




Analyzing vast volumes of data can be challenging. Google BigQuery is a powerful tool that efficiently stores, processes, and analyzes large datasets. However, it may only provide some of the functionalities and tools needed for complex analysis. This is where Databricks steps in. It offers a variety of tools, such as interactive notebooks, ML tools, clusters, and more, that help you simplify complex tasks. Integrating BigQuery into Databricks allows you to combine data warehousing capabilities with advanced analytics tools to enhance your data performance.
In this guide, we’ll walk through two effective methods for migrating BigQuery data to Databricks and help you understand why this integration is a game changer for your data workflows.
Table of Contents
Why Integrate BigQuery to Databricks?
BigQuery Databricks integration significantly benefits an organization’s data analytics capabilities.
- Centralized Workflow: Databricks is a unified data analytics and engineering platform, enabling a centralized workflow for data processing.
- Enhanced Performance: The optimized Apache Spark clusters in Databricks can quickly process large datasets and allow you to allocate resources dynamically based on work needs. This results in fast query execution, reduced time to gain insight, and efficient resource utilization.
- Improved Analytics: Databricks offers advanced analysis tools and libraries like MLflow, SparkSQL, and more.
- Efficient Data Processing: Databricks provides dynamic resource allocation for faster query execution and improved performance.
Facing challenges migrating your customer and product data from BigQuery to Databricks? Migrating your data can become seamless with Hevo’s no-code intuitive platform. With Hevo, you can:
- Automate Data Extraction: Effortlessly pull data from BigQuery(and other 60+ free sources).
- Transform Data effortlessly: Use Hevo’s drag-and-drop feature to transform data with just a few clicks.
- Seamless Data Loading: Quickly load your transformed data into your desired destinations, such as Databricks.
Try Hevo and join a growing community of 2000+ data professionals who rely on us for seamless and efficient migrations.
Get Started with Hevo for FreeOverview of BigQuery
BigQuery is a fully managed serverless data warehouse developed by Google and offered as a Platform as a Service (PaaS). It supports SQL querying, making it accessible and easy to query and retrieve data. It seamlessly integrates with different Google Cloud services, such as Google Cloud Storage (GCS), Google Sheets, and more, simplifying data visualization and workflows. It is a powerful warehouse solution with high scalability and data querying capabilities.
Overview of Databricks
Databricks is a unified platform. It offers optimized Apache Spark clusters, interactive notebooks, and a collaborative workspace where you can efficiently work with your team on data projects. Databricks seamlessly integrates with varied data sources and services such as AWS, Azure, SQL Server, and third-party tools, allowing integration within existing infrastructure.
It also has in-built ML and AI capabilities that help you manage, develop, and deploy end-to-end ML workflows and models. Overall, Databricks is a platform that enhances your ability to make informed business decisions and innovations in your workflow.
How to Migrate BigQuery to Databricks?
Method 1: Using Hevo
Step 1: Configure BigQuery as Your Source
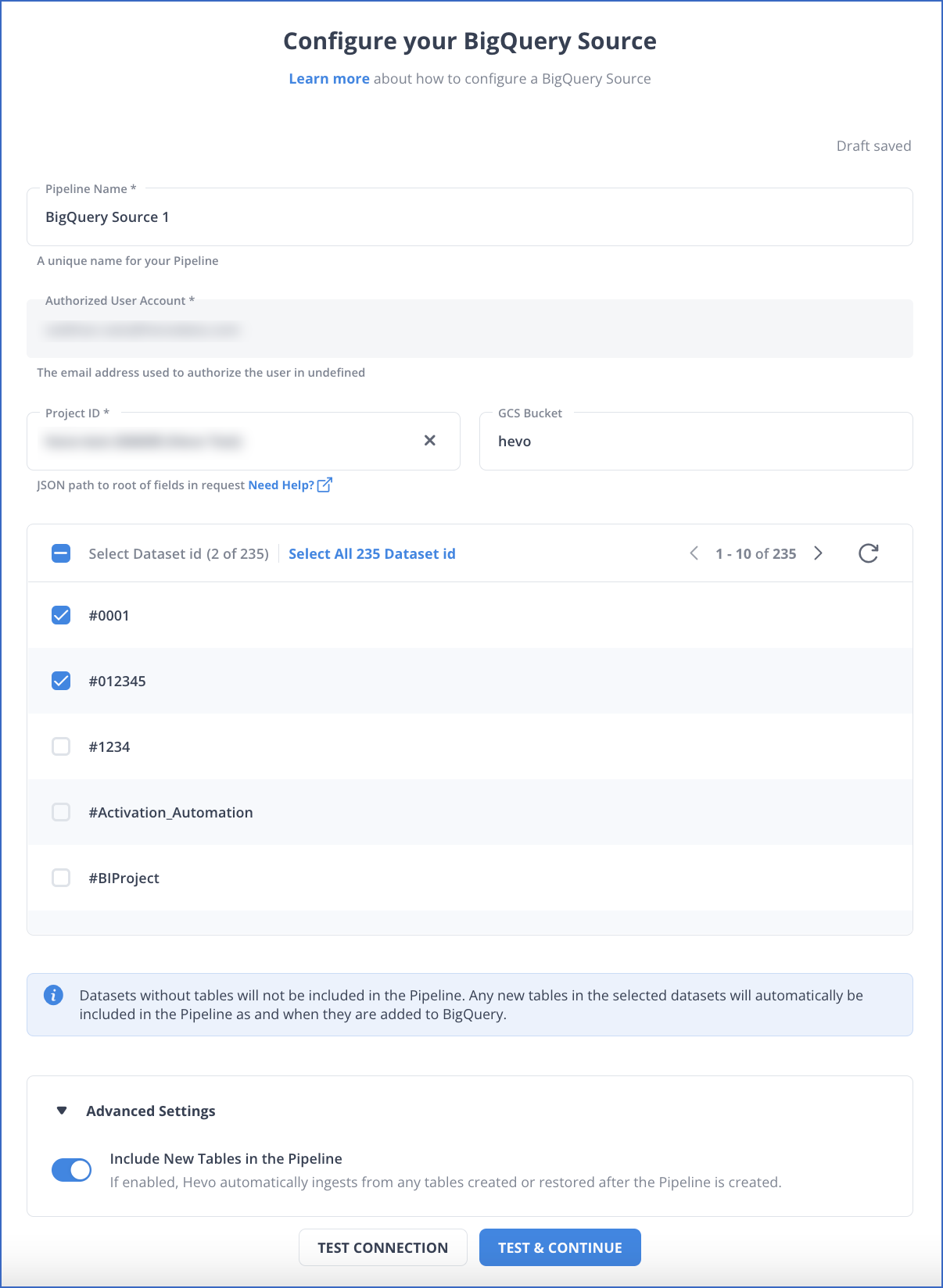
To learn more about configuring BigQuery as your source, read the Hevo Documentation.
Step 2: Set up Databricks as Your Destination
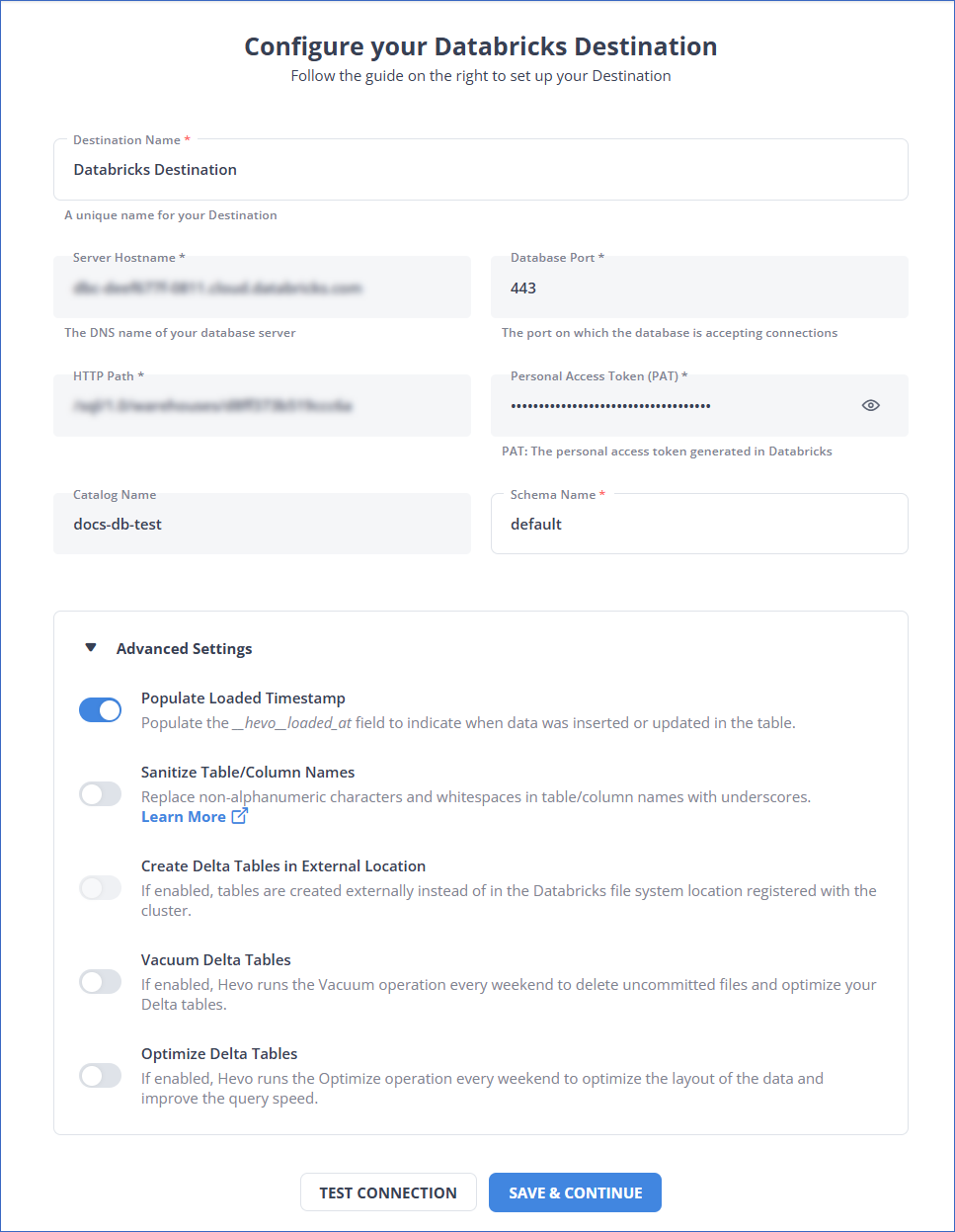
For more information, refer to the Hevo documentation on configuring Databricks as the destination.
Learn how to connect Google Sheets to Databricks for seamless data processing and analytics.
Method 2: Using Google Cloud Console
In this method, you will learn:
- How to read BigQuery in Databricks.
- How to convert BigQuery to Databricks table.
Prerequisites:
- Your GCP project requires specific permissions to read and write using the BigQuery.
- You must set up your Google Service account using GCP.
- Create a Google bucket for temporary storage.
- Create an external table from your BigQuery account.
Step 1: Set up Your Google Cloud
You have to set up your Google Cloud Storage by following the steps given below:
1.1: Enable Your BigQuery Storage API
The BigQuery API is enabled by default for all the Google projects where BigQuery is enabled. However, you need to allow your BigQuery API for the Google project you are using to connect with Databricks.
You can use any of the methods below to enable your BigQuery API to set up a connection between BigQuery and Databricks.
1.2: Create a Google Service Account
You need to create a Google service account for your Databricks cluster to read, write, and query tasks.
There are two methods to create a service account for your Databricks cluster. For both methods, you need to generate or add keys for safe authentication:
- Create a Google service account using Google CLI.
- Create a Google service account using Google Cloud Console.
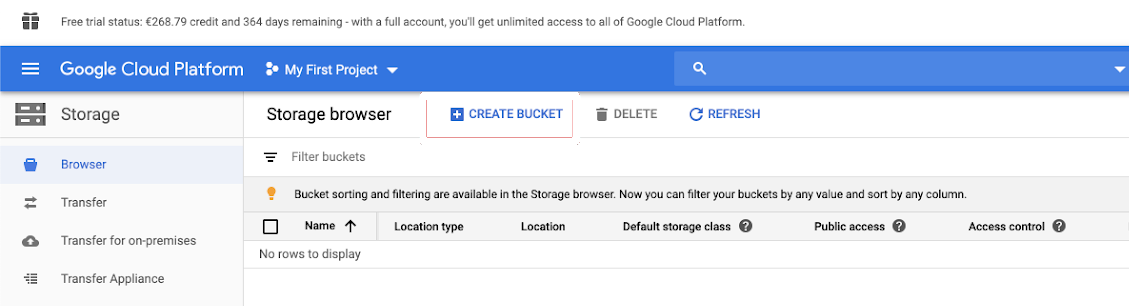
1.3: Create a Google Storage Bucket for Temporary Storage
You must create a Google Storage Bucket to write in the BigQuery table.
- Click on CREATE BUCKET.
- Click on Storage in the navigation bar on your Google Cloud Platform.
- Configure the Bucket Settings and click on CREATE.
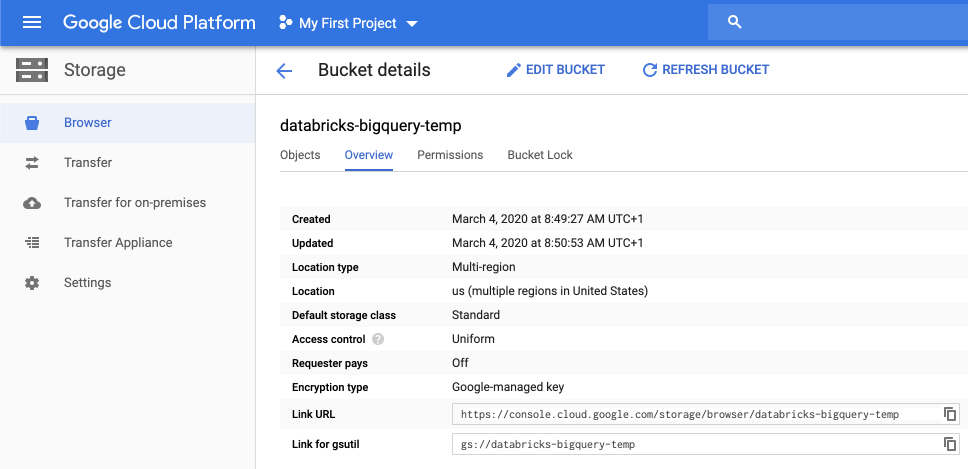
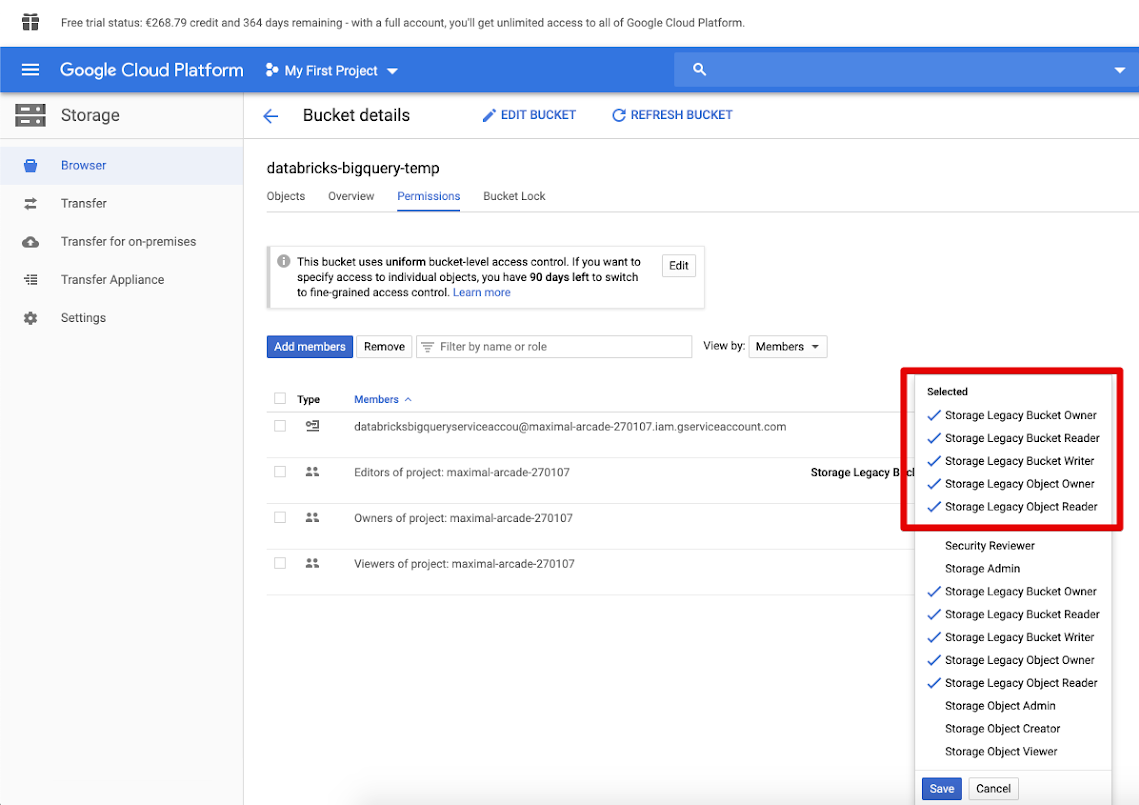
- Click on the Permissions tab, add members, and provide permissions to the service account on the bucket. Then click on SAVE.
Step 2: Set up the Databricks
You need to configure the Databricks cluster to access your data in the BigQuery table. For this, you should provide a JSON key file as Spark configuration.
Add the following configuration on the Spark Configuration Tab, replacing <base64-keys> with the string of your encoded JSON file key for Base64.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>Step 3: Read a BigQuery Table in Databricks
Open your Databricks workspace and select a Databricks notebook, which you can use to execute the following code to read BigQuery in Databricks.
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()Step 4: Write in a BigQuery Table
To write data in the BigQuery table, execute the following command.
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()In the above code <bucket-name> is the name of the bucket you created for temporary storage.

Limitations of the Manual Method Using Google Cloud Console
- Complex Setup: Setting up the integration requires in-depth knowledge of both BigQuery and Databricks ecosystems, making it challenging for non-experts.
- Temporary Storage Requirement: You must create and configure a Google Cloud Storage bucket for temporary data storage, adding complexity and additional steps to the process.
- Manual Permissions Management: Configuring permissions and authorizations between BigQuery, Google Cloud Console, and Databricks can be error-prone and time-consuming.
- Time-Consuming Process: Transferring data between BigQuery and Databricks using this method is slower, as data is temporarily stored before being loaded into Databricks.
- Potential Security Risks: Incorrect permissions or configurations can lead to data security issues, requiring careful attention to detail during setup.
What are the Real-World Use Cases of the BigQuery-Databricks Connection?
- Fraud Detection: Using machine learning models in Databricks, you can perform real-time risk assessments and detect fraudulent activities.
- Customer Data Analysis: You can analyze your customer data in Databricks and build predictive models to identify customer churn rates and generate retention strategies.
- Supply Chain Management: Databricks machine learning tools will help you build forecasting models that can be used to optimize inventory levels and reduce lead times in the supply chain.
- Financial Modeling: Use Databricks for financial modeling and forecasting on transaction data stored in BigQuery.
You can also take a look at how you can migrate your data from BigQuery to a database like PostgreSQL effortlessly.
Learn More About:
- Databricks Clusters
- Google Cloud Storage to Databricks
- GCP Postgres to Databricks
- Amazon S3 to Databricks
- Databricks Connect to SQL Server
Conclusion
BigQuery and Databricks are robust and highly scalable serverless platforms that allow you to store and analyze your data sets effortlessly. Integrating data from BigQuery to Databricks facilitates seamless data management and enables advanced analysis.
You can combine data between these platforms using Google Cloud Console or Hevo. While Google Cloud Console can be a little complex, with Hevo’s flexible no-code data pipeline, you can smoothly ingest data from source to destination in a minimal amount of time.
Overall, BigQuery Databricks integration is a transformative step towards unlocking the value of data analytics and driving business value. Establishing more connections like BigQuery-Databricks can be simplified using Hevo. Sign up for a 14-day free trial and learn more.
FAQs (Frequently Asked Questions)
Q. How can you load Google BigQuery data in a Dataframe on Databricks?
You can load your Google BigQuery data in a data frame on Databrick using a Python or Scala notebook.
Q. Can BigQuery Connector connect data from Google BigQuery to Spark on Databricks?
BigQuery Connector is a client-side library connector that uses BigQuery API. Yes, you can use the BigQuery Connector to read data from Google BigQuery into Apache Spark, which runs on Databricks.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





