

The change data capture functionality was introduced in SQL Server 2016 SP1. This feature allows SQL Server users to monitor databases and tables and store the changes committed into specifically created CDC tables. The main objective of this post is to introduce you to Apache Kafka so that you can build a strong foundation and understand how to stream change data in your SQL Server database.
In this blog, you will learn how to leverage Apache Kafka to continuously stream DML and DDL events that are committed to your SQL Server tables in real-time so that other applications and services can easily consume them. By the end of this blog, you can seamlessly set up the Kafka CDC SQL Server connection.
Table of Contents
What Is Kafka and Its Uses?

Kafka is a distributed streaming platform based on messaging system principles. It processes new log entries from web servers, sensor data from IoT systems, and stock trades in real-time. As an enterprise Pub/Sub messaging service, Kafka efficiently handles data streaming and event-driven applications.
It also supports stream processing, enabling real-time data transformation and analysis. Additionally, Kafka provides connectors that allow seamless import and export of change records from databases and other systems as they occur.
You will utilize the Debezium SQL Server connector, an open-source distributed platform built on top of Kafka Connect. Debezium is used for streaming rows from SQL Server Change Data Capture (CDC) to Kafka topics.
How to Use Debezium and Kafka?
Use Debezium and Kafka to propagate CDC (Change Data Capture) data from SQL Server to Materialize. Debezium captures row-level changes, such as INSERT, UPDATE, and DELETE operations, in the upstream database, and publishes them as events to Kafka through Kafka Connect-compatible connectors.
Prerequisites
- You will need a Linux VM (or install one in VirtualBox).
- You will need SQL Server Enterprise Edition installed and set up.
- You will need to install the Microsoft ODBC Driver for SQL Server.
SQL Server CDC (Change Data Capture) is essential for real-time data replication and synchronization. Try Hevo’s no-code platform and see how Hevo has helped customers across 45+ countries by offering:
- Real-time data replication with ease.
- CDC Query Mode is used to capture both inserts and updates.
- 150+ connectors(including 60+ free sources)
Don’t just take our word for it—listen to customers, such as Thoughtspot, Postman, and many more, to see why we’re rated 4.4/5 on G2.
Get Started with Hevo for FreeHow to Setup Kafka CDC SQL Server Using Debezium?
- Step 1: Enable CDC For The Table(s) That Should Be Captured By The Connector.
- Step 2: Install Java On Your Linux VM.
- Step 3: Download And Install Apache Kafka.
- Step 4: Download And Install A Debezium Connector.
- Step 5: Start A Kafka Server.
- Step 6: Set Up Kafka Connect for CDC SQL Server Kafka Data Streaming.
- Step 7: Monitor Kafka Logs For Change Data.
Step 1: Enable CDC for the Table(s) That Should Be Captured by the Connector
Step 1.1: Enable CDC for the SQL Server Database
USE TestDB
GO
EXEC sys.sp_cdc_enable_db
GOStep 1.2: Enable CDC for the SQL Server Database Table That You Are Tracking
USE TestDB
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'Posts',
@role_name = N'Admin',
@supports_net_changes = 1
GOStep 2: Install Java on Your Linux Vm
Kafka libs are based on Java; therefore, you should download it and add it to an environment variable.
> sudo yum install java-1.8.0
> export JAVA_HOME=/usr/lib/jvm/jre-1.8.0Step 3: Download and Install Apache Kafka
Download the 2.5.0 release and un-tar it.
> mkdir kafka/
> cd kafka
> wget https://archive.apache.org/dist/kafka/2.5.0/kafka_2.12-2.5.0.tgzz
> tar -xzf kafka_2.12-2.5.0.tgz
> cd kafka_2.12-2.5.0Step 4: Download and Install a Debezium Connector
Download the SQL Server Connector plug-in archive and extract the files into your Kafka Connect environment. Next, add the parent directory of the extracted plug-in(s) to Kafka Connect’s plugin path.
> wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-sqlserver/1.2.0.Final/debezium-connector-sqlserver-1.2.0.Final-plugin.tar.gz
> tar -xzf /kafka/connect/debezium-connector-sqlserver
> plugin.path=/kafka/connectStep 5: Start a Kafka Server
The next step is to start the Kafka server, but Kafka uses Zookeeper — another open-source project that came out of the Hadoop project. Zookeeper is used to coordinate various processes on Kafka’s distributed cluster of brokers.
Kafka provides a CLI tool to start Zookeeper, which is available in your bin directory. On a different CLI window, run the following command:
> bin/zookeeper-server-start.sh config/zookeeper.properties
[2020-07-19 19:08:32,351] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...This tool takes some configurations and we provide a config file with all the default values.
Now, start the Kafka server.
> bin/kafka-server-start.sh config/server.properties
[2020-07-19 19:08:48,052] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2020-07-19 19:08:48,101] INFO Property socket.send.buffer.bytes is overridden to 1044389 (kafka.utils.VerifiableProperties)
...Step 6: Set Up Kafka Connect for CDC SQL Server Kafka Data Streaming
The Kafka Connect configuration can be loaded into Kafka Connect via the REST API. The following example adds the Debezium SQL Server connector configuration in a JSON format.
This example specifies that the Debezium connector instance should monitor a SQL Server instance running at port 1433 on 102.5.232.115.
curl -k -X POST -H "Accept:application/json" -H "Content-Type:application/json" https://localhost:8083/connectors/ -d “
{
"name": "sqlserver-posts-connector",
"config": {
"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector",
"database.hostname": "102.5.232.115",
"database.port": "1433",
"database.user": "admin",
"database.password": "Supersecretpassword!",
"database.dbname": "TestDB",
"database.server.name": "staging",
"table.whitelist": "dbo.Posts",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "dbhistory.Posts"
}
}
”Now, check that the connector is running successfully using this command.
curl -k https://localhost:8083/connectors/sqlserver-posts-connector/statusStep 7: Monitor Kafka Logs for Change Data
If the connector is in RUNNING state, you should see the Connect worker logs indicating the successful ingestion of data from SQL Server to Kafka.
What Is the Easiest Way to Implement CDC?
- You need tech bandwidth and expertise to manage a clean execution. Otherwise, there is the unnecessary risk of getting bogged down in the complexity and the details.
- So, things become much smoother, and opportunities suddenly become abundant when you let the right platform handle this.
- Hevo supports CDC as a replication mode for most sources and Change Tracking for SQL Server Source types and provides an intuitive graphical interface to enable these features. With SQL Server CDC Kafka, you can maintain a detailed activity trail, ensuring real-time data sync to any target system.
Here’s how easy it is to set up SQL Server Change Tracking with Hevo:
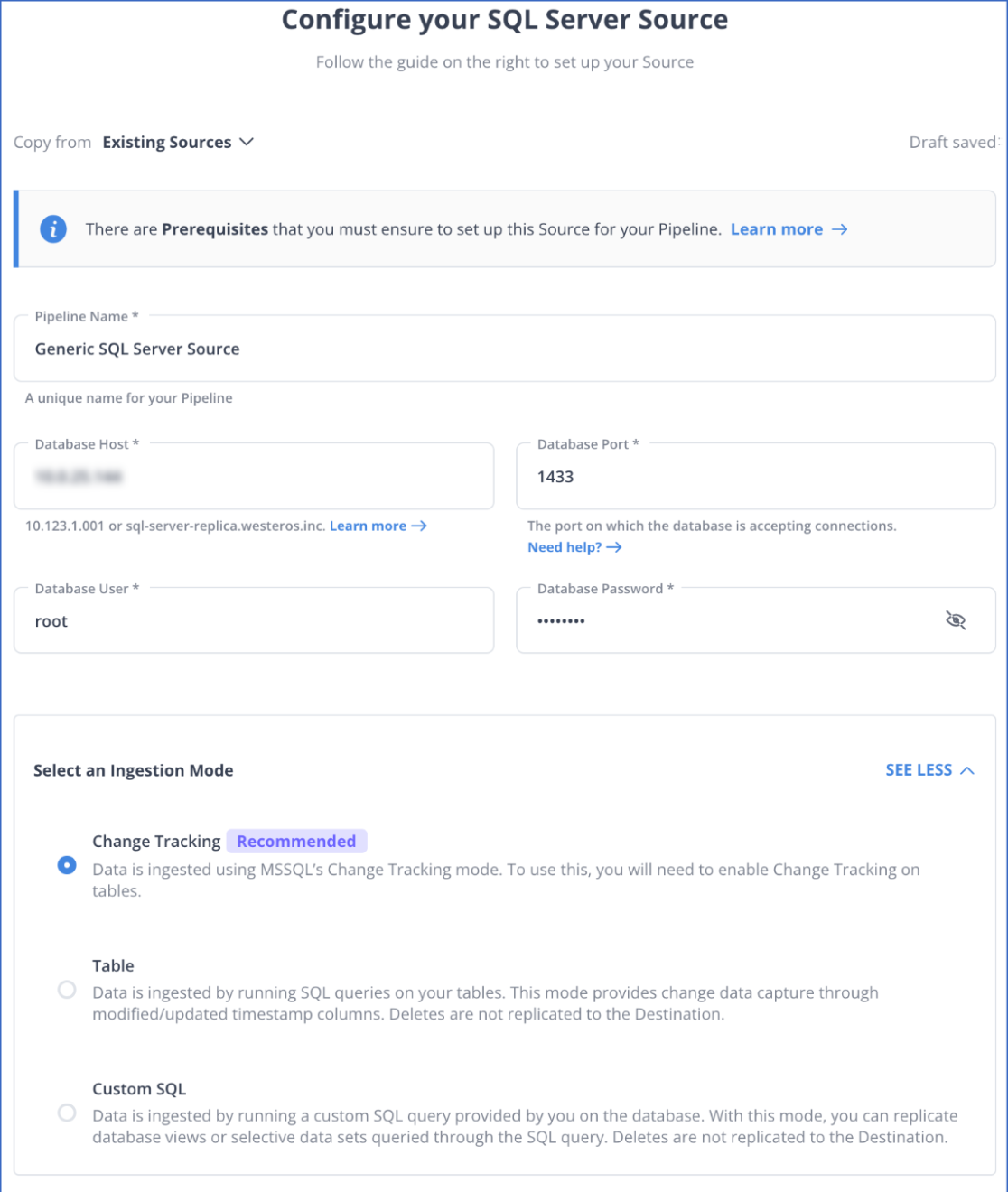
- Authenticate and connect your SQL Server data source.
- Select Change Tracking as your replication mode and configure your destination.



What Are the Benefits of Using SQL Server CDC Source (Debezium) Connector?
The following are the key benefits of the CDC using SQL Server:
- Automatic Topic Creation: Kafka topics are automatically created using the naming convention
<database.server.name>.<schemaName>.<tableName>, with default properties:topic.creation.default.partitions=1andtopic.creation.default.replication.factor=3. - Table Inclusion/Exclusion: Configure which tables to monitor for changes. By default, all non-system tables are monitored.
- Task Limits: Supports running multiple connectors, each limited to one task (
"tasks.max": "1"). - Snapshot Mode: Specify criteria for running snapshots.
- Tombstones on Delete: Option to generate tombstone events after
DELETEoperations (default is true). - Database Authentication: Supports password authentication.
- Output Formats: Supports Avro, JSON Schema, Protobuf, or JSON (schemaless) for record values and keys. Requires Schema Registry for Avro, JSON Schema, or Protobuf formats.
- Incremental Snapshot: Supports incremental snapshotting via signaling.
Learn More:
Conclusion
In this blog, you get a detailed understanding of Kafka. You learned in detail the two methods for setting up SQL Server CDC using Kafka and Hevo.
Most businesses today, however, have an extremely high volume of data with a dynamic structure. Creating a data pipeline from scratch for such data is a complex process since businesses will have to utilize a large amount of resources to develop it and then ensure that it can keep up with the increased data volume and schema variations. Businesses can instead use automated platforms like Hevo.
Hevo helps you directly transfer data from a source of your choice like SQL Server to your desired data warehouse or desired destination in a fully automated and secure manner without having to write the code or export data repeatedly. It will make your life easier and make data migration hassle-free. It is user-friendly, reliable, and secure. You can schedule a personalized demo to learn more about Hevo.
Frequently Asked Questions
1. Can Kafka connect to SQL Server?
Yes, Kafka can connect to SQL Server using Kafka Connect with the JDBC connector, enabling data to be streamed from or to SQL Server.
2. Does Kafka support CDC?
Yes, Kafka supports Change Data Capture (CDC) through connectors like Debezium, allowing it to capture and stream real-time data changes.
3. Does SQL Server support CDC?
SQL Server natively supports Change Tracking to track changes in tables, making it possible to capture inserts, updates, and deletes.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





