




New technologies and tools for orchestrating tasks and Data Pipelines have recently exploded. Since so many of them exist, it can be challenging to decide which ones to employ and how they interact.
In this guide, you will discuss Kubeflow vs Airflow differences and similarities.
Kubeflow is a Kubernetes-based end-to-end Machine Learning stack orchestration toolkit for deploying, scaling and managing large-scale systems. On the other hand, Airflow is an open-source application for designing, scheduling, and monitoring workflows that are used to orchestrate tasks and Pipelines.
Table of Contents
Overview of Kubeflow
Kubeflow is an open-source machine learning (ML) platform designed to simplify the deployment, orchestration, and scaling of ML workflows on Kubernetes. It enables end-to-end ML lifecycle management, integrating tools for model training, serving, and monitoring in a cloud-native environment.
Key Features of Kubeflow
- Comprehensive Dashboard: Engineers can use K8s to design, deploy, and monitor their models in production thanks to a central dashboard with multi-user isolation.
- Multi-Model Serving: KFServing, Kubeflow’s model serving component, is designed to serve several models simultaneously. With an increase in the number of queries, this strategy quickly uses available cluster resources.
- ML Libraries, Frameworks, & IDEs: Kubeflow is interoperable with data science libraries and frameworks such as Scikit-learn, TensorFlow, PyTorch, MXNet, XGBoost, etc. Users of Kubeflow v1.3+ can launch Jupyter notebook servers, RStudio, or VSCode straight from the dashboard, with the appropriate storage allocated.
- Monitoring & Optimizing Tools: Tensorboard has been integrated into Kubeflow’s service, which helps visualize your ML training process. In addition, Kubeflow incorporates Katib. It is a hyperparameter tweaking tool that runs pipelines with various hyperparameters to get the optimal ML model.
Streamline your ETL processes with Hevo’s no-code platform, designed to automate complex data workflows effortlessly. With an intuitive interface, Hevo enables smooth data extraction, transformation, and loading—all without manual coding.
- Automate ETL pipelines with ease
- Enjoy flexible, real-time data transformations
- Connect to 150+ data sources, including 60+ free sources
See why Hevo is rated 4.7 on Capterra for data integration excellence.
Get Started with Hevo for FreeOverview of Airflow

Apache Airflow is an open-source platform for orchestrating workflows, allowing users to programmatically author, schedule, and monitor complex data pipelines. It provides a rich UI and scalability, making it ideal for managing ETL processes, machine learning workflows, and other automation tasks.
Key Features of Airflow
- Easy to Use: An Airflow data pipeline can be readily set up by anybody familiar with Python. Users can develop ML models, manage infrastructure, and send data without restrictions on pipeline scope.
- Robust Pipelines: Airflow pipelines are simple to implement. Its core is the advanced Jinja template engine, which allows you to parameterize your scripts. Furthermore, users can run pipelines regularly due to the advanced scheduling semantics.
- Extensive Integrations: Airflow offers a big pool of operators ready to operate on the Google Cloud Platform, Amazon Web Services, and various other third-party platforms. Consequently, integrating it into current infrastructure and scaling up to next-generation technologies is clear and simple.
- Pure Python: Users can create data pipelines with Airflow by leveraging basic Python features like data time formats for scheduling and loops for dynamically creating tasks.
Kubeflow vs Airflow: Key Differentiators
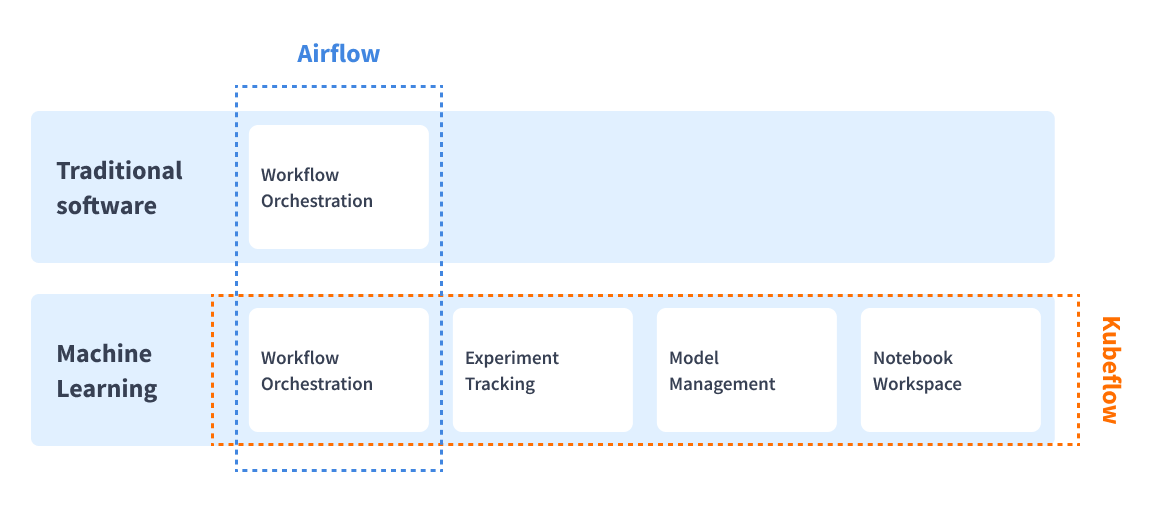
4 critical differentiators that will help in Kubeflow vs Airflow decision.
1. Function
- Airflow is a generic task orchestration tool, whereas Kubeflow concentrates on Machine Learning activities like experiment tracking.
- An experiment in Kubeflow is a workspace that allows you to experiment with alternative pipeline setups.
- Kubeflow is divided into two components: Kubeflow and Kubeflow Pipelines. The latter enables you to specify DAGs, although it focuses more on deployment and model serving than general operations.
2. Kubernetes Requirement
- Kubeflow is designed to run primarily on Kubernetes. It works by letting you configure your Machine Learning components on Kubernetes.
- On the other hand, working with Airflow does not necessitate using Kubernetes. However, it’s worth noting that if you want to run Airflow on Kubernetes, you can do so using the Kubernetes Airflow Operator.
3. GitHub Popularity & Support
- Airflow is used by significantly more engineers and businesses than Kubeflow.
- On GitHub, for example, Airflow has more forks and stars than Kubeflow.
- Airflow is also more often used in enterprise and developer stacks than Kubeflow. Slack, Airbnb, and 9GAG are just a few of the well-known firms that use Airflow. Since Airflow is so widely used, users can get quick help from the community.
4. Use Case
- Airflow is the way to go if you require a mature, comprehensive ecosystem that can handle a wide range of jobs. However, if you currently use Kubernetes and want additional out-of-the-box patterns for machine-learning solutions, Kubeflow is the right choice for you.
- Selecting the right tool for your project is not a piece of cake.
- The above comparison will help make your selection easier. However, the Kubeflow vs Airflow decision involves many more factors, such as team size, team skills, use case, & others.
Similarities between Kubeflow & Airflow
Despite their numerous differences, Kubeflow and Airflow have certain elements in common. The following are some of the similarities between the two tools:
- ML Orchestration: Kubeflow and Airflow can orchestrate Machine Learning pipelines, but they take quite different methods, as discussed above.
- Open-Source: Kubeflow and Airflow are both open-source solutions. That is, they may be accessed by anybody, at any time, from anywhere. Both offer active communities and users, however, Airflow has a more extensive user base than Kubeflow.
- User Interface(UI): Both have an interactive UI. The central dashboard is the interface in Kubeflow that offers simple access to all Kubeflow components installed in your cluster. The user interface in Airflow gives you a complete picture of the status and logs of all tasks, both finished and in progress.
- Python: Both of them leverage Python. For example, you can construct workflows in Airflow using Python functionalities. In Kubeflow, you can also define tasks using Python.
Quick Comparison
| Aspect | Kubeflow | Airflow |
| Primary Use Case | Machine Learning (ML) pipelines and workflows | General-purpose data pipelines and workflow orchestration |
| Core Purpose | End-to-end machine learning workflow management | Scheduling, orchestrating, and managing workflows |
| Scalability | Highly scalable (leverages Kubernetes for scaling) | Scalable, but may require additional tools for large-scale workflows |
| Ease of Use | Complex setup for machine learning workflows | More user-friendly for general workflow management |
| Deployment | Can deploy machine learning models as services | No direct support for deployment, though can orchestrate deployment tasks |
Conclusion
Choosing the best orchestration tool for the use cases can be quite difficult. This post helped you make your Kubeflow vs Airflow decision easier. You not only discovered the Kubeflow vs Airflow differences but also discussed some of the similarities shared. In addition, you gained a basic understanding of key features and components of Kubeflow and Airflow.
Want to understand how the Airflow Kubernetes Operator works? Explore our guide to learn how this operator manages workflows in a Kubernetes environment.
If you are looking for a data pipeline tool that provides you with the best of both Kubeflow and Airflow without the hassle of writing long lines of code, try Hevo. Sign up for a 14-day free trial and experience Hevo’s rich feature set.
FAQs
1. Is Kubeflow based on Airflow?
No, Kubeflow is not based on Airflow. Kubeflow is built on Kubernetes and focuses on machine learning workflows, while Airflow is a general-purpose workflow orchestration tool.
2. What is the difference between Apache Airflow and Kubeflow Pipelines?
Apache Airflow is a general workflow orchestration tool used for scheduling and managing tasks across various domains. Kubeflow Pipelines are specifically designed for managing end-to-end machine learning workflows, with features for model training, tuning, and serving.
3. What are the disadvantages of Kubeflow?
Kubeflow has a steep learning curve and requires substantial Kubernetes resources, making setup and maintenance complex. It also primarily supports ML workflows, limiting general-purpose use.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



