



The advent of the internet coincided with the rise of distributed systems. More services now have to support a massive number of users. For many such services, it is no longer feasible to store data on a single server no matter how large the server. Data now has to be distributed not only to cater to the increased workload but to make sure that production systems do not have a single point of failure. It is within this narrative that the need to have a replication strategy for databases becomes paramount.
In this blog post, you are not only going to learn the Postgres replication types but also about the theoretical underpinnings of replication, the reasons for replication and you will also be exposed to hands-on replication examples using the PostgreSQL database engine. This article assumes that the reader is familiar with the concept of a database and how transactions are applied. The reader will also need access to a simple text editor as you will be editing some configuration files.
Table of Contents
What is PostgreSQL?

PostgreSQL is an open-source relational database management system (RDBMS) that prides itself on extensibility and strict SQL compliance. It is widely used in production systems and it has been under active development since its initial release in 1996. PostgreSQL can be used as the database layer for web applications. It can also be used as a data warehouse or for analytics/business intelligence applications.
What is Replication?
The generic definition of replication is the act of copying or reproducing an entity such that there exist multiple copies. The concept of replication in databases is closely related to the standard definition. Database replication is the process of sharing information between two or more databases. In layman’s terms, it is the act of copying data from one database instance to another.
Replication could occur between databases hosted on the same physical machine or across the network. The database which acts as the active node on which changes initially occur is known as the main/master/primary/publisher while the other databases that receive the changes subsequently (in effect, copies the data), are known as the standby/slave/secondary/subscriber. Throughout the rest of this article, for the purpose of consistency, the Main-Standby nomenclature will be used.
There are multiple ways to classify replication depending on perspective, so in the next few sections, you will go through each of those.
Migrating your data from PostgreSQL doesn’t have to be complex. Relax and go for a seamless migration using Hevo’s no-code platform. With Hevo, you can:
- Effortlessly extract data from postgreSQL and other 150+ connectors.
- Tailor your data to the destination’s needs with features like drag-and-drop and custom Python scripts.
- Achieve lightning-fast data loading, making your data analysis ready.
Try to see why customers have upgraded to a powerful data and analytics stack by incorporating Hevo!
Get Started with Hevo for FreeSynchronous Versus Asynchronous Replication
In synchronous replication under Postgres Replication Types, when the main node receives a write transaction, it propagates that change to all standby nodes and receives a confirmation before the transaction is committed or marked as completed. This way the data is identical across all nodes and is said to be consistent. Whereas, in asynchronous replication, when the main node receives a transaction, it goes ahead to commit the transaction before propagating that change to standby nodes. It does so with an expectation that the changes propagated to standby nodes will be committed but it does not wait for a confirmation.
This means that there will always be a lag between the main node and standbys. It is also important to note that there is a brief window within which data loss could occur if the main node fails before it can propagate changes to the standbys unless a special failure mechanism is implemented to guarantee eventual consistency, however, the very nature of asynchronous replication means that the possibility of data loss in such a scenario cannot be completely ruled out.
Theoretically, synchronous replication has the advantage of being consistent but in practice, it is usually expensive to implement and in many cases outright infeasible. It is for this reason that most database replication processes adopt the asynchronous approach.
Synchronous/Asynchronous Setup
On the primary server, synchronous standby names in postgresql.conf is used to set up the synchronous setup. You can specify the servers to be synced and the order of priority for COMMIT if there are several standby servers. Asynchronous standby servers will be used if this parameter is not supplied.
‘synchronous standby names = FIRST 2 (s1, s2, s3)’, for example.
You can optionally define how synchronous standby servers are selected from a list of servers, such as ‘FIRST n (list)’ or ‘ANY n (list)’. The FIRST keyword indicates that the first n standby servers in the list will be synchronous, and that transaction commitments will be delayed until the first n standby servers’ WAL records are replicated. The ANY keyword indicates that transaction commitments should be delayed until their WAL records have been replicated to at least n standby servers in the list.
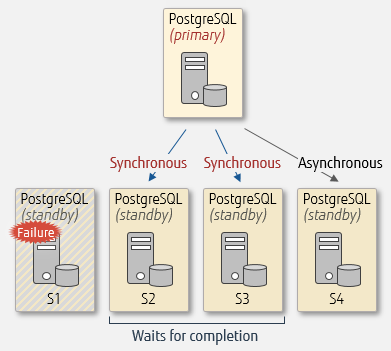
Setting synchronous standby names to ‘FIRST 2 (s1, s2, s3)’ in an environment with standby servers s1, s2, s3, and s4 will setup s1 and s2 for Postgres Replication Types: synchronous replication and s3 and s4 for asynchronous replication. Before committing, the primary server will wait for s1 and s2 to finish processing. In the event that s1 or s2 fail, s3 switches to synchronous replication.
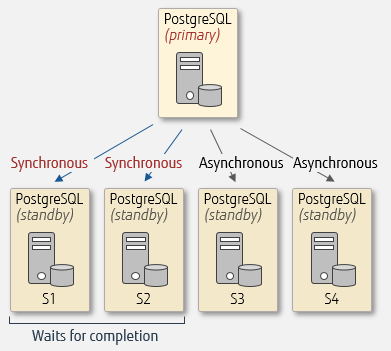
Make that the name set in synchronous standby names on the standby server matches the name set in application name of primary conninfo in postgresql.conf. This parameter will be addressed in greater detail later in this text.
Setting the Synchronization Level
Set synchronous commit in postgresql.conf on the primary server to set the synchronisation level of the standby server. The values that can be set and their overview are described in this section. The numbers in the table’s ‘Guaranteed range’ column correspond to the numbers in the diagram just below it.
| Sync level | Set value | Overview | Guaranteed range |
| Full synchronous | remote_apply | Commits are not made until the WAL has been replicated to the standby servers and the new data has been made available to read-only queries. It is highly suited for load balancing of read-only workloads that demand data freshness because the data is guaranteed to be in sync. | 1 to 9 |
| Synchronous | on (default) | Commits wait until after the WAL is replicated to the standby servers. This setting achieves the best balance between performance and reliability. | 1 to 6 |
| Semi-synchronous | remote_write | Commits aren’t made until the WAL has been replicated to the backup servers. This configuration gives the optimal performance and reliability balance. | 1 to 5 |
| Asynchronous | local | Commits aren’t made until the primary server’s WAL write is finished. | 1 to 2 |
| Asynchronous | off | Commits do not wait for the primary server’s WAL write to finish. This is not a good setting to use. | 1 |
Differences Between Synchronous and Asynchronous
The distinction between Postgres Replication Types: synchronous and asynchronous replication is whether or not the primary server waits for a response from the standby server before proceeding with the processing. Choose the configuration that best suits your needs, since it has an impact on SQL processing response time and high availability.
Postgres Replication Types: Synchronous Replication
- Before completing a procedure, the primary server waits for a response from the standby server.
- As a result, the log shipping time is included in the overall response time.
- Because WAL shipping to the standby server is not delayed, the standby server’s data freshness (reliability) is improved.
- Suitable for read-only load balancing and failover procedures.
Postgres Replication Types: Asynchronous Replication (default)
- The primary server completes a task without waiting for the standby server to respond.
- As a result, the overall response time is similar to when no streaming replication is performed.
- Due to the asynchronous nature of WAL shipping and its application (data update) on the standby server, the updated result on the primary server may not be available immediately on the standby server.
- Data loss may occur depending on the time of the failover.
- Suitable for disaster recovery replication to remote locations.
Single Master Versus Multi-Master Replication
Another classification of Postgres Replication Types is the single master versus multi-master replication. In a single master/main setup, there is only one active node that can receive write and read transactions. All other nodes can only perform read operations. The main is the only node on which write operations can be carried out, it then propagates the transaction to other nodes.
On the other hand, in a multi-master replication under Postgres Replication Types, more than one node can receive write/read transactions. Even though this means writing can be carried out faster, it introduces a level of complexity to the setup. Conflicts between different database nodes must be handled gracefully because writes can occur anywhere and therefore the state of the data needs to be synchronized.
Logical Versus Physical Replication
The core idea of physical replication in Postgres Replication Types is that it tries to preserve the state of the physical system as much as possible to encode changes that take place at the database level. Therefore, physical replication deals with binary format while logical replication is only concerned about copying the data to make sure that it is identical to the change that occurred, without being biased about how that is achieved. Logical replication is preferred when moving between database versions, even if it is slightly more complicated to set up when compared to physical replication.
Why is Replication Important?
There are three main reasons for which databases are replicated, namely – high availability, load balancing, and disaster recovery. High availability refers to the ability to have an up-to-date copy of your database at all times. This means that in the event of a failure of your main database, the standby copy can be promoted to main and you can start receiving traffic.
Load balancing refers to the practice of distributing incoming requests to your application in a way that is balanced so that no particular database experiences an uneven workload. With replication, this is possible since multiple copies of the data exist at any point in time.
The final reason for replication is the need for effective disaster recovery in the event of a systemic failure.
What are the Types of Replication in PostgreSQL?
PostgreSQL supports multiple Postgres Replication Types out of the box. It is also extensible with third-party solutions that are geared towards specific use cases as there isn’t a one size fits all solution that can serve as a magic bullet for all use cases. There will always be tradeoffs that will depend on the business need you are trying to solve. For the rest of this article, you will be introduced to two such techniques for Postgres Replication Types: streaming replication and logical replication.
Postgres Replication Types: PostgreSQL Streaming Replication
The first type in Postgres Replication Types is Streaming Replication. Streaming replication is especially useful in setting up a high availability system as failover can easily be performed because the database clusters are identical. Below is a walkthrough of the procedure required to set it up.
You must create a user in the main database with a replication role that will be used by standby databases to access the main database. To do this, launch the psql terminal-based frontend for PostgreSQL and issue the following command:
CREATE USER your_user REPLICATION;Next, add the user you just created to the pg_hba.conf as shown below:
# TYPE DATABASE USER ADDRESS METHOD
host replication your_user <ip address range> trustYou then have to take a backup of the standby PostgreSQL cluster. To do that use the PostgreSQL utility pg_basebackup and issue the following command from your regular terminal:
pg_basebackup -h <primary-ip> -U your_user -D ~/standbyGo over to the postgresql.conf configuration file and make changes as shown below:
wal_level=replica
max_wal_senders = 5The wal_level should be set to replica and max_wal_senders should be the number of standby connections to allow, in our example it is 5.
Finally, on each standby, create a recovery.conf and populate it with the following entries. On starting the standbys nodes after making the changes below, they will connect to the main database and begin replicating its data via streaming:
standby_mode=on
primary_conninfo='user=your_user host=<primary-ip> port=<primary-port>'Postgres Replication Types: PostgreSQL Replication Using Hevo Data

The second type in Postgres Replication types is Hevo Data. Hevo Data, an Automated No Code Data Pipeline, helps you replicate data from PostgreSQL to Data Warehouses, Business Intelligence Tools, or any other destination of your choice in a completely hassle-free & automated manner. Hevo supports data ingestion replication from PostgreSQL servers via Write Ahead Logs (WALs) set at the logical level.
Use Hevo’s no-code data pipeline to replicate data from PostgreSQL to a destination of your choice in a seamless and automated way. Try our 14-day full feature access free trial.
Hevo also provides you with an all-in-one solution for replicating data from Amazon Aurora PostgreSQL, Amazon RDS PostgreSQL, Azure PostgreSQL, and various other PostgreSQL sources. This way you can focus more on your Data Analysis and let Hevo manage the PostgreSQL Data Replication.
To learn more, check out Hevo’s documentation for PostgreSQL Replication.

Postgres Replication Types: PostgreSQL Logical Replication
The third type in Postgres Replication types is Logical replication. Logical replication in PostgreSQL can be used to copy individual tables instead of an entire database. Do note, however, that because it supports data flow in multiple directions, conflicts could arise and there should be a procedure in place to handle those occurrences. Below is a full example of implementing Postgres Replication Types: Logical replication in PostgreSQL.
The first step is to create a database user in the main database with a replication role like so:
CREATE USER your_user REPLICATION;Add the newly created user to pg_hba.conf file to enable client authentication:
# TYPE DATABASE USER ADDRESS METHOD
host replication your_user <ip address range> trustIn the postgresql.conf configuration file of either the main or standby, set wal_level to logical:
wal_level=logicalOn the main database, create a publication for the tables you want to replicate:
CREATE PUBLICATION your_publication FOR TABLE table1, table2;Then on the standby database recreate the exact tables you want to replicate, maintaining the table structures, in this example that will be table1 and table2. You should then create a subscription on the standby database for the publication you created earlier on the main database, using the command below:
CREATE SUBSCRIPTION your_subscription CONNECTION 'host=<primary-ip> port=<primary-port> user=your_user' PUBLICATION your_publication;That is all that is needed to set up PostgreSQL Replication Types: Logical replication on PostgreSQL.
Hevo also supports Logical Replication in Postgres Replication Types. Hevo Data, a No-code Data Pipeline, helps load data from any data source such as Databases, SaaS applications, Cloud Storage, SDKs, and Streaming Services and simplifies the ETL process. It supports 150+ Data Sources such as Postgres, including 60+ Free Sources. It is a 3-step process by just selecting the data source, providing valid credentials, and choosing the destination.
Benefits and Use Cases of PostgreSQL Replication
Benefits of PostgreSQL Replication
- Improved Availability: By replicating data across multiple servers, replication ensures your database is always available, even if one server fails.
- Load Balancing: Replication allows you to distribute read operations across multiple replica servers, reducing the load on the master server and improving performance.
- Disaster Recovery: In case of a failure, replication helps quickly restore data from replica servers, minimizing downtime.
- Data Redundancy: Replication keeps copies of your data on different servers, providing a backup in case of hardware failure or data loss.
Use Cases of PostgreSQL Replication
- High-Availability Applications: For applications that require constant uptime, such as e-commerce sites or financial platforms.
- Reporting and Analytics: Replication allows read-heavy operations like reporting to be offloaded to replica servers, ensuring that performance is not affected on the master server.
- Geographically Distributed Systems: When your users are spread across different locations, replication helps serve data from the nearest replica for faster access.
- Backup and Disaster Recovery: Use replication to create copies of your database that can be quickly promoted to a primary in the event of a failure.
Conclusion
In this article, you have been introduced to the concept of replication and Postgres Replication Types and its various classification schemes. A discussion on some of the reasons for database replication was also touched upon. Furthermore, you were guided through streaming and logical replication in Postgres Replication Types and how to implement the same. You should now be well equipped to use database replication as a tool in your arsenal to design highly available and fault-tolerant systems. There is more to learn, do check out the official PostgreSQL documentation on these topics to get a deeper dive or consider exploring third-party solutions that offer a managed experience.
Hevo Data provides an Automated No-code Data Pipeline that empowers you to overcome the above-mentioned limitations. Hevo caters to 150+ data sources (including 60+ free sources) and can seamlessly perform PostgreSQL Replication in real-time. Hevo’s fault-tolerant architecture ensures a consistent and secure replication of your PostgreSQL data. It will make your life easier and make Data Replication hassle-free.
Sign Up and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable Hevo pricing that will help you choose the right plan for your business needs.
FAQ
1. What different types of streaming replications are present in Postgres?
There are several types of streaming replication mechanisms available in PostgreSQL: 1. Physical Replication
2. Logical Replication
3. Synchronous Replication
4. Asynchronous Replication
2. What are the 3 types of replication in SQL Server?
SQL Server supports three main types of replication, each with its own use cases and mechanisms:
1. Snapshot Replication
2. Transactional Replication
3. Merge Replication
3. What are the 5 stages of replication?
Here are the five key stages of replication:
1. Snapshot Creation
2. Log Reader
3. Distribution
4. Delivery
5. Conflict Resolution





