



Easily move your data from PagerDuty To Snowflake to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
You are going about your day setting up your organization’s data infrastructure and preparing it for further analysis. Suddenly, you get a request from one of your team members to replicate data from PagerDuty to Snowflake.
We are here to help you out with this requirement. You can perform PagerDuty to Snowflake Integration using custom ETL scripts. Or you can pick an automated tool to do the heavy lifting. This article provides a step-by-step guide to both of them.
Table of Contents
What is PagerDuty?
PagerDuty is a cloud-based incident management platform designed to help IT and DevOps teams detect, resolve, and prevent issues in real time. It automates incident response by alerting the right team members based on predefined escalation policies, ensuring that critical issues are addressed promptly.
Key Features of PagerDuty
- Real-Time Alerts: Sends alerts via SMS, phone calls, email, or push notifications.
- Incident Management: Tracks and manages incidents from detection to resolution.
- On-Call Scheduling: Automates on-call scheduling and escalations to ensure incidents are never missed.
- Integration: Supports integration with monitoring tools like Datadog, AWS CloudWatch, Slack, and Jira.
What is Snowflake?
Snowflake is a fully managed SaaS that provides one platform for data warehousing, data lakes, data engineering, data science, and data application development while ensuring the secure sharing and consumption of real-time/shared data. It offers a cloud-based data storage and analytics service called data warehouse-as-a-service. Organizations can use it to store and analyze data using cloud-based hardware and software.
Want to predict Snowflake costs? Our Pricing calculator is designed for precision and ease.
Key Features of Snowflake
- Multi-cluster shared data architecture: It allows point-to-point scaling of computing resources independent of storage.
- Separate Storage and Compute: Optimizes cost performance with the ability to independently scale storage and compute.
- Data Security with Sharing: Enables data sharing in real-time without losing privacy and security.
- Data Governance and Compliance: Advanced security features incorporate end-to-end encryption, complying with regulations.
Looking for the best ETL tools to connect your Snowflake account? Rest assured, Hevo’s no-code platform seamlessly integrates with Snowflake streamlining your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Simplify data mapping with an intuitive, user-friendly interface.
- Instantly load and sync your transformed data into Snowflake.
Choose Hevo and see why Deliverr says- “The combination of Hevo and Snowflake has worked best for us. ”
Get Started with Hevo for FreeHow to Load Data from PagerDuty to Snowflake?
Method 1: Using Hevo for Effortlessly Transferring Data from PagerDuty to Snowflake
Step 1: Connect PagerDuty as your Source.
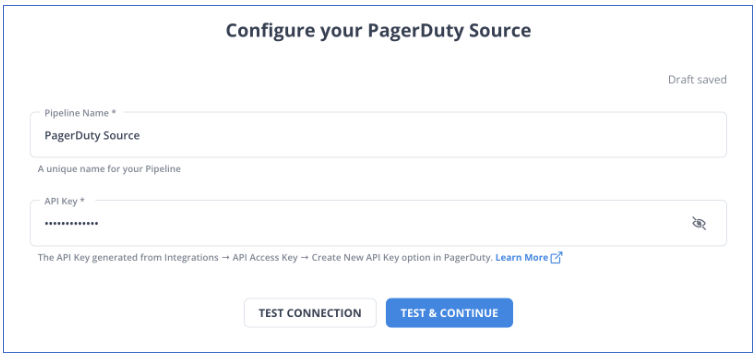
Step 2: Connect Snowflake as your destination

Method 2: The Long and Tedious Manual Method to Connect PagerDuty to Snowflake
Step 1: Download Incidents as CSV:
- Go to your PagerDuty account.
- Navigate to Incidents or Analytics from the sidebar.
- Use the export to CSV feature for incidents or alert data.
- Select the date range and other filters you need and download the CSV file.
Step 2: Upload the CSV File to Snowflake
- Ensure that the CSV is in correct, clean, well-structured format. A typical PagerDuty incident CSV file might include columns such as incident_id, status, urgency, triggered_at, etc.
- Choose the Database you want to load this data to
Use database [database-name];- Create a Table in Snowflake
CREATE [ OR REPLACE ] TABLE [ ( [ ] , [ ] , ... ) ] ;- Now load the CSV data file from your local system to the staging of the Snowflake using the PUT command.
put file://D:\dezyre_emp.csv @DEMO_DB.PUBLIC.%dezyre_employees;- Copy the data into the target table
copy into dezyre_employees
from @%dezyre_employees
file_format = (format_name = 'my_csv_format' , error_on_column_count_mismatch=false)
pattern = '.*dezyre_emp.csv.gz'
on_error = 'skip_file';You can also perform this by directly uploading the file by using Snowflake’s UI. Now query this data to check data validity and integrity.
What can you hope to achieve by replicating data from PagerDuty to Snowflake?
- You can centralize the data for your project. Using data from your company, you can create a single customer view to analyze your projects and team performance.
- Get more detailed customer insights. Combine all data from all channels to comprehend the customer journey and produce insights that may be used at various points in the sales funnel.
- You can also boost client satisfaction. Analyze customer interaction through email, chat, phone, and other channels. Identify drivers to improve customer pleasure by combining this data with consumer touchpoints from other channels.
Use Cases of Connecting PagerDuty with Snowflake
- Incident Response Optimization: Track and evaluate PagerDuty incident response metrics (e.g., time to acknowledge, time to resolve) in Snowflake to improve response workflows.
- Incident Data Analysis: Load PagerDuty incident logs into Snowflake for in-depth analysis of incidents, response times, and resolution efficiency.
- Operational Insights: Combine PagerDuty data with other operational metrics in Snowflake to generate comprehensive reports on system reliability and performance.
- Alert Trend Analysis: Analyze historical PagerDuty alerts in Snowflake to identify recurring issues, peak alert times, and optimize alert thresholds.

Key Takeaways
These data requests from your marketing and product teams can be effectively fulfilled by replicating data from PagerDuty to Snowflake. If data replication must occur every few hours, you will have to switch to a custom data pipeline. This is crucial for marketers, as they require continuous updates on the ROI of their marketing campaigns and channels. Instead of spending months developing and maintaining such data integrations, you can enjoy a smooth ride with Hevo’s 150+ plug-and-play integrations (including 40+ free sources such as PagerDuty).
Snowflake’s “serverless” architecture prioritizes scalability and query speed and enables you to scale and conduct ad hoc analyses much more quickly than with cloud-based server structures. The cherry on top — Hevo will make it even simpler by making the data replication process very fast!
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. How do I connect my RDS to Snowflake?
–Extract data from RDS using AWS services like AWS DMS (Database Migration Service) or third-party ETL tools like Hevo.
–Load the extracted data into Snowflake by connecting AWS S3 to Snowflake using the COPY INTO command, or use ETL tools to automate the data transfer
2. Can Snowflake connect to API?
Snowflake does not natively connect directly to external APIs
3. What devices are compatible with PagerDuty?
–Mobile Devices: iOS and Android devices via the PagerDuty mobile app.
–Web Browsers: Any device with modern browsers like Chrome, Firefox, Safari, or Edge can access the PagerDuty web interface.
–Communication Devices: PagerDuty integrates with phones (SMS/calls), emails, and other communication channels like Slack or Microsoft Teams for notifications
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



