

Apache Kafka is an open-source streaming platform that handles and processes real-time messages that can be further used for developing event-based applications. Kafka servers can handle hundreds of billions of real-time messages that are collected from the Kafka producers. Real-time messages can be further used by Kafka consumers to execute several development tasks.
Users can run default Kafka scripts in CLI (Command Line Interface) for producing and consuming messages. On installing Apache Kafka to your local machine, you are provided with several Kafka scripts that allow you to work with several utilities or CLI. Such CLIs can be used for producing and consuming data to and fro the Kafka servers. One such utility is Kafka console consumer, which allows you to access or fetch data from Kafka servers.
On running the Kafka console consumer utility, the Kafka environment starts up a terminal window or command line prompt by which you can execute commands for fetching data right from the Kafka servers.
In this article, you will learn about Kafka, Kafka consumer console, and different ways of processing real-time messages from Kafka topics.
Table of Contents
What is Kafka?

Developed by Linkedin in 2010, Kafka is an open-source and distributed platform that handles, stores, and streams real-time data for building event-driven applications. In other words, Kafka has a distributed set of servers that stores and processes real-time or continuous data collected from producers. Kafka has a vast ecosystem consisting of three main components: Kafka producers, servers or brokers, and consumers. While Kafka producers publish or write data into Kafka servers, Kafka consumers fetch or read messages from the respective Kafka servers. You can also read our in-depth article about Kafka Python.
What is Kafka Console Consumer?
Kafka console consumer is a utility that reads or consumes real-time messages from the Kafka topics present inside Kafka servers. In other words, the Kafka console consumer is a default utility that comes with the Kafka package for reading Kafka messages using the command prompt or command-line interface. The script file called “kafka-console-consumer” present in the bin directory can be used to easily make your default command prompt to act as a consumer or receiving terminal. The Kafka console consumer utility not only consumes or receives messages from Kafka servers, but it can also process and alter messages depending on end users’ or applications’ preferences.
Efficient processing using the Kafka console consumer
Setup the Kafka environment
- For fetching data using the Kafka console consumer, you have to set up the Kafka environment that effectively streams real-time messages from Kafka producer to consumer.
- Initially, you have to download Apache Kafka from the official website and configure the necessary files to set up the Kafka environment. For running Kafka cluster, you should also have Java 8+ pre-installed and running in your local machine. Ensure that you set up the file path and Java_Home environment variables to make your operating system point or head towards the Java utilities.
- In the below steps, you will set up the Zookeeper instance and Kafka server necessary to run the Kafka environment.
- Firstly, you can start and run the Zookeeper instance. Open a new command prompt and run the following command.
bin/zookeeper-server-start.sh config/zookeeper.properties- After the Zookeeper instance is started, execute the following command to start the Kafka server.
bin/kafka-server-start.sh config/server.1.properties- On executing the above commands, both the Zookeeper instance and Kafka servers start and run in your local machine.
- The above-mentioned method is the way of starting your Zookeeper instance and Kafka servers from your local Apache Kafka installation. However, you can also use docker images to easily start the Kafka environment, including Zookeeper, Kafka servers, Schema registry.
- For starting a Kafka application in a docker container, you can use the docker-compose.yml file script, as shown below.
version: '2'
services:
zookeeper :
image: bitnami/zookeeper:3.6.1
ports:
- 2181:2181
environment :
- ALLOW_ANONYMOUS_LOGIN=yes
- ZOO ENABLE_AUTH=yes
kafka :
image: bitnami/kafka:2.5.0
ports :
- 9092:9092
links :
- zookeeper
environment :
- ALLOW_PLAINTEXT_LISTENER=true
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181- Run docker-compose up -d –build and write the above code to launch the docker image.
- After the successful launch of the docker image, two docker containers will boot up. One docker container is for starting Kafka server, while the other container runs the Zookeeper instance.
The above-given steps are the two easy ways to start Kafka server and Zookeeper instances.
Unlock the full potential of your Kafka data with Hevo’s streamlined integration solutions.
- Effortless Setup: Easily connect Kafka to your preferred data destination without any coding.
- Real-Time Streaming: Access and analyze your data as it flows, ensuring timely insights and decision-making.
- Seamless Data Integration: Combine data from Kafka with other sources for comprehensive analysis and reporting.
Transform your real-time data streaming capabilities with Hevo today and join the list of 2000+ happy customers.
Get Started with Hevo for FreeCreating Kafka Topics
- For creating Kafka topics inside Kafka servers, you have to use the script file named kafka-topic.sh that is present in the environment path variable.
- Execute the following commands to create Kafka topics.
- Topic with a single partition and replication factor
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafka_test_topic- Topic with a multiple partitions and a replication factor
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kafka_test_topic_withpartition- On executing the above commands you created two topics named kafka_test_topic and kafka_test_topic_withpartition.


Starting Kafka producer
- After creating Kafka topics, you have to start a Kafka producer console that publishes messages into previously created Kafka topics.
- For starting the Kafka producer console, you will use the kafka-console-producer script file.
- Execute the following command to run the producer console.
./kafka-console-producer.sh --broker-list localhost:9092 --topic kafka_test_topic- After running the above command, the terminal will start acting like a producer console, prompting you to enter messages according to your preferences.
- In the producer console, you can enter messages as shown below.

- You can also publish text files containing messages ready to be produced inside Kafka topics. Execute the following command to publish the text file into a topic named kafka_test_topic_withpartition.
- On executing the above command, you will witness an output that is similar to the image below.
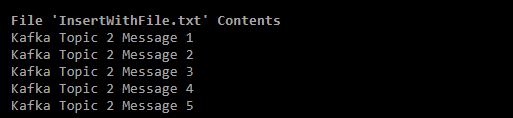
- Now, you have successfully created the Kafka producer console and published messages into Kafka topics.
Processing messages with Kafka console consumer
- In the below steps, you will consume or fetch messages present inside the respective Kafka topics.
- Execute the following commands to fetch all messages from the Kafka topic named kafka_test_topic and kafka_test_topic_withpartition.
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafka_test_topic --from-beginning./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafka_test_topic_withpartition --from-beginning- The output of both the above commands will resemble the images given below.
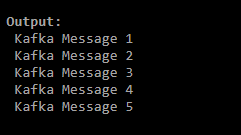
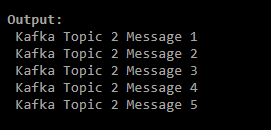
- The command executed previously fetched all messages present in both Kafka topics named kafka_test_topic and kafka_test_topic_withpartition.
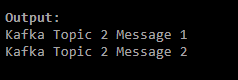
- Using the Kafka console consumer, you can also customize the fetching limit of messages from the Kafka topics. Execute the following command to limit the number of messages that are to be consumed from the respective topics.
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafka_test_topic_withpartition --from-beginning --max-messages 2- On executing the above command, you have limited the Kafka console consumer to only fetch two messages from the Kafka topic. The output will resemble the following image.
- In the next step, you will fetch messages from the particular offset of the Kafka topics. In Kafka servers, messages received from the producers are stored in the ordered sequence inside a topic partition. Those ordered sequences of numbers are called Offset.
- Execute the following command to consume messages from a particular offset and partition.
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafka_test_topic --offset 2 --partition 0- On executing the above command, you fetch messages from offset 2 in partition 0. The output will resemble the following image.
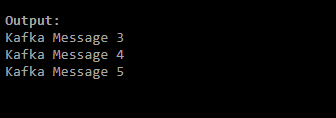
- The Kafka application provides several techniques that ensure safety and security while transferring data from one end to another. Users can effectively process or stream real-time data with high security and privacy on implementing SSL security for both consumers and producers.
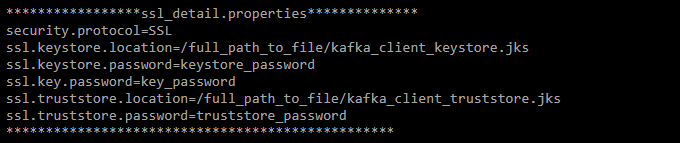
- Security details like Keystore file (kafka_client_keystore.jks), Keystore password, Key password, Truststore file (kafka_client_truststore.jks), Truststore password have to be stored in the properties file. Later while executing commands for producing or consuming messages, the property file has to be used in the command line for securely implementing data streaming operation.
- For example, execute the following command to fetch messages from Kafka topics with SSL security implementation.
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafka_ssl_test_topic --from-beginning --consumer.config ~/files/ssl_detail.properties- In the above command, consumer.config attribute is used to specify SSL properties to the consumer command.
- In the below steps, you will create a consumer group to separately fetch messages from different partitions of the Kafka topic. A consumer group is nothing but a set of consumers that work together to consume messages from specific topics. The partitions of the Kafka topics are divided among the consumers in the group, thereby assigning from which topic each consumer should fetch messages.
- For defining the consumer group, execute the following command.
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=cg_name_1 --topic kafka_test_topic --from-beginning- As shown in the above command, the consumer group can be defined by specifying the key-value pair. In the above command group.id is the key, cg_name_1 is the value, and group.id=cg_name_1 is collectively known as the key-value pair.
- For fetching messages from the Kafka topics using the consumer group, execute the following command.
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafka_test_topic --consumer-property group.id=cg_name_3 --from-beginning- For listing all the previously defined consumer groups, execute the following command.
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list- Kafka allows users to describe a ‘Consumer Group’ and retrieve the metadata information. Such metadata information is internally maintained by Kafka to keep track of messages that have been previously consumed.
- Execute the following command to see all the metadata information about the particular consumer group named cg_name_1.
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group cg_name_1 --describeThe above given are the steps used to effectively consume and process data from Kafka servers.
All image & code credits: DBMS tutorials
Conclusion
In this article, you learned about Kafka, Kafka console consumer, and different ways to process or consume real-time messages from Kafka topics. Since this article mainly focused on the data-consuming part, it covered how to fetch real-time messages from Kafka servers using different consuming techniques.
In this article, you were introduced to Kafka Console Consumer. However, in businesses, extracting complex data from a diverse set of Data Sources can be a challenging task and this is where Hevo saves the day!
FAQ on Kafka Console Consumer
What is the use of Kafka console consumer?
Kafka Console Consumer is a command-line tool used to read messages from a Kafka topic. It allows users to quickly consume and display messages for debugging and testing purposes. You can specify the topic, partition, and other configurations to filter the data you want to see.
What does a Kafka consumer do?
A Kafka consumer subscribes to one or more Kafka topics and processes the messages published to those topics. It reads data from Kafka brokers and can perform various actions based on the messages received, such as storing them in a database, processing them for real-time analytics, or triggering events in other systems.
What is the difference between Kafka listener and Kafka consumer?
Kafka Consumer: This is a client application that subscribes to topics and reads messages from Kafka. It is a lower-level abstraction that directly interacts with Kafka’s API.
Kafka Listener: This is a higher-level abstraction, often part of a framework like Spring Kafka. A Kafka listener is typically an annotation-driven component that processes messages as they arrive, handling the complexities of consumer group management and error handling for the developer.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




