




You are going about your day setting up and operating your organization’s data infrastructure and preparing it for further analysis. Suddenly, you get a request from one of your team members to replicate data from PagerDuty to BigQuery.
We are here to help you out with this requirement. You can transfer data from PagerDuty to BigQuery using custom ETL scripts. Or you can pick an automated tool to do the heavy lifting. This article provides a step-by-step guide to both of them.
Table of Contents
What is PagerDuty?
PagerDuty is an on-call scheduling platform and incident management built to help teams detect critical issues, triage, and resolve them in real-time.
It’s integrated with a number of monitoring tools that alert the right people in the case of a problem automation of workflows, so rapid response in case of outages or system failure.
PagerDuty is predominantly utilized within DevOps and IT operations concerning various activities that may improve uptime, reliance, and teamwork during an incident.
What is BigQuery?
BigQuery is a fully managed, serverless data warehouse solution that enables big data sets to be analyzed quickly through SQL-based analytics. Companies use it as a high-performance way to run complex queries across big data sets. Its capabilities in real-time analysis, besides integrations with other Google Cloud services, include machine learning, geospatial analysis, and federated querying of external data sources.
Check out the various data types supported by BigQuery.
Ensure zero-data loss with Hevo’s automated no-code platform that supports 150+ sources (60+ free sources), including PagerDuty, to the destination of your choice, such as BigQuery, within seconds. Here’s why you should try Hevo:
- Transform your data with custom Python scripts or using the drag-and-drop feature.
- Forget about manually mapping the schema into the destination with automapping.
- Connect with Live Support, available 24/5, and chat with data engineers.
With a 4.3 rating on G2, see how industry leaders like BeepKart transformed their data management with Hevo.
Get Started with Hevo for FreeHow to Connect PagerDuty to BigQuery?
To replicate data from PagerDuty to BigQuery, you can either use CSV files or a no-code automated solution. We’ll cover replication via CSV files next.
Method 1: Export PagerDuty to BigQuery using CSV Files
The steps to save these reports as CSV files are mentioned below:
Step 1: Click Export CSV to produce a file, that will make the view and results determined by the selections made on the search and filters.

NOTE: Large reports such as the Incident Activity Report will otherwise be fetched in the background and delivered to the requesting user by email.

Step 2: A success banner is shown on the Insights page till the report is delivered.

Step 3: Click the link in the success banner or email to view your report in .csv format.
To import the CSV files into BigQuery, follow the steps given below:
- Step 1: To load CSV data into a new BigQuery table, navigate to “Explorer” > “Dataset info.” Click on “Create table” on the BigQuery page.
- Step 2: In the Create Table panel, specify the following details:
- Select “Google Cloud Storage” from the “Create table” list in the Source section.
- In the Destination section, select the dataset you want to create and enter the table name. Set Table type to Native Table.
- In the Schema section, enter the schema definition.
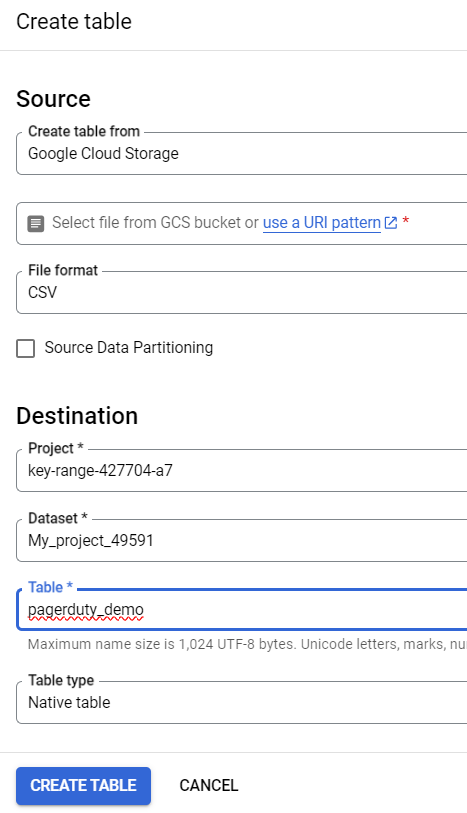
- Step 3: Click on Create Table.
Best Scenarios to Use Manual Data Replication
- One-Time Data Replication: When your business teams require these PagerDuty files quarterly, annually, or for a single occasion, manual effort and time are justified.
- No Transformation of Data Required: This strategy offers limited data transformation options. Therefore, it is ideal if the data in your spreadsheets is accurate, standardized, and presented in a suitable format for analysis.
- Less Number of Files: If fewer CSV files need to be managed, downloaded, and uploaded, then the manual method becomes feasible.
Limitations of Manual Data Replication
- When your business teams require fresh data from multiple reports every few hours, they must clean and standardize it to make sense of it in various formats.
- This eventually causes you to devote substantial engineering bandwidth to creating new data connectors.
- To ensure a replication with zero data loss, you must monitor any changes to these connectors and fix data pipelines ad hoc.

Method 2: Automate the Data Replication process using a No-Code Tool
Going all the way to use CSV files for every new data connector request is not the most efficient and economical solution. Frequent breakages, pipeline errors, and lack of data flow monitoring make scaling such a system a nightmare. You can streamline the PagerDuty to BigQuery data integration process in minutes using Hevo’s automated platform in just two steps.
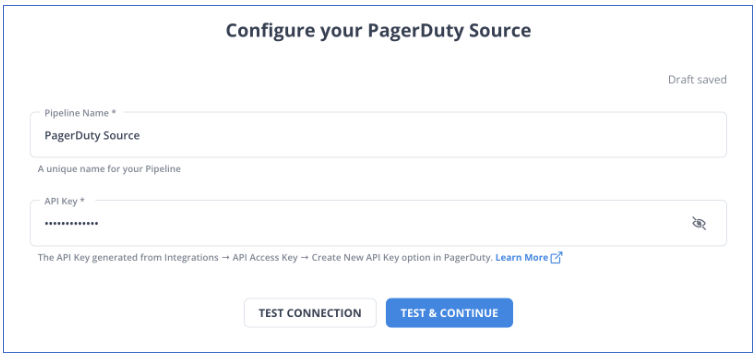
Step 1: Configure PagerDuty as a Source
Configure PagerDuty as the source in Hevo Data.
Step 2: Configure BigQuery as a Destination
Configure Google BigQuery as your Destination.

You can also visit the official documentation of Hevo Data for PagerDuty as a source and Google BigQuery as a destination to have in-depth knowledge about the process.
Hevo Data’s reliable data pipeline platform enables you to set up zero-code and zero-maintenance data pipelines that just work. By employing Hevo Data to simplify your data integration needs, you can leverage its salient features:
- Fully Managed: You don’t need to dedicate any time to building your pipelines. With Hevo Data’s dashboard, you can monitor all the processes in your pipeline, thus giving you complete control over it.
- Data Transformation: Hevo Data provides a simple interface to cleanse, modify, and transform your data through drag-and-drop features and Python scripts. It can accommodate multiple use cases with its pre-load and post-load transformation capabilities.
- Faster Insight Generation: Hevo Data offers near real-time data replication, so you have access to real-time insight generation and faster decision-making.
- Schema Management: With Hevo Data’s auto schema mapping feature, all your mappings will be automatically detected and managed to the destination schema.
- Scalable Infrastructure: With the increase in the number of sources and volume of data, Hevo Data can automatically scale horizontally, handling millions of records per minute with minimal latency.
- Transparent pricing: You can select your pricing plan based on your requirements. Different plans are put together on its website, as well as all the features it supports. You can adjust your credit limits and spend notifications for increased data flow.
- Live Support: The support team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Key achievements of PagerDuty to BigQuery Integration
Here are a few benefits of replicating data from PagerDuty to BigQuery:
- Centralizing the data: Using data from your company, you can create a single customer view to analyze your projects and team performance.
- Detailed customer insights: Combine all data from all channels to comprehend the customer journey and produce insights that may be used at various points in the sales funnel.
- Boost client satisfaction: Analyze customer interaction through email, chat, phone, and other channels. Combine this data with consumer touchpoints from other channels to identify drivers to improve customer pleasure.
Wrapping it Up
Data requests from your marketing and product teams can be effectively fulfilled by replicating data from PagerDuty to BigQuery. If data replication occurs every few hours, you must switch to a custom data pipeline. This is crucial for marketers, as they require continuous updates on the ROI of their marketing campaigns and channels.
Instead of spending months developing and maintaining such data integrations, you can enjoy a smooth ride with Hevo Data’s 150+ plug-and-play integrations (including 60+ free sources such as PagerDuty).
BigQuery’s “serverless” architecture prioritizes scalability and query speed and enables you to scale and conduct ad hoc analyses much more quickly than with cloud-based server structures. The cherry on top is that Hevo Data will make it simpler by making the data replication process very fast!
Want to take Hevo Data for a ride? Sign Up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
FAQs
1. Can I schedule regular data exports from PagerDuty to BigQuery?
PagerDuty doesn’t offer built-in scheduling for data exports. However, you can automate this process using third-party tools or scripts that regularly extract PagerDuty data via the API, save it in CSV format, and upload it to BigQuery on a set schedule.
2. How do I manage data security when transferring PagerDuty data to BigQuery?
To ensure data security during transfer, you should use secure methods like Google Cloud Storage’s encrypted buckets and PagerDuty’s API with OAuth authentication.
3. Can I integrate PagerDuty with BigQuery without using CSV files?
Yes, you can bypass CSV files by using the PagerDuty API to directly stream data into BigQuery via ETL tools or custom scripts.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



