



Data Mining is an important process that leverages information from enterprise data. Data Mining helps in creating a holistic view of the data and finding patterns in the data to gain insights. Pattern finding in Data Mining helps in finding hidden information which is not possible using traditional Data Mining methodologies.
In this article, we will discuss the importance of Pattern Discovery in Data Mining, methods to detect patterns, and some use cases of Pattern Discovery in Data Mining. We will also discuss some common problems encountered during the Pattern Discovery in Data Mining process, with a view to avoid those problems and discover useful patterns only.
Table of Contents
What is Data Mining?
Data mining is the process of transforming huge volumes of raw data into useful information and gaining meaningful insights. It has nothing to do with the extraction/assimilation of data, in fact, existing data volumes are its input only.
It’s done with a clearly defined purpose in mind, and its end result is to present its findings in an easily comprehensible manner, such that it can aid decision-making.
Under the Data Mining hood, various parallel activities like Data Management, Pre-processing, Data Warehousing, Pipelining and loading of data for a particular purpose, creation of Machine-Learning/Artificial Intelligence models, analyzing the data via these models and existing statistical methods, Pattern Discovery and Pattern Analysis, and finally visualizing the facts uncovered, etc. are performed.
Probably, Knowledge Discovery in Data (KDD) or Data Analysis would be a more appropriate term for it.
Why is it Important to Recognize a Pattern?
Apart from the usual mathematical calculations like totals/correlations/variations/ratios/derivatives etc., there is a lot more information that is lying covered inside your data. A pattern could show an emerging trend, a receding factor, ups and downs of a certain behaviour, seasonal variations, etc., amongst many other facts.
A pattern generally shows that there exists some useful information waiting to be unearthed from the data. Here, we will discuss patterns as they occur in Data Science and some intricacies of pattern discovery in data mining.
To keep the discussion simple, we will not discuss minute details of tools/algorithms used in pattern discovery.
What is Pattern Discovery in Data Mining?
A pattern is something that repeats itself given a set of conditions or a set of rules. Recognizing patterns leads to useful information, eases decision making, and makes our tasks simpler.
Some of the different types of patterns that one could see in data are:-
- Periodic Patterns: These are patterns that are seen repeating themselves after a certain lapse of time. This type of pattern is frequently encountered in time series data, biological sequences, spatiotemporal (has both time + space dimensions) data, etc.
- Associative Patterns: These are like Bread and Butter/Knife and Fork,
i.e. co-occurring groups of things that make more sense with each other. The members of this pattern are complementary to each other. - Abnormal Patterns: This kind of pattern occurs when the data has a clear deviation from normal behaviour, an unexpected pattern appears between expected patterns and its appearance is not periodic.
- Structural Patterns: Like pathfinding in graphs or cluster identification > An example would be low-cost residences tend to occur in suburbs whereas downtown has higher costing apartments.

- Chaotic Patterns: Here the patterns appear but have no definitive characteristic related to time/space/frequency.
Where do Pattern Discovery and Pattern Recognition find their Major Applications?
Pattern Discovery in Data Mining and analysis are very useful in:
- Sentiment and Trend Analysis: Here patterns can give you insights into the sentiments or mood of your customers/investors. Whether the sentiment is upswing or positive, which could lead to an increase in demand and price, or if it’s negative. Also, you can uncover trends like if something is being liked by the masses or getting unpopular.
This application has widespread usage in e-commerce, the retail industry, investment banking, voting patterns, etc. - Image Processing & Computer vision: A computer is imparted human-like skills to recognize things by processing their outward features, orientations, and actions.
- Bioinformatics: Large and complex biological datasets can be processed to know the side effects of drugs, the onset of a pandemic, deficiencies of a population, genetic basis of diseases, or changes at the molecular/cellular level.
- Forensic Analysis and DNA Sequencing: Knowing the biological parents of someone or identifying a culprit by remnants of his hair/sputum/skin etc.
- Forecasting and Probabilistic Estimation: Weather forecasting, forecasting changes in consumer behavior, estimating if a new product would get popular with a subset of the target population.
- Assistance and Support Automation: Assisting people and providing better support via the use of technology, automating redundant daily tasks to focus more on the crucial ones thereby increasing employee productivity.
- Seismic Analysis: Analysing if a building will stay safe during earthquakes/hurricanes, providing structures with seismic stability.
- Speech Recognition: As the name suggests, it’s about recognizing the speakers amongst a set of preloaded voices, deciphering the message/intent the speaker wishes to convey, etc.
Pattern Discovery in Data Mining can be done via various techniques and tools.
What are Some Methods of Pattern Discovery in Data?
Though a human eye can detect patterns when the data is small, the huge volume of data in question needs to be handled differently. Some of the prevalent methods of Pattern Discovery in Data Mining are:
1) Through Self-developed Customized Programs
If your dataset is not huge or your pattern recognition requirements are simple, you can consider developing your own custom program to run through the data and perform Pattern Discovery in Data Mining. This way you could have a lot of flexibility and customizability built into your program, to suit your specific requirements.
This approach also provides you with total control over your pattern discovery process, and you’re not constrained by the capabilities of a third-party tool. Most of today’s programming languages have mature existing libraries to aid you in pattern detection.
E.g. Python has PyTorch for Deep Learning and OpenCV for Computer Vision, Java has JADEPT (JAva DEsign Pattern deTector), and Tesseract OCR, JavaScript has node-Tesseract and etc.
2) Through Machine Learning
In Machine Learning, you first create a Machine Learning Model. A model here is a program that is trained to recognize patterns or similarities in behaviour. While creating a model, you fill it with a set of instructions, similar to a program, and then you train it on sample data.
E.g. You can train a model to recognize a boat in a picture, akin to what you see in captchas.
So, you can train the model by first making it learn to recognize a boat shape. This will include some programmatic instructions to measure/gauge the shapes and contours of objects and then recognize a boat-shaped structure.
Next, you train that model by feeding it pictures that contain a boat and a few other objects within the same image. After some practice, the model becomes fairly perfect in recognizing boats inside pictures.
Now, this model can be used to detect all images that contain boat(s) from a stream of images. Similarly, a trained Machine Learning Model is used to detect patterns/trends/similarities in behaviour, while reading a stream of incoming data.
Now, Who Feeds the Model with the Data?
It’s your Machine Learning Algorithm that first loads and pre-processes data, and then feeds it to the trained model. So another important aspect here is the algorithm.
You can create algorithms that use trained models to recognize Linear Regression, classify entities based on detected characteristics or cluster similar objects together.
In practice, you will have a set of Machine Learning Algorithms, packaged as a library or provided as an API, to be used for pattern discovery as well as many other functions.
What are the Major Steps that are Executed in the Process?
Pattern Discovery in Data Mining via Machine Learning (ML) can be broken into these major steps:
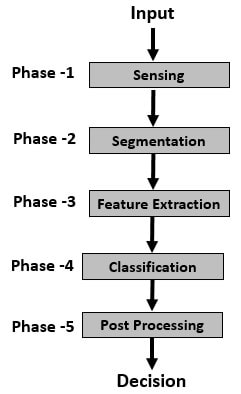
Step 1: Sensing Data
The input data can be sporadic/irregular/chunky, so in this phase, the Pattern Recognition system smoothens the input data into continuous/analogous data.
Step 2: Data Segmentation
In this phase, the system will try to eliminate the noise and isolate the useful/sensed objects.
Step 3: Feature Extraction
This phase takes the pruned data as input, all the useful objects are further processed and their features/properties are identified, and then the data is sent for further classification.
Step 4: Classification
In this phase, the sensed objects are grouped/classified based on their properties. The data is now ready to be fed to the model/rule system.
Step 5: Post-processing
Here, further considerations are made before a final Pattern Discovery in Data Mining or pattern recognition is made.
What are the Problems Encountered during Pattern Discovery in Data Mining?
One could encounter problems and false positives while using Pattern Discovery in Data Mining. Some of these could be:
- Since Data Mining tools are generally not good at detecting poor quality data, this poor quality data if it exists may lead to false patterns or improbable patterns. So before concluding that there exists a useful pattern, one must make sure that the data that the pattern emerges from, is of good quality.
- Some patterns are quite obvious even without Data Mining, such patterns should be kept aside while arriving at any conclusion.
- Some patterns will not pass the test of time, e.g. buying patterns of dwellers of a village are of no use if the population in question migrated away from that area due to some reason.
- Compare carefully and generalize sparingly – what are the odds that someone will survive being hit by 2 gunshots?
- The probability of someone surviving a single gunshot is very low.
- But the probability of someone surviving 2 gunshots is close to even when you compare it with people who have never received a gunshot. Because to calculate this probability you will have to include those people who have already survived 1 gunshot.
- Hence, a highly improbable event might seem plausible if compared with the inappropriate fact.
- At times you will need to discern that though a pattern exists, it’s not pointing to any useful information or does not represent something relevant to your purpose.
Conclusion
Pattern Discovery in Data Mining improves the efficiency and quality of Insights. Patterns help in understanding the data better, as well as provide more meaning to data. Pattern Discovery in Data Mining is a 5 step process that is discussed in detail. To conclude, we have discussed Pattern Discovery in Data Mining in simple terms, and how to make the best use of it, in your Big Data Analytics practice.
There are various Data Sources that organizations leverage to capture a variety of valuable data points. But, transferring data from these sources into a Data Warehouse for a holistic analysis is a hectic task. It requires you to code and maintains complex functions that can help achieve a smooth flow of data. An Automated Data Pipeline helps in solving this issue and this is where Hevo comes into the picture. Hevo Data is a No-code Data Pipeline and has awesome 150+ pre-built Integrations that you can choose from.
visit our website to explore hevoHevo can help you Integrate your data from 100+ data sources and load them into a destination to analyze real-time data at an affordable price. It will make your life easier and Data Migration hassle-free. It is user-friendly, reliable, and secure.
SIGN UP for a 14-day free trial and see the difference!
Share your experience of learning about Pattern Discovery in Data Mining in the comments section below.
Frequently Asked Questions
1. What is the discovery of patterns in data?
Discovery of patterns in data refers to the process of identifying regularities, trends, or relationships within large datasets.
2. What is a pattern discovery?
Pattern discovery in data mining is the process of identifying significant patterns, correlations, or anomalies within data.
3. What is pattern in data mining with example?
A pattern in data mining is a representation of meaningful relationships or regularities within data. Patterns can be various types such as clusters, associations, sequences, or trends.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



