




Unlock the full potential of your AWS DocumentDB data by integrating it seamlessly with BigQuery. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
AWS DocumentDB is a document database that offers dynamic schema and faster data replication features. However, it does not support complex joins and columnar storage for faster query performance.
To eliminate such limitations, you can integrate AWS DocumentDB to BigQuery for advanced querying. BigQuery also offers built-in machine learning capabilities and seamless integration with BI tools to help you derive useful business insights from your data.
This article explains how to move data from AWS DocumentDB to BigQuery using two methods for efficient data analytics.
Table of Contents
Google BigQuery Overview
BigQuery is a managed data warehouse service by Google for advanced data analytics. It has a serverless architecture allows you to perform SQL queries without infrastructure management.
BigQuery provides scalability at the petabyte level with built-in features like machine learning, geospatial analysis, and business intelligence.
Methods to Integrate AWS DocumentDB to BigQuery
- Method 1: Using Hevo Data to integrate AWS DocumentDB to BigQuery
- Method 2: Using CSV file to integrate AWS DocumentDB to BigQuery
Method 1: Using Hevo Data to Integrate AWS DocumentDB to BigQuery
Hevo Data is a no-code ELT platform that provides real-time data integration and offers a cost-effective way to automate your data pipelining workflow. With over 150 source connectors, you can integrate your data into multiple platforms, conduct advanced analysis, and produce useful insights.
Here are some of the most important features provided by Hevo Data:
- Data Transformation: Hevo Data provides you the ability to transform your data for analysis with a simple Python-based drag-and-drop data transformation technique.
- Automated Schema Mapping: Hevo Data automatically arranges the destination schema to match the incoming data’s schema. It also lets you choose between Full and Incremental Mapping.
- Incremental Data Load: It ensures proper bandwidth utilization at both the source and the destination by allowing real-time data transfer of the modified data.
The steps below provide information on how to connect AWS DocumentDB to BigQuery.
Step 1: Configuration of AWS DocumentDB as Source
Prerequisites:
- You should have access to an active AWS account. Ensure the Amazon DocumentDB version is 4.0 or higher.
- You should also have access to the Amazon EC2 instance.
- Whitelist Hevo’s IP address. Create a security group for the DocumentDB cluster in your AWS EC2 console.
- Ensure that a cluster parameter group is created in your Amazon DocumentDB Console and a DocumentDB cluster is created.
- You should connect to Amazon EC2. Also, install Mongo shell for your operating system and connect it to your DocumentDB cluster.
- Create a user with the necessary privileges in your Amazon DocumentDB database. Also, check that streams are enabled on the DocumentDB cluster and update log retention duration.
- To create a pipeline, you should ensure that you are assigned the role of Team Administrator, Team Collaborator, or Pipeline Administrator in Hevo.
Once you have fulfilled all the prerequisites, you can use the following steps to configure AWS DocumentDB as a source:
- Click PIPELINES in the Navigation Bar.
- Click + CREATE in the Pipelines List View.
- On the Select Source Type page, select Amazon DocumentDB.
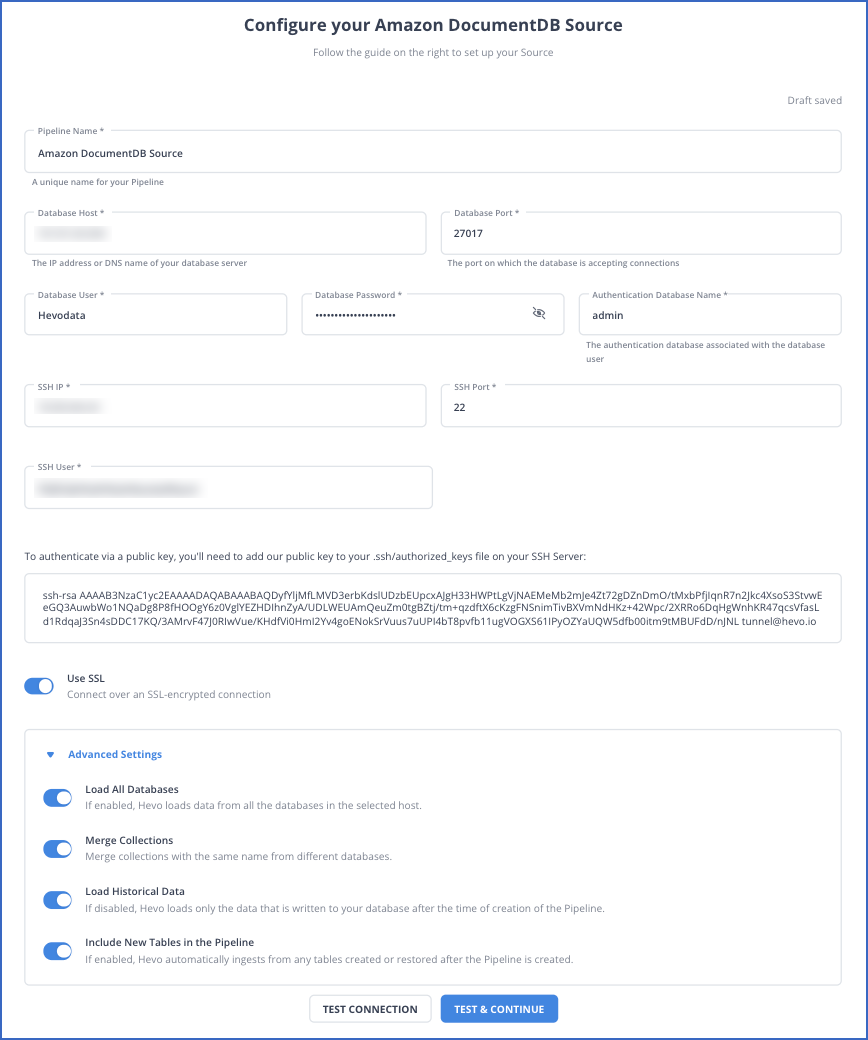
- In the Configure your Amazon DocumentDB Source page, specify the following:
Step 2: Configuration of BigQuery as Destination
Prerequisites:
- You should ensure that you have access to the GCP project. If you do not have one, refer to the steps in Create a Google Cloud project.
- Assign the essential roles of the GCP project to the connecting Google account. These roles are in addition to the Owner or Admin roles within the project.
- You should also ensure an active billing account is linked to your GCP project. Further, ensure you are assigned the Team Collaborator or any administrator role except the Billing Administrator role in Hevo to create the destination.
After fulfilling these prerequisites, follow the below steps to configure BigQuery as a destination in Hevo:
- Click DESTINATIONS in the Navigation Bar.
- Click + CREATE from the Destinations List View.
- In the Add Destination page, select Google BigQuery as the Destination type.
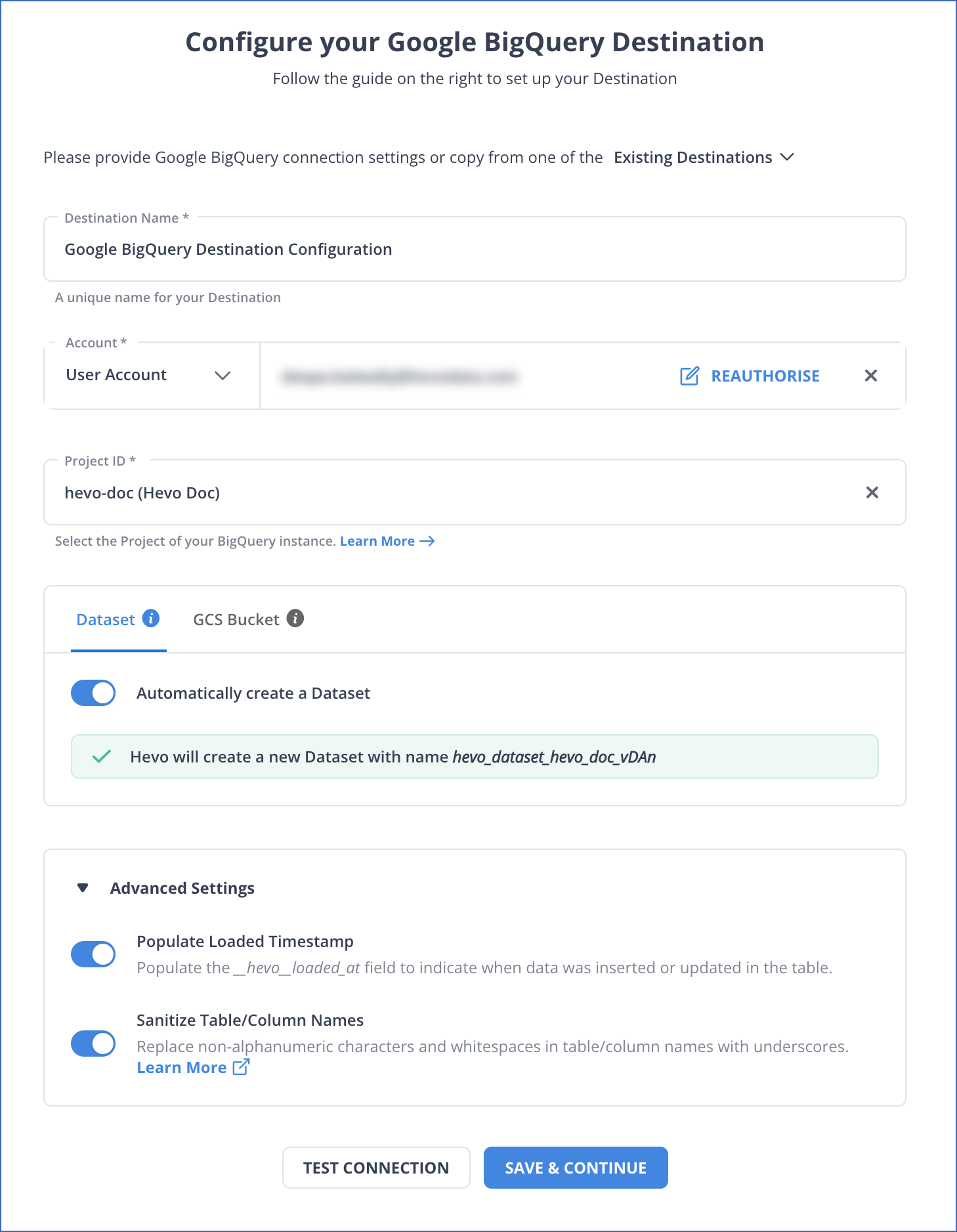
- In the Configure your Google BigQuery Warehouse page, specify the following details:
Get Started with Hevo for Free
Method 2: Export CSV file to Integrate AWS DocumentDB to BigQuery
Here are the steps you need to follow:
Step 1: Export Data from AWS DocumentDB to a CSV file
Amazon DocumentDB uses the monogoexport utility to transfer data to a CSV file as follows:
mongoexport --ssl \
--host="sample-cluster.node.us-east-1.docdb.amazonaws.com:27017" \
--collection=sample-collection \
--db=sample-database \
--out=sample-output-file \
--username=sample-user \
--password=abc0123 \
--sslCAFile global-bundle.pem- This command uses
mongoexportto export data from a MongoDB collection to a file. --sslenables SSL for a secure connection to the database.- The
--hostspecifies the MongoDB host address and port in AWS DocumentDB. --collectionand--dbspecify the collection and database from which the data will be exported.--outdefines the output file, and--username,--password, and--sslCAFileprovide authentication and SSL certificate information for the connection.
This data is exported to a CSV file in your native system.
Step 2: Loading CSV file to Google Cloud Storage
To load a CSV file from your local system to Google Cloud Storage, follow the below steps:
- Go to your Google Cloud account and then to the Google Console.

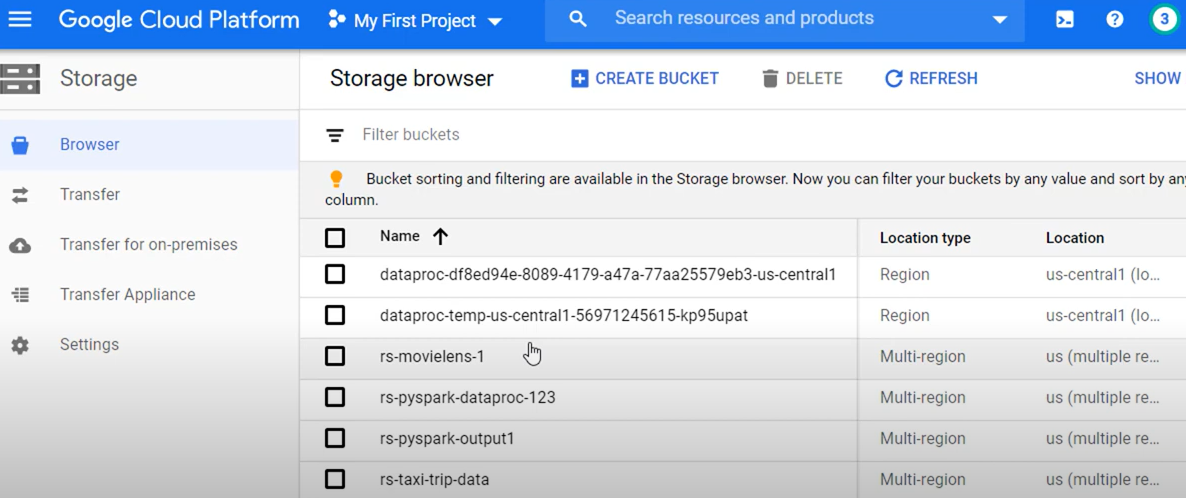
- On the Navigation Menu on the left, click Storage > Browser.

- You need to create a bucket, which is like a folder in Google Cloud, to store your files. To do this, click on +CREATE BUCKET.
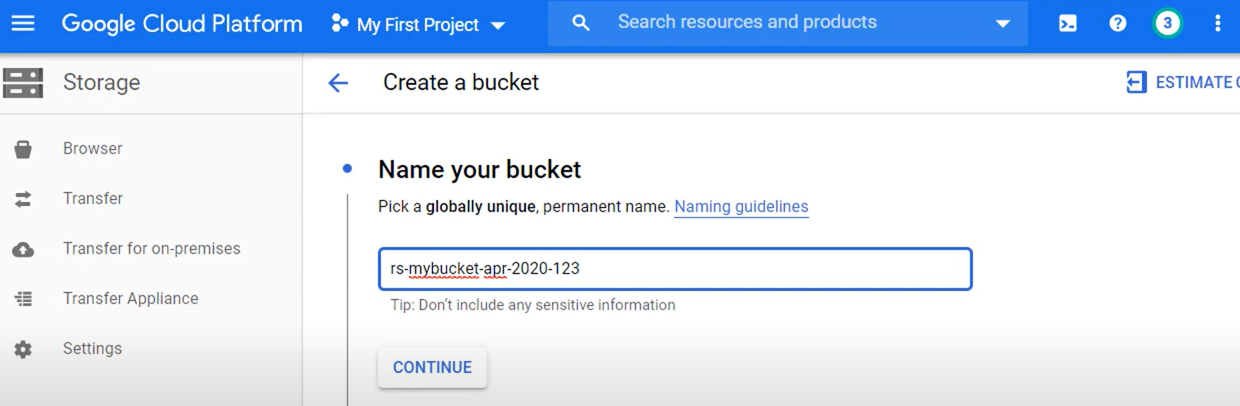
- Enter a name for your bucket and click CREATE at the bottom.
- Now click on Upload Files, or you can directly drag and drop your CSV file.
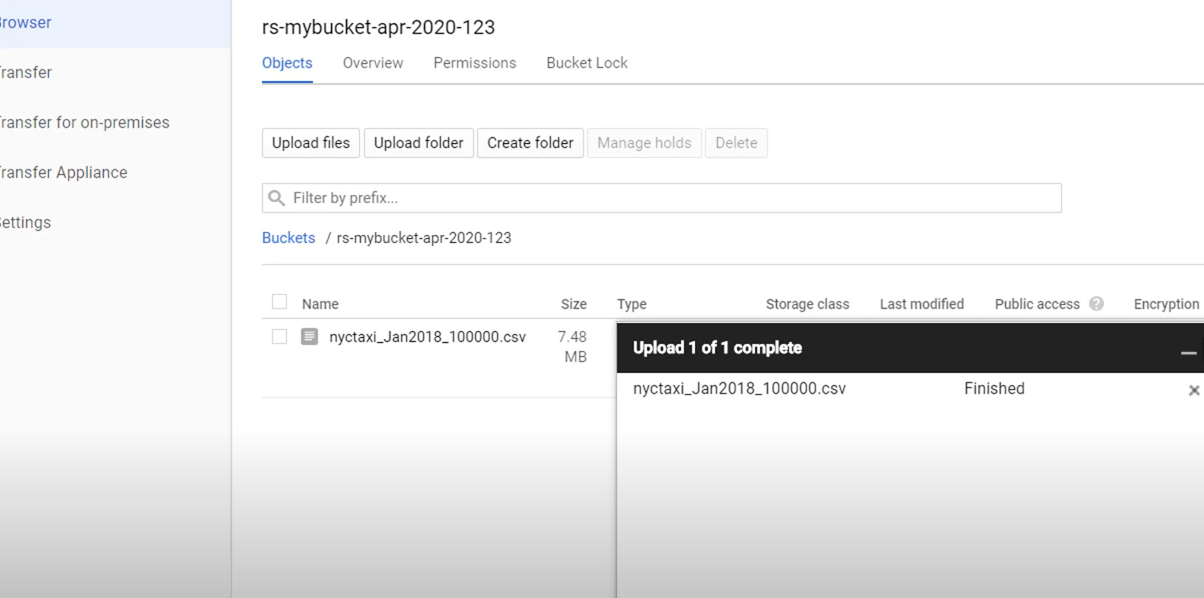
- After uploading, your file appears on the Google Cloud interface as shown below:
Step 3: Exporting Data from CSV file in GCS to BigQuery
You can use the LOAD DATA SQL statement within the Query Editor of BigQuery to load your data from the CSV file to the BigQuery table. You can follow these steps:
- Go to the BigQuery page in Google Cloud Console.
- Enter the following code in Query Editor:
LOAD DATA OVERWRITE mydataset.mytable
(x INT64,y STRING)
FROM FILES (
format = 'CSV',
uris = ['gs://bucket/path/file.csv']);- This command loads data into a BigQuery table
mydataset.mytable. - It specifies that the columns
xandyare of typesINT64andSTRINGrespectively. - The
LOAD DATA OVERWRITEreplaces the existing data in the table with new data from the file. - The data source is a CSV file located at the given URI in a Google Cloud Storage bucket.
- The
format = 'CSV'indicates that the file being loaded is in CSV format.
- Click Run. You can access your data in BigQuery upon completion of the export.
Limitations of Using CSV Files to Integrate AWS DocumentDB to BigQuery
There are several limitations to using CSV files to integrate AWS DocumentDB to BigQuery. These are as follows:
- Limited Data Type: CSV files store data in text format. They support basic data types such as numbers or dates but not complex data types.
- Scalability Issues: CSV files do not support importing large volumes of data. They lack compression features and take a lot of time to transfer data.
Use Cases
When you export AWS DocumentDB to BigQuery, you can leverage it in several ways, such as:
- Big Data Analytics: You can integrate with BigQuery to conduct complex analytics on large enterprise datasets. This aids in customer behavior analysis and predicts market trends leading to innovation and business growth.
- Real-time Analytics: You can integrate the data in BigQuery with Google Cloud’s streaming platforms, like Dataflow, and use it for real-time analytics. This helps streamline your product development strategy according to the current trends in your organization’s domain.
- Machine Learning: BigQuery provides built-in machine learning capabilities, which you can use to build and execute machine learning models using SQL queries directly. Thus, it simplifies the machine learning deployment process for your data without the need for expertise.
- Business Intelligence: You can connect BigQuery with BI tools like Power BI, Looker, or Tableau to create interactive dashboards and reports. Such business reports allow you to gain useful business insights and make better decisions for business growth.
Why Integrate AWS DocumentDB to BigQuery?
You should transfer AWS DocumentDB data to BigQuery for the following reasons:
- You can use BigQuery to create and deploy machine learning models through its built-in machine learning features.
- BigQuery offers better data compression and faster query performance through a columnar storage format, which DocumentDB does not provide.
- BigQuery is a relational database, while DocumentDB is a document database. Relational databases store data in an organized way, unlike document databases.
- BigQuery supports complex joins while querying, which is important for complex and high-volume data analysis.
Conclusion
- This blog provides information on how to load AWS DocumentDB file in BigQuery using two methods.
- One of the methods is CSV files for data migration
- The other method is using Hevo Data, a zero-code data integration platform.
- The robust features of Hevo, such as zero-code data pipelines, automation, security features, and an extensive library of connectors, make it a suitable tool for data integration.
- Learn how to connect AWS DocumentDB to Databricks for seamless data integration and analysis, covering configuration and connection steps. Find out more at AWS DocumentDB to Databricks.
FAQs
- What does MongoDB compatibility mean in DocumentDB?
DocumentDB is said to be compatible with MongoDB because it interacts with 3.6, 4.0, and 5.0 APIs. It enables you to use MongoDB drivers and applications with DocumentDB with some or no changes. However, DocumentDB does not support all MongoDB APIs.
- What are the limitations of BigQuery?
BigQuery usage has certain drawbacks, such as fewer customization features and limited integration with other non-GCP applications. It also appears complex for those new to data warehousing and SQL.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link


