c and .h files from the mysql_fdw source In the file explorer.
To configure your project follow the steps:
- Step 2.1: If you’re creating a 64-bit system, go to Build -> Configuration Manager and select x64 under Active Solution Platform.
- Step 2.2: Right-click your project and select Properties from the drop-down menu.
- Step 2.3: Select All Configurations from the Configuration drop-down menu.
- Step 2.4: Dynamic Library should be selected under Configuration Properties -> General -> Configuration Type.
- Step 2.5: Enable C++ Exceptions is set to No in Configuration Properties -> C/C++ -> Code Generation -> Enable C++ Exceptions.
- Step 2.6: Select Compile as C Code in Configuration Properties -> C/C++ -> Advanced -> Compile As.
- Step 2.7: Select No from Linker -> Manifest File -> Generate Manifest.
Adding Required Dependencies
- Step 1: Select Edit in Linker -> Input -> Additional Dependencies and type the following:
Also, make sure that Inherit From Parent or Project Defaults are both checked.
- Step 2: Select Edit and add the path to the lib folder in your PostgreSQL installation in Linker -> General -> Additional Library Directories.
- Step 3: Select No from Linker -> General -> Link Library Dependencies.
- Step 4: Add the following include to complete your project’s configuration: Add the following folders in the following order to C/C++ -> General -> Additional Include Directories:
Configure mysql_fdw for Windows
- Step 1: Add these defines to mysql fdw.c:
#define dlsym(lib, name) (void*)GetProcAddress((HMODULE)lib, name)
#define dlopen(libname, unused) LoadLibraryEx(libname, NULL, 0)- Step 2: Delete the following line from the mysql load library definition:
mysql_dll_handle = dlopen(_MYSQL_LIBNAME, RTLD_LAZY | RTLD_DEEPBIND);- The code uses the
dlopen()function to dynamically load a shared library, specified by the variable_MYSQL_LIBNAME. - The
RTLD_LAZYflag indicates that function resolution should be deferred until they are actually called. - The
RTLD_DEEPBINDflag ensures that the library’s symbols take precedence over those in the global namespace. - The result of the
dlopen()call is stored in the variablemysql_dll_handle, which can be used to reference the loaded library later. - This approach is commonly used in C or C++ programs to work with dynamic libraries, allowing for flexibility and modular design.
- Step 3: Replace the assignment of mysql dll handle with the following line in the mysql load library definition for a Windows build:
mysql_dll_handle = dlopen("libmysql.dll", 0);- The code uses the
dlopen()function to dynamically load a shared library named “libmysql.dll”. - The second argument is
0, which means it uses default behavior for loading the library, similar toRTLD_NOW. - The
mysql_dll_handlevariable stores the handle or reference to the loaded library, allowing access to its functions. - This method is commonly used in programming languages like C or C++ to enable dynamic linking of libraries at runtime.
- Loading the library this way allows the program to utilize functions defined in “libmysql.dll” without requiring it to be linked at compile time.
- Step 4: To export the function from the DLL, prefix the call to the mysql fdw handler function with the __declspec(dllexport) keyword:
declspec(dllexport) extern Datum mysql_fdw_handler(PG_FUNCTION_ARGS);
- Step 5: To export the function from the DLL, add the __declspec(dllexport) keyword to the declaration of the mysql fdw validator function in option.c:
declspec(dllexport) extern Datum mysql_fdw_validator(PG_FUNCTION_ARGS);
You can now build and choose the Release configuration.
Install the Extension
Follow the steps below to install the extension after you’ve compiled the DLL:
- Step 1: In the PATH environment variable of the PostgreSQL server, add the path to the MySQL Connector C lib folder.
- Step 2: Copy the DLL from your project’s Release folder to your PostgreSQL installation’s lib subfolder.
- Step 3: Copy mysql fdw—1.0.sql and mysql fdw.control from the folder containing the mysql fdw csource files to the extension folder in your PostgreSQL installation’s share folder. C: Program FilesPostgreSQL9.4 share extension is an example of a location.
Query Parquet Data as a PostgreSQL Database
After you’ve installed the extension, you can begin running queries against Parquet data to import data from Parquet to PostgreSQL by following the steps below:
- Step 1: Go to your PostgreSQL database and log in.

- Step 2: Install the database extension.

- Step 3: Create a Parquet data server object:
- Step 4: Make a user mapping for a MySQL remoting service user’s username and password. In the sample service configuration, the user’s credentials are as follows:
- Step 5: Make a local schema.
- Step 6: Import all of the tables from your Parquet database.
You can now run SELECT commands to import data from Parquet to PostgreSQL.
Limitations of Using ODBC Driver for Parquet to PostgreSQL Import
There are certain limitations of using ODBC driver for Parquet to PostgreSQL Import, such as:
- Limited Functionality of ODBC: Both aggregate and non-aggregate functions cannot be used together as an argument for a single SQL statement. Also, it supports scalar functions in canonical form only
- Performance: ODBC driver adds an extra layer of translation, leading to slower import speed as compared to Parquet or Postgres.
Learn how Avro and Parquet file formats compare, and choose the right one for your data needs before importing Parquet files to PostgreSQL
Parquet to PostgreSQL Integration: Loading Parquet in Postgres via DuckDB
To execute the following steps, we will be using a sample parquet dataset called the taxi_2019_XX.parquet dataset.
Step 1: Build and install DuckDB FDW into PostgreSQL
First, install DuckDB and the PostgreSQL extension on your system. Detailed installation instructions are available on the related repo.
Step 2: Configure PostgreSQL
Write the following code to configure PostgreSQL to enable the load of parquet data.
CREATE EXTENSION duckdb_fdw;
CREATE SERVER duckdb_svr \
FOREIGN DATA WRAPPER duckdb_fdw OPTIONS (database ':memory:');- The code starts by creating a PostgreSQL extension called
duckdb_fdw, which allows PostgreSQL to interact with DuckDB, a database management system. - The
CREATE SERVERstatement defines a new foreign server namedduckdb_svr, which will use theduckdb_fdwforeign data wrapper. - The
OPTIONSclause specifies connection details for the DuckDB server, withdatabase ':memory:'indicating that it will use an in-memory database for temporary storage. - This setup allows PostgreSQL to query and manipulate data stored in the DuckDB database as if it were a local table.
- Using foreign data wrappers like
duckdb_fdwenables the integration of different database systems within a single query environment.
Step 3: Create a foreign table
Next, you must create a foreign table in PostgreSQL that will be connecting to the DuckDB.
CREATE FOREIGN TABLE public.taxi_table (
vendor_id text,
pickup_at timestamp,
dropoff_at timestamp,
passenger_count int,
trip_distance double precision,
rate_code_id text,
store_and_fwd_flag text,
pickup_location_id int,
dropoff_location_id int,
payment_type text,
fare_amount double precision,
extra double precision,
mta_tax double precision,
tip_amount double precision,
tolls_amount double precision,
improvement_surcharge double precision,
total_amount double precision,
congestion_surcharge double precision
)
SERVER duckdb_svr
OPTIONS (
table 'read_parquet("/home/xyz/Downloads/taxi-data/*.parquet")'
);
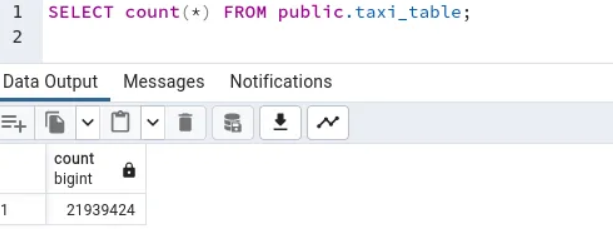
Step 4: Query the data
Now that you have successfully loaded the data into the foreign table, you can run queries on it and analyze the results yourself.
For example:
Use Cases to Transfer Your Parquet Data to Postgres
Migrating data from Parquet to PostgreSQL offers various advantages. Here are a few uses:
- Advanced Analytics: Postgres’ robust data processing capabilities allow you to do complicated queries and data analysis on your Parquet data, yielding insights that would not be available with Parquet alone.
- Data Consolidation: If you’re using numerous sources in addition to Parquet, synchronizing to Postgres allows you to centralize your data for a more complete picture of your operations and build up a change data collection process to ensure that there are no data discrepancies again.
- Historical Data Analysis: Parquet has limitations with historical data. Syncing data to Postgres enables long-term data retention and the study of historical patterns over time.
- Data Security and Compliance: Postgres includes advanced data security capabilities. Syncing Parquet data to Postgres secures your data and enables enhanced data governance and compliance monitoring.
- Scalability: Postgres can manage massive amounts of data without compromising performance, making it a great alternative for growing enterprises with expanding Parquet data.
- Data Science and Machine Learning: By storing Parquet data in Postgres, you may use machine learning models to perform predictive analytics, consumer segmentation, and other tasks.

Conclusion
This blog talks about the steps to follow to import data from Parquet to PostgreSQL in an easy way. It also gives us a basic understanding of Parquet and PostgreSQL.
Extracting complex data from a diverse set of data sources to carry out an insightful analysis can be challenging, and this is where Hevo saves the day!
Some more useful resources related to this source and destination:
Hevo offers a faster way to move data from 150+ data sources, including databases or SaaS applications, into a destination of your choice or a data warehouse that can be visualized in a BI tool. Hevo is fully automated and, hence, does not require you to code. Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
FAQ on Import Parquet to PostgreSQL
1. Does PostgreSQL support Parquet?
PostgreSQL does not natively support Parquet files. However, you can use external tools like Apache Arrow, FDW (Foreign Data Wrapper), or ETL processes to handle Parquet files with PostgreSQL.
2. How to import Parquet files into SQL Server?
a) Using Azure Data Factory
b) Using Apache Spark
3. What is the difference between Apache parquet and Postgres?
Apache Parquet supports columnar storage file format optimized for large-scale queries while Postgres support relational database management system (RDBMS) that stores data in rows and tables.
4. How to convert CSV to PostgreSQL?
a) Using COPY Command
b) Using psql Command-Line Tool
c) Using pgAdmin
5. What is the difference between using DuckDB FDW and ODBC Driver for Parquet imports?
DuckDB FDW provides better performance for analytical queries and is easier to configure, while ODBC drivers offer broader compatibility but may add latency and setup complexity.
6. Why should I convert Parquet data into PostgreSQL?
Importing Parquet data into PostgreSQL allows advanced querying, joins, and analytics on structured data — ideal for historical analysis, dashboards, and machine learning workloads.
7. Are there performance issues when importing Parquet data into PostgreSQL?
Performance depends on data volume, connection type, and transformations. FDW-based approaches and batch ingestion pipelines typically offer faster load times than ODBC imports.
8. How can I handle schema changes during Parquet-to-Postgres migration?
Use schema-aware ingestion methods that automatically map and adjust new columns, or define transformation logic before loading to maintain consistency.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




