




Easily move your data from AWS RDS Oracle to BigQuery to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
In today’s data-driven world, data storage and analysis are essential to derive deeper insights for smarter decision-making. As data volumes increase, organizations consider shifting transactional data from Oracle databases on AWS RDS to a powerful platform like Google BigQuery. It can be due to several reasons, which include AWS RDS Oracle’s storage limits, high query costs, and scalability issues.
When migrating to BigQuery, your organization can utilize its optimized, durable, and encrypted storage component to execute analytical queries on large datasets. You can successfully move data from AWS RDS Oracle to BigQuery with meticulous planning and appropriate tools.
Table of Contents
Why Integrate AWS RDS Oracle with Google BigQuery?
When integrating AWS RDS Oracle with BigQuery, you can enjoy many benefits. Some of them are:
- Faster Query Performance: BigQuery uses slots to refer to the CPU and RAM resources allocated for query processing. These slots can execute numerous queries concurrently. Increased parallel processing leads to faster query completion.
- Scalable Storage: BigQuery stores data in a highly compressed and columnar storage format. This storage architecture allows auto-scaling, enabling you to adjust to workload demands automatically without additional costs.
AWS RDS Oracle: A Brief Overview
AWS RDS for Oracle is part of Amazon Relational Database Service (RDS) that is compatible with Oracle databases. Using a lift-and-shift approach, you can deploy the Oracle database to Amazon RDS, minimizing the risk of data loss.
AWS RDS Oracle enables you to quickly configure, operate, and scale Oracle deployments on the AWS cloud, according to your needs.
When using AWS RDS for Oracle, you can select the License Included or Bring-Your-Own-License (BYOL) options. In addition, you can opt to buy Reserved DB Instances with a small upfront payment for a one or three-year reservation period.
Migrate your data from AWS RDS Oracle to BigQuery seamlessly using Hevo’s intuitive, no-code platform. With automated workflows and real-time data syncing, Hevo ensures smooth, accurate data transfer for all your analytical needs. Its features include:
- Connectors: Hevo supports 150+ integrations to SaaS platforms, files, Databases, analytics, and BI tools. It supports various destinations, including Google BigQuery, Amazon Redshift, and Snowflake.
- Real-Time Data Transfer: Hevo provides real-time data migration, so you can always have analysis-ready data.
- 24/7 Live Support: The Hevo team is available 24/7 to provide exceptional support through chat, email, and support calls.
Try Hevo today to experience seamless data transformation and migration.
Get Started with Hevo for FreeBigQuery: A Brief Overview
BigQuery is a serverless data warehouse platform that does not require coding skills. It is a fully managed analytics platform that provides a unified workspace to easily store and analyze your organization’s operational data in one place.
By incorporating its AI capabilities, you can maximize productivity and optimize costs. In addition, BigQuery offers real-time analytics with built-in business intelligence,
BigQuery lets you quickly develop and run machine learning models using simple SQL queries. It allows you to store up to 10 GiB of data and execute up to 1 TiB of queries monthly for free.
Methods for AWS RDS Oracle to BigQuery Migration
To export data from AWS RDS Oracle to BigQuery file, you can employ Hevo Data or Amazon S3 and Java.
Method 1: Data Migration from AWS RDS Oracle to BigQuery Using Hevo Data
Hevo Data is a real-time ELT data pipeline platform with a no-code feature that allows you to create automated data pipelines cost-effectively according to your needs. With the integration to over 150+ data sources, Hevo Data lets you export, load, and transform the data for detailed analysis.
Below are some key features of Hevo Data:
- Data Transformation: Hevo Data simplifies data transformation by offering the option to use Python-based Transformation scripts or Drag-and-Drop Transformation blocks. These analyst-friendly options will help you clean, prepare, and standardize data before loading it to your desired destination.
- Incremental Data Load: Hevo Data enables transferring updated data, which helps to use bandwidth on both sides of the pipeline efficiently.
- Auto-Schema Mapping: Hevo Data’s Auto Mapping feature eliminates the need for manual schema management. This functionality automatically identifies the format of incoming data and transfers it to the desired destination schema. Depending on your data replication needs, you can choose either full or incremental mappings.
Let’s see how to integrate AWS RDS Oracle to BigQuery using the Hevo Data.
Step 1: Set Up AWS RDS Oracle as Your Source Connector
Before starting the setup, make sure you have the following prerequisites in place:
- Oracle Database version 12c or above.
- Enable Redo Log Replication if Pipeline mode is Redo Log.
- Whitelist Hevo’s IP addresses.
- Provide SELECT Privileges for the database user.
- Obtain the Database hostname and port number of the Source DB instance.
- Pipeline Administrator, Team Collaborator, or Team Administrator role in Hevo to create the source end of the pipeline.
Here are the steps to set up your AWS RDS Oracle source in Hevo:
- Log into your Hevo account and select PIPELINES from the Navigation Bar.
- Go to the Pipelines List View page and click the + CREATE button.
- Search in the Select Source Type page and choose Amazon RDS Oracle as the Source type.
- In the Configure your Amazon RDS Oracle Source page, specify the following fields:

- To proceed with the source configuration, click the TEST CONNECTION button followed by the TEST & CONTINUE button.
Read Hevo Documentation to learn more about configuring the AWS RDS Oracle source connector.
Step 2: Set Up BigQuery as Your Destination Connector
Before you begin the configuration, make sure the following prerequisites are met:
- Access to Google Cloud Platform (GCP) for a BigQuery Project or create one.
- Assign the roles for the GCP project to the connecting Google account.
- An active billing account linked with your GCP project.
- You must have a Team Collaborator or any administrator role, excluding the Billing Administrator role.
Here are the steps to set up your BigQuery destination in Hevo:
- From the Navigation Bar, click the DESTINATIONS option.
- In the Destinations List View page, click the + CREATE button.
- Navigate to the Add Destination page and select Google BigQuery as the Destination type.
- Specify the following details on the Configure your Google BigQuery Destination page.
- You can enable Advanced settings, including Populate Loaded Timestamp and Sanitize Table/Column Names.
- Click the TEST CONNECTION followed by the SAVE & CONTINUE button to finish the destination configuration.
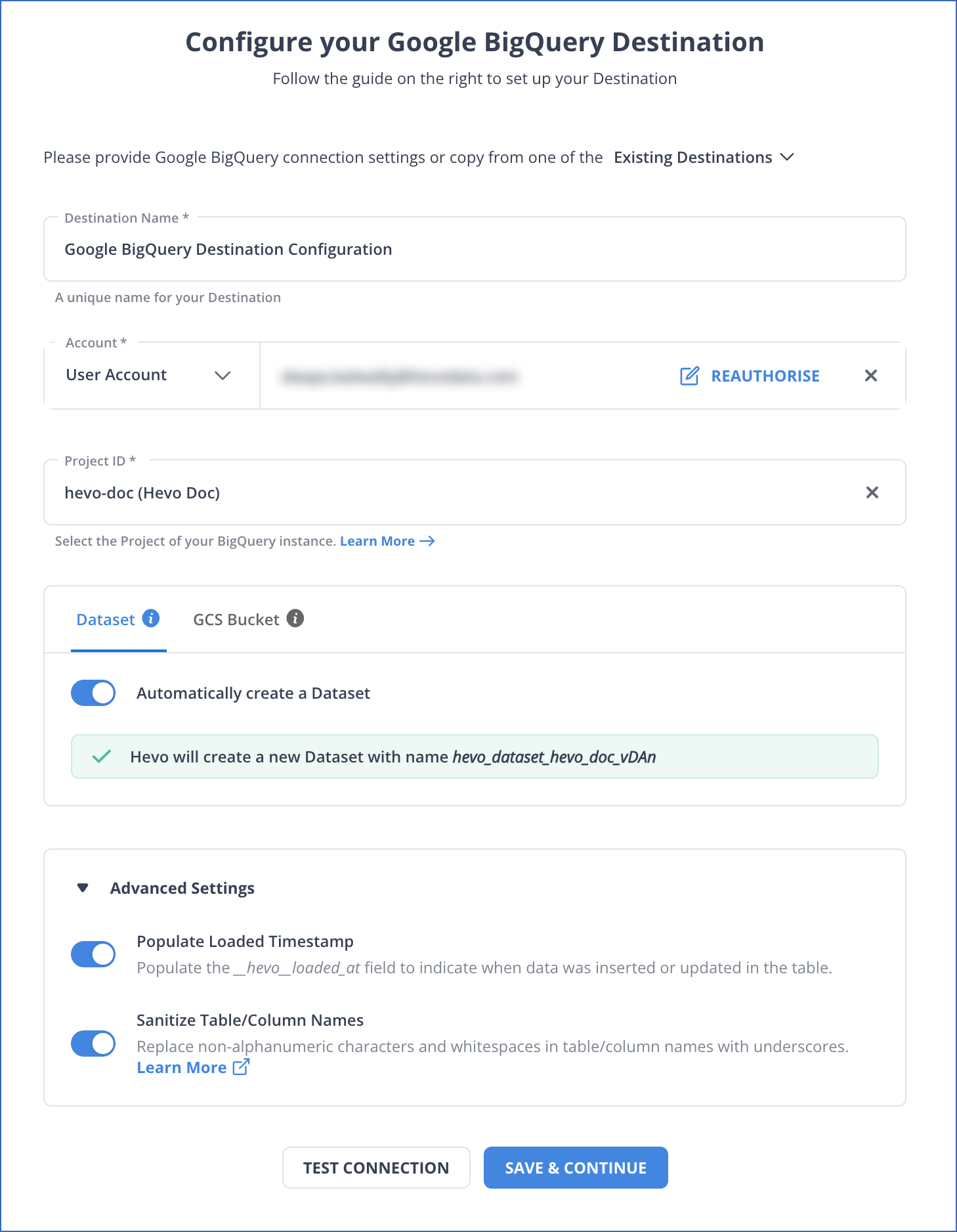
Once the destination is created, only a few settings can be modified. Read Hevo Documentation to learn more about configuring the BigQuery destination connector.
Method 2: Data Migration from AWS RDS Oracle to BigQuery Using Amazon S3 and Java
For this migration, you can export the data from AWS RDS Oracle to an Amazon S3 bucket and then load it into BigQuery using Java code. Have a look at our blog for a detailed explanation on How to Connect to Oracle DB.
Perform the following steps to convert AWS RDS Oracle to BigQuery:
Step 1: Export Data from AWS RDS Oracle to Amazon S3 Bucket
Before exporting the data, ensure the given prerequisites are in place:
- Oracle 19c version or above.
- An Amazon S3 Bucket.
- An AWS IAM user account with an access key.
- Install DBMS_CLOUD package.
- Create a Cloud Service User and Grant Privileges using the schema creation script.
- Create an SSL Wallet with Trusted Certificates.
- Set up Access Control Entries (ACEs) for DBMS_Cloud
- Create Database Role and User
- Create DBMS_CLOUD credentials
- Configure the $ORACLE_HOME/network/admin/sqlnet.ora file in the Oracle database.
Let’s look into the steps to export from AWS RDS Oracle to Amazon S3 Bucket.
- Execute the Schema Creation Script
Use the following command to run the schema creation script:
$ORACLE_HOME/perl/bin/perl $ORACLE_HOME/rdbms/admin/catcon.pl -u sys/<your_sys_password> --force_pdb_mode 'READ WRITE' -b dbms_cloud_install -d /home/rdsdb -l /home/rdsdb dbms_cloud_install.sql- Execute the ACEs for DBMS_CLOUD
Run the following command in the CDB ROOT Container:
sqlplus sys/<your_sys_password> as sysdba- Connect with the Database User to the Pluggable Database
- Run the following command and create your database table with the required data.
sqlplus <your db user name>/<your_password>@<your RDS endpoint>/<your PDB name>- Move Data to the CSV File in the DATA_PUMP_DIR Directory
Execute the following command to write the data in your database table to a CSV file:
declare
cursor c is select <column_name1, column_name2, ….> from <table_name>;
filename varchar2(50) default 'emp.csv';
f utl_file.file_type;
begin
f := utl_file.fopen ('DATA_PUMP_DIR',filename,'w');
for c1 in c loop
utl_file.put_line(f, c1.<column_name1>||','||c1.<column_name2>||','||c1.<column_name3>||','||c1.<column_name4>);
end loop;
utl_file.fclose(f);
end;
/- Export the Data to the S3 Bucket
Run the following command to load the data from the AWS RDS Oracle database to the S3 bucket:
begin
dbms_cloud.put_object (
credential_name => '<credential_name>',
object_uri => 'https://s3.ap-southeast-1.amazonaws.com/<your bucket name>/orcl//path_to_your_csv_file/',
directory_name => 'DATA_PUMP_DIR',
file_name => '/path_to_your_csv_file/');
end;
/Step 2: Import Data into BigQuery from Amazon S3 Bucket
Before exporting the data, ensure you have obtained the given prerequisites:
Execute the following Java code to load the data into a BigQuery table:
import com.google.cloud.bigquery.datatransfer.v1.DataTransferServiceClient;
import com.google.cloud.bigquery.datatransfer.v1.CreateTransferConfigRequest;
import com.google.cloud.bigquery.datatransfer.v1.TransferConfig;
import com.google.cloud.bigquery.datatransfer.v1.ProjectName;
import com.google.api.gax.rpc.ApiException;
import com.google.protobuf.Struct;
import com.google.protobuf.Value;
import java.util.Map;
import java.util.HashMap;
import java.io.IOException;
// Class to Create Amazon S3 Transfer Configuration
public class AmazonS3TransferConfig {
public static void main(String[] arg) {
// Replace the ProjectID, DatasetID, TableID.
final String ProjectID = "Your_ProjectID";
String DatasetIdD = "Your_DatasetID";
String TableID = "Your_TableID";
// Setting Up Amazon S3 Bucket URI with Read Privilege
String SourceURI = "s3://YourBucketName/*";
String AwsAccessKeyID = "Your_AWS_AccessKeyID";
String AwsSecretAccessID = "Your_AWS_SecretAccessID";
String SourceFormat = "CSV";
String FieldDelimiter = ",";
String SkipLeadingRows = "1";
Map<String, Value> params = new HashMap<>();
params.put(
"destination_table_name_template", Value.newBuilder().setStringValue(TableID).build());
params.put("data_path", Value.newBuilder().setStringValue(SourceURI).build());
params.put("access_key_id", Value.newBuilder().setStringValue(AwsAccessKeyID).build());
params.put("secret_access_key", Value.newBuilder().setStringValue(AwsSecretAccessID).build());
params.put("source_format", Value.newBuilder().setStringValue(SourceFormat).build());
params.put("field_delimiter", Value.newBuilder().setStringValue(FieldDelimiter).build());
params.put("skip_leading_rows", Value.newBuilder().setStringValue(SkipLeadingRows).build());
TransferConfig transferConfiguration =
TransferConfig.newBuilder()
.setDestinationDatasetId(DatasetID)
.setDisplayName("Your_AmazonS3_ConfigurationName")
.setDataSourceId("Amazon_s3")
.setParams(Struct.newBuilder().putAllFields(params).build())
.setSchedule("Every 24 hours")
.build();
AmazonS3TransferConfig(ProjectID, transferConfiguration);
}
public static void AmazonS3TransferConfig(String ProjectID, TransferConfig transferConfiguration)
throws IOException {
try (DataTransferServiceClient client = DataTransferServiceClient.create()) {
ProjectName ProjectParent = ProjectName.of(ProjectID);
CreateTransferConfigRequest ConfigRequest =
CreateTransferConfigRequest.newBuilder()
.setParent(ProjectParent.toString())
.setTransferConfig(transferConfig)
.build();
TransferConfig configuration = client.createTransferConfig(ConfigRequest);
System.out.println("Data Loading is Successful:" + configuration.getName());
} catch (ApiException ex) {
System.out.print("Data Loading is Unsuccessful." + ex.toString());
}
}
}With the above steps, you can manually migrate the AWS RDS Oracle table to the BigQuery table.
Limitations of AWS RDS Oracle to BigQuery Migration Using Amazon S3 and Java
- High Complexity: The AWS RDS Oracle to BigQuery migration using Amazon S3 and Java can be complex and confusing due to the numerous configurations involved. Identifying errors during configurations can also be challenging, making the process labor-intensive.
- Coding Skill: To transfer data from AWS RDS Oracle to BigQuery via Amazon S3, you need strong technical knowledge in Oracle SQL, PL/SQL, and Java.

Use Cases for AWS RDS Oracle to BigQuery Migration
- Partitioning and Clustering: AWS RDS Oracle to BigQuery migration enables cost-efficient data analysis within optimized query costs using data partitioning and clustered tables.
- Reduced Processing Issues: Your organization may face challenges in processing large files on a regular basis. By migrating to BigQuery, only relevant data can be processed by configuring Scheduled Jobs as BigQuery Scripts. This will minimize resource consumption and improve query performance.
You can also read about:
- Migrate Oracle to PostgreSQL
- Optimize Oracle migration to GCP
- Connect to Oracle DB (3 methods)
- Set up Oracle connection in Airflow
Conclusion
This article explains how to migrate your AWS RDS Oracle databases to BigQuery using Hevo Data or manually using Amazon S3 and Java code.
In addition, this article offers a few use cases where migrating from AWS RDS Oracle to BigQuery can benefit from BigQuery’s partitioning and clustering features. These features enable the analysis of operational data within your organization, and using BigQuery Scripts helps minimize processing issues.
The manual method has some limitations that may impact a smooth migration. For optimal migration performance, it is recommended to use an automated real-time ELT platform like Hevo. Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
Frequently Asked Questions (FAQ)
1. For AWS RDS Oracle to BigQuery, I use AWS Lambda to read changes from RDS Oracle to Kinesis Data Streams. How do I use the Lambda function to insert data into BigQuery from the Kinesis stream?
You can use the BigQuery streaming API, specifically the tabledata.insertAll method, to insert data into BigQuery. This method is more suitable for small datasets. If the dataset size is large, you can utilize automated data integration platforms like Hevo Data.
2. What is AWS RDS equivalent in GCP?
Google Cloud SQL is the closest equivalent to AWS RDS, offering managed relational databases for MySQL, PostgreSQL, and SQL Server on Google Cloud.
3. How do I migrate my AWS RDS database?
You can use AWS Database Migration Service (DMS), Google Database Migration Service, or third-party tools like Hevo Data to securely transfer data from AWS RDS to your target database.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



