

Many organizations use high availability frameworks for databases to ensure that operations continue in the event of a failure. One such database which follows this strategy is MongoDB.
It was designed with the cloud in mind but now has many advanced features such as providing high availability for MongoDB databases through the use of sharding and replication. It also allows for simple scalability via distributed workloads.
Despite the fact that it can run as a single instance, it is most often used in the form of MongoDB Clusters. In this article, you will gain information about MongoDB Clusters.
Table of Contents
What is MongoDB?

MongoDB is a document-oriented non-relational database (NoSQL database). It is used for high-volume data storage. It also provides support for JSON-like storage.
Since it is a non-relational database, so here instead of data being stored in the form of tables, MongoDB stores data in collections and documents. Documents in MongoDB comprise key-value pairs.
These are the fundamental unit of data in MongoDB. A collection consists of a set of documents. These collections in NoSQL databases are similar to tables in relational databases.
MongoDB has a flexible data model that allows you to store unstructured data. It also provides replication and full indexing support with the help of rich APIs. MongoDB uses JSON and MQL for its querying and interactive purposes.BSON supports data types such as floating-point, long, date, and many others that regular JSON does not.
MQL has more capabilities than regular SQL, making it more relevant for MongoDB because it processes JSON-type documents.
Here is an example of a JSON-like document in a MongoDB database:
{
company_name: "Kinetic Motors",
address: {street: "2nd Avenue", city: "Bengaluru"},
phone_number: "1-800-0000",
industry: ["automobiles", "engines"]
type: "private",
number_of_employees: 1290
}
Hevo Data offers a powerful, no-code ETL solution that supports MongoDB as a source, enabling you to integrate, transform, and load data seamlessly. With Hevo, managing data pipelines is simplified, allowing you to focus on gaining insights rather than worrying about data complexities.
Check out what makes Hevo amazing:
- It has a highly interactive UI, which is easy to use.
- It streamlines your data integration task and allows you to scale horizontally.
- The Hevo team is available around the clock to provide exceptional support to you.
With its automated data handling and no-code interface, Hevo makes building efficient pipelines effortless.
Get Started with Hevo for FreeKey Features of MongoDB
Main features of MongoDB which make it unique are:
- High Performance
- Scalability
- Availability
- Flexibility
1) High Performance
Since MongoDB is a NoSQL database, data operations are quick and simple. Data can be quickly stored, manipulated, and retrieved while maintaining data integrity.
2) Scalability
MongoDB data can be distributed quickly and evenly across a cluster of machines in the Big Data era. MongoDB’s scalability is capable of handling increasing amounts of data.
When the size of the data grows, MongoDB uses sharding to horizontally scale it across multiple servers.
3) Availability
MongoDB makes multiple copies of the same data and sends copies of data across different servers, making data highly available.
In the event that one server fails, data can be retrieved immediately from another server.
4) Flexibility
MongoDB is easily integrated with various Database Management Systems, both SQL and NoSQL.
Because of the document-oriented structure, the MongoDB schema is dynamically flexible, and various types of data can be easily stored and manipulated.
What is a MongoDB Cluster?
Clusters in MongoDB refer to two different architectures. These are as follows:
1) Replica Sets
A MongoDB replica set is a collection of one or more servers that contain an exact copy of the data. While it is possible to have one or two nodes, three is the recommended minimum. A primary node handles read and write operations for your application, while two secondary nodes hold a replica of the data.
If the primary node becomes unavailable for any reason, an election process will be used to select a new primary node. This new primary node is now in charge of read and write operations.
When the faulty server returns to the network, it will sync with the primary node and become a new secondary node in the cluster.
The goal is to provide your application with high data availability. Even if a server fails, your client application can still connect to the cluster and access the data, minimizing potential downtime.
2) Sharded Clusters
A sharded cluster is a method of horizontally scaling your data by distributing it across multiple replica sets. The client sends a request to the router (mongos) whenever a read or write operation is performed on a collection.
The router will then use the configuration server to determine which shard the data is stored in. It then sends the requests to the appropriate cluster.
Each shard has its own replica set. To ensure high availability, you should have more than one configuration server or router. In this architecture, you can scale your database according to your needs.
Setting up MongoDB Clusters
In the following diagram, there are three main components that need to be installed while setting up MongoDB Clusters
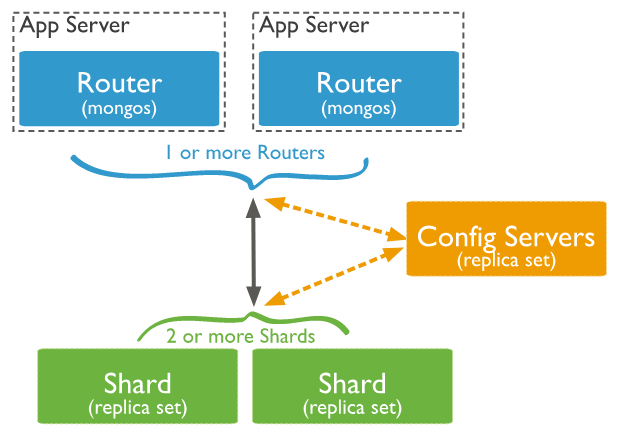
- Shard Server: Data is stored in shards. They offer high availability as well as data consistency. Each shard in a production environment is a separate replica set.
- Config Servers: The metadata of the cluster is stored on configuration servers. This data contains a mapping of the data set of the cluster to the shards.
- This metadata is used by the query router to direct operations to specific shards. Sharded clusters in production have exactly three configuration servers.
- Query Routers: Query routers are mongo instances that interact with client applications and route operations to the appropriate shard. The query router processes and routes operations to shards before returning results to clients.
- A sharded cluster can have multiple query routers to distribute client request load. A client sends queries to a single query router. A sharded cluster typically has a large number of query routers.
Steps to Set up MongoDB Clusters
The steps followed to set up MongoDB Clusters are as follows:
1) MongoDB Clusters: Setting Up Config Server
The steps to be followed are as follows:
- Log in to the config server.
- After logging in, now you can edit the config file according to your requirements.
- You can write about your requirements in the /etc/mongodConfig.conf file. You can go through the following code snippet for this process and paste it in the /etc/mongodConfig.conf file.
storage:
dbPath: /var/lib/mongodb
journal:
enabled: true
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongodConfig.log
net:
port: 27019
bindIp: 172.31.46.15
sharding:
clusterRole: configsvr
replication:
replSetName: ConfigReplSetThe meaning of the different fields in the code snippet is as follows:
storage:
dbPath: /var/lib/mongodb
journal:
enabled: true
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongodConfig.log
net:
port: 27019
bindIp: 172.31.46.15
sharding:
clusterRole: configsvr
replication:
replSetName: ConfigReplSetFor each process, the log is given a specific same. It indicates which process the log is for.
port: 27019
bindIp: 172.31.46.15Here, we make it explicitly clear that by default the config server will run on port 27019 in a clustered configuration. We mention the IP address here such that other servers can easily locate our server.
sharding:
clusterRole: configsvrHere sharding indicates that the server is distributed according to a hashtag schema. And we inform MongoDB that the cluster is a config server instead of a sharing server.
replication:
replSetName: ConfigReplSetIt indicates the configuration data is to be replicated. You can use rs.() functions to further any replicas and you can use any name for this purpose.
- Now, you can start the process. For that you can write the following code:
sudo mongod --config /etc/mongodConfig.conf&- Now, you can check the logs for any errors. You can write the following code for this purpose.
sudo tail -100 /var/log/mongodb/mongodConfig.log- Now, you can log in to the Mongo shell. For that, write the following code.
mongo 172.31.46.15:27019- Next, you can turn on replication by using the rs.initiate() function. You can check the status of replication using rs.status() function. You can refer to the following code:
> rs.initiate()
{
"info2" : "no configuration specified. Using a default configuration for the set",
"me" : "172.31.46.15:27019",
"ok" : 1,
"operationTime" : Timestamp(1548598138, 1),
"$gleStats" : {
"lastOpTime" : Timestamp(1548598138, 1),
"electionId" : ObjectId("000000000000000000000000")
},
"lastCommittedOpTime" : Timestamp(0, 0),
"$clusterTime" : {
"clusterTime" : Timestamp(1548598138, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
ConfigReplSet:SECONDARY> rs.status()
{
"set" : "ConfigReplSet",Here, you can notice that the name of the replication set you have configured in the config file has its name as ConfigRepISet.
2) MongoDB Clusters: Configure Query Router
The steps to be followed to configure query router for setting up MongoDB Clusters are as follows:
- Login to the Config server.
- Now, you can write the code for editing the config file. You can refer to the following code:
sudo vim /etc/mongoRouter.conf- For editing the file, you can paste the following code to set your requirements.
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongoRouter.log
net:
port: 27017
bindIp: 172.31.46.15
sharding:
configDB: ConfigReplSet/172.31.46.15:27019Here, configDB: ConfigReplSet/172.31.46.15:27019 indicates the query editor about the location of the config server and their replica sets.
- Now you can start the service. In the following code, the “s” in mongos is a sign of the query router process.
sudo mongos --config /etc/mongoRouter.conf&- You can check the log for any errors.
mongo 172.31.46.15:270173) MongoDB Clusters: Configure Shard
The steps to be followed to configure shards in the process of setting up MongoDB Clusters are as follows:
- Log in to the database server.
- Now, you can write the code for editing the config file. You can refer the following code:
sudo vim /etc/mongodShard.conf- For editing the file, you can paste the following code to set your requirements.
storage:
dbPath: /var/lib/mongodb
journal:
enabled: true
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongodShard.log
net:
port: 27018
bindIp: 172.31.47.43
sharding:
clusterRole: shardsvr
replication:
replSetName: ShardReplSet- The meaning of the different fields in the code snippet is as follows:
clusterRole: shardsvrThis indicates that it is a shard server instead of a config server.
replSetName: ShardReplSetHere, this indicates that now you can replicate the data. You are telling the config server to replicate the configuration.
port: 27018Here, we make it explicitly clear that by default the shard servers will run on port 27018 in a clustered configuration.
- Now, you can start the process. For that you can write the following code:
sudo mongod --config /etc/mongodShard.conf&- Now, you can check the logs for any errors. You can write the following code for this purpose.
sudo tail -f /var/log/mongodb/mongodShard.log- Now, you can log in to the Mongo shell. For that, write the following code.
mongo 172.31.47.43:27018- Next, you can turn on replication by using the rs.initiate() function. You can check the status of replication using rs.status() function. You can refer to the following code:
rs.initiate()
{
"info2" : "no configuration specified. Using a default configuration for the set",
"me" : "172.31.47.43:27018",
"ok" : 1,
"operationTime" : Timestamp(1548602253, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1548602253, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
ShardReplSet:SECONDARY> rs.status()
{
"set" : "ShardReplSet",- Here, “set” : “ShardReplSet” instructs to name the shards as “ShardRepISet” and you need to endure that the same name is used across all shards in the cluster.

4) MongoDB Clusters: Add Shard to Cluster
The steps to be followed to add shards to a cluster in the process of setting up MongoDB Clusters are as follows:
- You can go to the config server. And, you can connect to the router using the following code:
mongo 172.31.46.15:27017- Now, go to the Mongo shell and write the following commands.
sh.addShard( "ShardReplSet/172.31.47.43:27018")
{
"shardAdded" : "ShardReplSet",
"ok" : 1,
"operationTime" : Timestamp(1548602529, 4),
"$clusterTime" : {
"clusterTime" : Timestamp(1548602529, 4),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}- Now, you can create a database. In this case, a database named “books” is created. And following that, you can enable sharding for the database. You can refer to the following commands:
use books
switched to db books
sh.enableSharding("books")
{
"ok" : 1,
"operationTime" : Timestamp(1548602601, 6),
"$clusterTime" : {
"clusterTime" : Timestamp(1548602601, 6),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}- Now, refer to the following commands for creating a collection.
db.createCollection("collection")
{
"ok" : 1,
"operationTime" : Timestamp(1548602659, 5),
"$clusterTime" : {
"clusterTime" : Timestamp(1548602659, 5),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}- Now, you can create an index. Here, the field “isbn” is indexed in descending order.
db.collection.createIndex( { isbn: -1 } )
{
"raw" : {
"ShardReplSet/172.31.47.43:27018" : {
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
},
"ok" : 1,
"operationTime" : Timestamp(1548602670, 9),
"$clusterTime" : {
"clusterTime" : Timestamp(1548602670, 9),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}- You can add records to the collection. For adding a record, you can refer to the following commands.
db.collection.insertOne( { isbn: 100 } )
{
"acknowledged" : true,
"insertedId" : ObjectId("5c4dcd69e83741cb900b46f8")
}- Now, turn on sharding for the collection.
sh.shardCollection("books.collection", { isbn : "hashed" } )
{
"collectionsharded" : "books.collection",
"collectionUUID" : UUID("0d10320b-3086-472e-a3ac-4be67fae21f9"),
"ok" : 1,
"operationTime" : Timestamp(1548603537, 12),
"$clusterTime" : {
"clusterTime" : Timestamp(1548603537, 12),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}- Now, you need to verify that the data is distributed across the cluster. In this case, since you have one database server, so it will just show one.
db.collection.getShardDistribution()
Shard ShardReplSet at ShardReplSet/172.31.47.43:27018
data : 0B docs : 0 chunks : 2
estimated data per chunk : 0B
estimated docs per chunk : 0
Totals
data : 0B docs : 0 chunks : 2
Shard ShardReplSet contains NaN% data, NaN% docs in cluster, avg obj siz
Conclusion
In this article, you explored MongoDB Clusters, including their key features, architectures, and the steps for setting them up. By understanding how MongoDB works, you can effectively manage and scale your database. To simplify the ETL process, Hevo Data offers seamless integration with MongoDB, ensuring smooth data migration and transformation without any hassle. Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
FAQs
1. How many nodes are in MongoDB cluster?
A MongoDB cluster typically consists of at least three nodes: primary, secondary, and arbiter.
2. What is the difference between node and cluster in MongoDB?
A node is an individual server, while a cluster refers to a group of nodes working together for replication and sharding.
3. What is a cluster in a database?
A cluster is a collection of databases or servers working together to distribute data, ensure high availability, and improve performance.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




