




The rate of data generation has increased throughout this century at a predictable rate more or less. According to Seagate UK, “By 2025, there will be 175 zettabytes of data in the global data-sphere”. Companies place a higher value on data.
Companies are discovering new ways to use data to their advantage. They use data to analyze the current status of their business, forecast the future, model their customers, avoid threats and develop new goods. Data Engineering is the linchpin in all these activities.
Table of Contents
What is Python?

Python is one of the most popular programming languages. It is an open-source, high-level, object-oriented programming language created by Guido van Rossum. Python’s simple, easy-to-learn and readable syntax makes it easy to understand and helps you write short-line codes. In addition to this, Python has an ocean of libraries that serve a plethora of use cases in the field of Data Engineering, Data Science, Artificial Intelligence, and many more. Some popular examples include Pandas, NumPy, SciPy, among many others.
Python lets you work quickly and integrate systems more efficiently. It has a huge robust global community with many tech giants like Google, Facebook, Netflix, IBM having dependencies on it. Python allows interactive testing and debugging of code snippets and provides interfaces to all major commercial databases. Python for Data Engineering uses all the features of Python and fine-tunes it for all your Data Engineering needs.
What is Data Engineering?

Data Engineering is becoming popular with the large volume, variety, and velocity of technology changes. The phrase “Data Engineer” came into being around 2011, in the circles of emerging data-driven organizations such as Facebook and Airbnb. Data Engineering has grown to reflect a role that has moved away from standard ETL tools and has built its tools for managing rising data volumes. With Big Data growing, Data Engineering describes a sort of Software Engineering, which focuses on data – Data Infrastructure, Data Warehousing, Data Mining, Data Modelling, Data Crunching, and Metadata Management.
Data Engineering aims ultimately at providing ordered, consistent data flow to permit the processing of data such as:
- Training Machine Learning models
- Perform Exploratory Data Analysis
- Populate fields with External Data in an application
It is imperative nowadays that enterprises require abundant Data Engineers to provide the foundations for effective Data Science projects in the context of full digital corporate transformations, the Internet of Things, and the race to become AI-drifty. Data Engineers create and build pipelines for the transformation and transfer of information in such a way that it is beneficial for Data Scientists, Data Analysts, or other end-users. Briefly, a Data Engineer is in charge of managing a large number of data and sending this data into Data Science Pipelines.
Python for Data Engineering uses all the concepts of Data Engineering and applies that to a versatile language like Python.
Significance of Python for Data Engineering
Now that you got a brief overview of both Python and Data Engineering, let’s discuss the significance of Python for Data Engineering is important. Key programming abilities are necessary for a general understanding of Data Engineering and Pipelines. For Data Analysis and Pipelines, Python is primarily employed. Python is a general-purpose programming language that is becoming ever more popular for Data Engineering. Companies all over the world use Python for their data to obtain insights and a competitive edge.
Sitting on mountains of potentially lucrative real-time data, these organizations required Software Engineers to design tools for handling all the data rapidly and efficiently. In order to work with data, Data Engineers utilize specialized tools. The way data is modeled, stored, safeguarded, and encoded must be considered. These teams must also know how to access and handle the data efficiently. Hence, knowledge of core programming languages like Python is a must.
Leverage Hevo’s built-in Python environment for powerful data transformations within your pipeline. Modify incoming data streams by adding, changing, or removing fields, and even merge data from multiple sources.
Create tailored datasets that perfectly align with your business needs, all within the robust Hevo pipeline.
Start Transforming TodayCritical Aspects of Data Engineering using Python
Now that you have got a brief understanding of Python and Data Engineering, this section mentions some critical aspects that highlight the role of Python for Data Engineering. It mainly comprises Data Wrangling such as reshaping, aggregating, joining disparate sources, small-scale ETL, API interaction, and automation.
- For numerous reasons, Python is popular. Its ubiquity is one of the greatest advantages. Python is one of the world’s three leading programming languages. For instance, in November 2020 it ranked second in the TIOBE Community Index and third in the 2020 Developer Survey of Stack Overflow.
- Python is a general-purpose, programming language. Because of its ease of use and various libraries for accessing databases and storage technologies, it has become a popular tool to execute ETL jobs. Many teams use Python for Data Engineering rather than an ETL tool because it is more versatile and powerful for these activities.
- Machine Learning and AI teams also use Python widely. Teams working together closely, typically have to communicate in the same language, while Python is the lingua franca in the field.
- Another reason Python is more popular is its use in technologies such as Apache Airflow and libraries for popular tools such as Apache Spark. If you have tools like these in your business, it is important to know the languages you utilize.
These are just a few reasons how important the role of Python for Data Engineering is in today’s world.
Pros of Data Engineering using Python over Java

In this section, you will explore the various benefits of Python for Data Engineering over Java. These are some of the reasons Python for Data Engineering is popular rather than Java. Python has a broad range of characteristics that distinguish it from other languages of programming. Some of those features are given below:
- Ease-of-Use: Both are expressive and we can achieve a high functionality level with them. Python is more user-friendly and concise. Python’s simple, easy-to-learn and read syntax makes it easy to understand and helps you write short-line codes as compared to Java.
- Learning Curve: In addition to having support communities, they are both functional and object-oriented languages. Because of its high-level functional characteristics, Java is a bit more complex than Python to master. For simple intuitive logic, Python is preferable, whereas Java is better used in complex workflows. Concise syntax and good standard libraries are provided by Python.
- Wide Applications: The biggest benefit of Python over Java is the simplicity of use in Data Science, Big Data, Data Mining, Artificial Intelligence, and Machine Learning.
Top 5 Python Packages used in Data Engineering

Python provides an ample amount of libraries and packages for various applications. In this section, we will discuss the top 5 Python for Data Engineering packages. The top 5 Python packages include:
1) Pandas
Pandas is a Python open-source package that offers high-performance, simple-to-use data structures and tools to analyze data. Pandas is the ideal Python for Data Engineering tool to wrangle or manipulate data. It is meant to handle, read, aggregate, and visualize data quickly and easily.
2) pygrametl
pygrametl delivers commonly used programmatic ETL development functionalities and allows the user to rapidly build effective, fully programmable ETL flows.
3) petl
petl is a Python library for the broad purpose of extracting, manipulating, and loading data tables. It offers a broad range of functions to convert tables with little lines of code, in addition to supporting data imports from CSV, JSON, and SQL.
4) Beautiful Soup
Beautiful Soup is a prominent online scraping and parsing tool on the data extraction front. It provides Python for Data Engineering tools to parse hierarchical information formats, including on the web, for example, HTML pages or JSON files.
5) SciPy
The SciPy module offers a large array of numerical and scientific methods used in Python for Data Engineering that are used by an engineer to carry out computations and solve problems.
Use Cases of Python for Data Engineering

Today, data is crucial to every company. Companies utilize data to answer business questions like what’s valuable for a new client, how can I enhance my website, or what is the most rapidly expanding products.
Companies of all sizes are able to combine large quantities of heterogeneous data to answer crucial business issues. The process is supported by Data Engineering, which allows data consumers, such as Data Analysts, Data Researchers, and Managers, a secure, reliable, fast, and complete inspection of all available data. So, let’s explore how organizations use Python for Data Engineering:
1) Data Acquisition
Sourcing data from APIs or through Web Crawlers involves the use of Python. Moreover, scheduling and orchestrating ETL jobs using platforms such as Airflow, require Python skills. To implement these ETL processes efficiently, you can refer to our comprehensive resource on ETL using Python.
2) Data Manipulation
Python libraries such as Pandas allow for the manipulation of small datasets. In addition to this, Python for Data Engineering provides a pySpark interface that allows manipulation on large datasets using Spark clusters.
3) Data Modelling
Python is used for running Machine Learning or Deep Learning jobs, using frameworks like Tensorflow/Keras, Scikit-learn, Pytorch. So, Python for Data Engineering becomes a common language to effectively communicate between different teams.
4) Data Surfacing
Various data surface approaches exist, including the provision of data into a dashboard or conventional report, or the opening of data simply as a service. Python for Data Engineering is required for setting up APIs to surface the data or models, with frameworks such as Flask, Django.
These use cases highlight the importance of Python for Data Engineering in our world.
What Do Data Engineers Do?
Data Engineering is a wide discipline with many different names. It may not even have a formal title in many organizations. As a result, it’s usually preferable to start by defining the aims of python for data engineering before discussing the types of labor that lead to the intended outputs.
Data engineering’s ultimate purpose is to offer an ordered, consistent data flow that enables data-driven activity, such as:
- Machine learning models are being trained.
- Analyzing data in an exploratory manner
- Using external data to populate fields in an application
This data flow can be accomplished in a variety of ways, with different toolsets, strategies, and abilities required depending on the team, organization, and desired goals. The data pipeline, on the other hand, is a prevalent pattern. This is a system made up of separate programs that perform various operations on data coming in or being collected.
Data pipelines are frequently split between different servers:
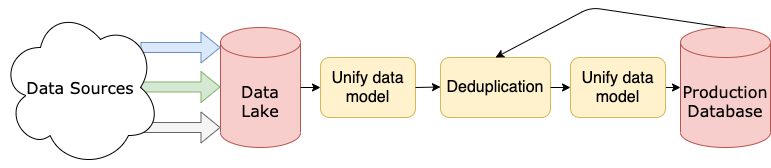
This picture depicts a simplified data pipeline to give you an idea of the type of architecture you can encounter.
What Are the Responsibilities of Data Engineers?
The customers who rely on Data Engineers are as diverse as the data engineering teams’ abilities and results. Your clients will always choose what problems you solve and how you solve them, regardless of what field you pursue.
Through the prism of their data demands, you’ll learn about a few common customers of data engineering teams in this section:
- Teams of data scientists and artificial intelligence experts
- Teams in charge of business intelligence or analytics
- Product management teams
Certain requirements must be completed before any of these groups can function properly. For Python for Data Engineering in use, data must, in particular, be:
- The data is reliably routed into the larger system.
- Normalized to a data model that makes sense
- To fill in essential gaps, it was cleaned.
- All members that are relevant to the group are able to access it.
As a Data Engineer, you’re in charge of meeting your customers’ data requirements. To accommodate their unique operations, you’ll use a range of ways.
Data Flow
Before you can do anything with data in a system, you must first verify that it can flow consistently into and out of it. Inputs can be nearly any type of information you can think of, such as:
- JSON or XML data streams in real-time
- Every hour, batches of videos are updated.
- Data from monthly blood draws
- Batches of labeled photos are sent out once a week.
- Sensor data collected via a telemetry
Data Normalizing and Modeling
It’s fantastic to have data coming into a system. However, the data must eventually conform to some sort of architectural norm. Data Normalization entails procedures that make information more accessible to consumers. The following steps are included, but not limited to:
- Getting rid of duplicates (deduplication)
- Resolving data inconsistencies
- Data is conformed to a specific data model.
Data Cleaning
Data cleansing and data normalization go hand in hand. Data normalization is sometimes considered a subcategory of data cleansing. However, while data normalization focuses on bringing fragmented data into alignment with a data model, data cleaning encompasses a variety of procedures that make data more uniform and complete, such as:
- The same data is cast into a single type (for example, forcing strings in an integer field to be integers)
- Ascertaining that dates are formatted in the same way
- If at all possible, filling in the blanks
- Limiting the values of a field to a certain range
- Data that is corrupt or unusable is removed.
Data Accessibility
Although data accessibility may not receive the same level of attention as data standardization and cleansing, it is perhaps one of the most critical roles of a customer-centric data engineering team.
The ease with which clients may obtain and interpret data is referred to as data accessibility. Depending on the consumer, this term is defined in a variety of ways:
- Data science teams may just require data that can be accessed using a query language.
- Data categorized by metric, available via basic queries or a reporting interface, may be preferred by analytics teams.
- With an eye toward product performance and reliability, product teams may typically desire data that can be accessed through simple and fast queries that don’t change frequently.
What Are Common Data Engineering Skills?
The abilities required in python for data engineering are basically the same as those required for software engineering. However, data engineers tend to concentrate their efforts on a few areas. You’ll learn about numerous crucial skill sets for Python for Data Engineering in this section:
- Programming fundamentals
- Databases
- Cloud engineering and distributed systems
Each of these skills will help you become a well-rounded Data Engineer.
How Data Engineering is different from Data Science, Business Intelligence, Machine Learning Engineering?
Many fields are closely related to data engineering, and your customers are likely to come from these fields. Knowing your clients is crucial, so learn about these topics and how they differ from data engineering.
Some of the fields that are closely related to data engineering are as follows:
- Data Science
- Business Intelligence
- Machine learning engineering
Starting with data science, we’ll take a closer look at these topics in this section.
Data Science
If Data Engineering is concerned with how large amounts of data are moved and organized, data science is concerned with what that data is used for.
Data scientists frequently query, study, and try to draw conclusions from large databases. They may construct one-off scripts for use with a given dataset, whereas data engineers tend to apply software engineering best practices to create reusable programs.
Statistical methods like k-means Clustering and regression, as well as machine learning approaches, are used by data scientists. They frequently use R or Python to extract insights and predictions from data that may be used to assist decision-making at all levels of a company.
Data scientists frequently have a scientific or statistical background, which is reflected in their work approach. They work on a project that answers a specific research issue, while a data engineering team works on creating internal products that are extendable, reusable, and quick.
Business Intelligence
With a few key distinctions, business intelligence is akin to data science. Whereas data science is concerned with predicting and making predictions for the future, business intelligence is concerned with providing a snapshot of the current state of affairs.
Data engineering teams serve both of these groups, and they may even work with the same data set. Business intelligence, on the other hand, is concerned with assessing business performance and producing reports based on the information. These reports then assist management in making business decisions.
Business intelligence teams, like data scientists, rely on data engineers to create the tools that allow them to evaluate and report on data relevant to their area of expertise.
Machine learning engineering
Engineers that specialize in Machine Learning are another group with whom you’ll frequently interact. You could be doing comparable work to them, or you could be part of a team of Machine Learning Engineers.
Machine learning engineers, like data engineers, are primarily concerned with creating reusable software, and many have a background in computer science. They are, however, less concerned with developing applications and more concerned with developing machine learning models or developing novel algorithms for use in models.
Product teams frequently leverage the models that machine learning engineers create in customer-facing products. As a data engineer, the data you supply will be utilized to train their models, making your work essential to the capabilities of any machine learning team you work with.
Conclusion
In this article, you learned about the significance of Python for Data Engineering as well as the crucial role played by it. This article also highlighted the top 5 Python packages used in Data Engineering. You also explored various benefits and use cases. Overall, It is an important concept that plays a pivotal role in any organization.
So, as long as there is data to process, data engineers will be in demand. Dice Insights reported in 2019 that Data Engineering is a top trending job in the technology industry, beating out Computer Scientists, Web Designers, and Database Architects. Moreover, LinkedIn listed it as one of its jobs on the rise in 2021.
Share your experience of understanding in the comments section below!

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



