
About the Author Mona Rakibe is the co–founder, and CEO of Telmai, a low-code data reliability platform designed for open architecture, i.e., any batch/streaming source of your data pipeline. Mona is a veteran in data space, and before starting Telmai, she headed product management at Reltio, a cloud-based master data management company.
As we hurtle into a more connected and data-centric future, monitoring the health of our data pipelines and systems is becoming increasingly harder. These days we are managing more data and systems than ever before, and we are monitoring them at a higher scale.
While the opportunities for data capture and analysis have expanded, the complexity of tools and 3Vs of data (volume, velocity, and variety) have created a host of new challenges—lack of visibility into data health, bad data, and unexpected anomalies.
Today, there’s a critical need for understanding what’s inside the data – not just the quantity, but the quality. What percentage of this data is actually usable, consumable, and valuable?
– Mona Rakibe, CEO of Telmai
Anomaly detection is, at its essence, a method of finding data metrics that are inconsistent with the distribution of the majority of data metrics. While not all deviations are bad, they often act as early warning signals of imminent failures. Detecting anomalies isn’t a novel concept, but growing volumes of data to which most businesses are exposed make manual monitoring processes and frameworks almost impractical.
By using ML and statistical analysis for anomaly detection, data teams can proactively get informed and minimize downstream impact, thereby reducing operational costs and improving trust. With a growing focus on real-time analytics these days, the ability to identify, comprehend and diagnose outliers in advance is gaining paramount importance.
Ask most data experts, and they would agree that the costs of ignoring outliers can be upsettingly high and an even higher cost is of not knowing which datasets are usable and have passed high-quality checks.
Compromising on these insights can jeopardize your data initiatives by preventing:
- Data engineering teams from getting a complete picture of your application environment and services,
- Data science teams from training robust data science models for accurate predictions,
- Business teams from gaining holistic insights about customer sentiments and much more…
Hence it bears on us to understand—by proactively monitoring data health, your business can uncover more opportunities for optimization, acquire a more comprehensive grasp of its data, streamline its operations, and accelerate the time to bring data products to the market.
Table of Contents
Spotting the Unusual: Why Real time Anomaly Detection is Crucial Today
In a world where every second counts, real time anomaly detection is a saving grace for industries like finance, healthcare, retail, and cybersecurity.
In healthcare, for example, real-time anomaly detection can help medical professionals identify and respond to critical changes in patient health, potentially saving lives. For financial institutions, it can surface deviations like suspicious activities or fraudulent transactions, saving millions of dollars.
However, its usefulness doesn’t stop there.
If your business grapples with poor data quality and sinking trust, you must make real-time anomaly detection a top priority. Doing so is one of the most important steps you can take toward improving the quality and comprehensibility of your data. It will help you differentiate what’s “normal data” and what’s “not”, which in turn will improve your data-collection process.
For downstream business users, this translates to increased trust and better business outcomes. If your data teams can proactively identify and act on outliers—considering the context and underlying factors—your business functions can leverage their support in making smarter and agile choices for the overall benefit of the business.
It’s important to note that while outliers should not be disregarded, they should also not be given undue weight or importance. Your data teams must assess the effects—positive, negative, or otherwise—of including these anomalies.
Modernize Anomaly Detection by Breaking the Curse of Legacy
Scaling is the biggest challenge customers face when deploying an anomaly detection strategy, and traditional data stacks or homegrown systems don’t make the cut for it. The reason is pretty simple – they can’t scale rules or business use cases.
In the past, businesses largely dealt with linear and homogeneous data, which made rule-based monitoring and governance an effective approach for scanning data.
If you look today, the requirements have changed drastically. In reality, a large portion of your business processes are dynamic and ever-changing and stored in disparate systems with disparate formats as such, they require real-time ML-based monitoring strategies to receive accurate information about them at all times.
Band-aid solutions for data quality issues don’t work. Many engineers or data architects identify a problem, write rules or libraries, and deploy them without much forethought. But soon enough, they realize they’re stuck in an endless loop of adding more and more rules, leading to a management nightmare.
Without a well-planned user experience or streamlined techniques for adding or editing data quality rules and policies, it can quickly turn into a time-consuming and frustrating exercise. Augment this with unexpected costs on hosting/and running these services.
Amidst the myriad of tools in the data ecosystem, the demand for trustworthy data has surged. It’s challenging to discern the valuable data from the noise when so many pieces are in action.
– Mona Rakibe, CEO of Telmai
What businesses need today is a plug-and-play composable stack—a modern data stack (MDS) offering robustness, flexibility, and scalability for real-time anomaly detection. By integrating automated data replication, observability, and governance platforms, along with the power of ML and AI, MDS can create a holistic system of data, enabling organizations to detect, alert, localize, and address anomalies before they create havoc in other parts of the system.
An MDS excels at preventing your analytical system from becoming overloaded. With automation and configurable systems that can be customized for teams’ requirements, you no longer need to rely on everyone’s conduct to perform their own data quality checks.
Anomaly Detection Shouldn’t Just Be a Check Box – Quality Detection Is Key
Most data companies face two broad issues: known unknowns (predictable) and unknown unknowns (unpredictable). Known unknowns—like schema changes, or null values in your destination can be identified and resolved using data tests. In the face of unknown unknowns, like code changes in an ETL script/API, or data drift like value outliers, it is a much more challenging task.
The unknown unknowns will always be unpredictable. We need to accept that data will be unpredictable. And when it’s unpredictable, can we get enough insights to make sure we find the root cause quickly and react before there’s an impact? Such issues need advanced ML techniques.
– Mona Rakibe, CEO of Telmai
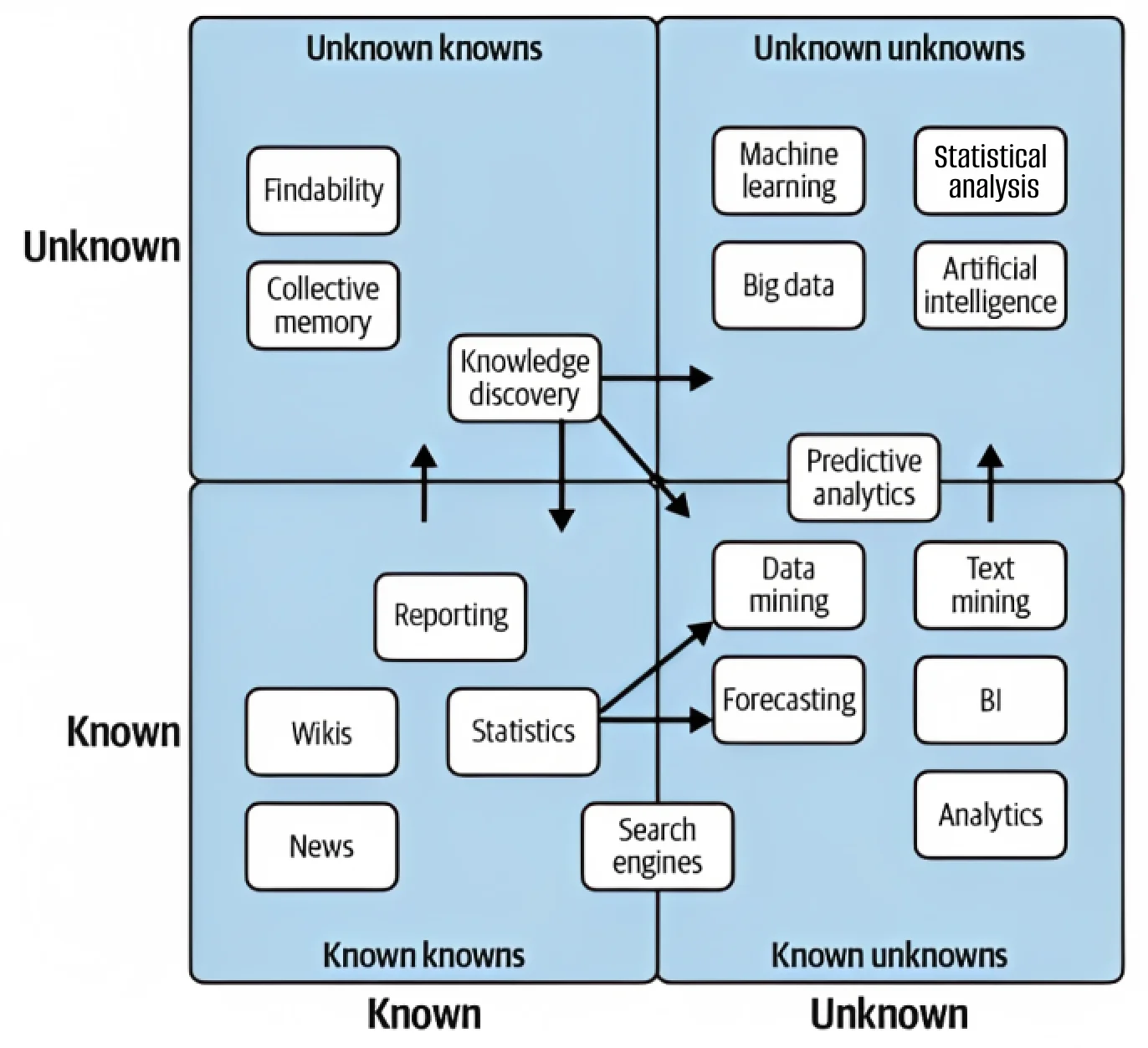
Modern-day observability platforms like Telmai monitor your data continuously the moment they are plugged in, learning everything about it. This includes metadata, attributes, and data quality metrics. The system usually uses a human loop to fine-tune its learning and train the model where data product owners or data ops teams can provide feedback.
As new data is received, the system compares it to what it already known and automatically calculates thresholds, including those based on ML for time series analysis. Users can customize thresholds for each attribute and even define new attributes based on aggregate functions. This allows teams to monitor outlier data in a highly customizable way.
In my opinion, the best approach to quality monitoring must begin at the source.
The farther the data travels from the source, the harder it is to find the root cause and remediate it.
– Mona Rakibe, CEO of Telmai
You must examine core validations such as completeness, correctness, and row counts, as well as the historical compliance of the source system. These validations should be checked as the data moves through the pipeline toward consumption. Keep an eye on KPIs for changes that may require alerts as the data moves through the pipeline. Depending on the pipeline stage, your monitoring requirements can vary.
Don’t Forget: A Peanut Butter Approach Could Backfire
In recent years, data observability has been showing some interesting trends. When it comes to ML-based data monitoring, where thresholds are automatically calculated, accuracy and adjustment are “the two most vital keys”. It is essential to segment calculations by certain attributes, such as schema attributes which could represent a region, business unit, or anything else.
I remember the other day when I was speaking to a data expert from VISA. In our discussion on time series analysis, he emphasized that accounting for fluctuations in transactions across regions is crucial to ensuring accuracy and adjusting for seasonality differences that differ greatly from region to region.
Data observability metrics and thresholds for North America should differ from those for Asia.
While this may not be a groundbreaking concept, segmentation by region serves as a vital metric for fine-tuning data quality metrics not only across the entire dataset or table but also at a more granular level based on specific attributes. With segmentation and precise adjustments, data observability platforms can deliver exceptional data quality insights to businesses.
If you are starting out or totally new to this, let me share a tip that will skyrocket your success: start with MVP. It’s the best way to gain traction quickly and make a splash. To maximize impact, focus on the datasets that matter most – the ones that fuel your reporting and machine learning efforts and hold the most sway with your business users.
Once you’ve honed in on these critical tables, it’s time to get monitoring. Within a matter of weeks, you’ll gain deep insights into the data, spotting any trash or deviations that could be harming your business.
As soon as you start demonstrating that value to your business, the investment gets justified, and you can start expanding on top of that. So, my recommendation would be to start small, use the right tools, and watch as your MVP grows into something truly remarkable.
Data Observability: What Lies Ahead
Data stacks oversee the well-being of our data through a set of multiple tools—quality, observability, and governance. Can there be an all-encompassing solution to monitoring data health? A single solution that includes a confluence of data quality, observability, and governance?
My foresight is no. Think of this situation as a library:
- Data governance sets policies and rules to dictate how books are acquired, stored, and used.
- Observability ensures books are present with proper labeling and categorization, and ensuring they are available to patrons.
- Data quality maintains certain standards of book quality and relevance to the library’s collection.
These three functions work together to ensure that a patron can access the books they need while maintaining the integrity of the library’s collection. Separate but synergistic.
Most people often mistakenly perceive data observability as a mere monitoring and notification system. However, its true power lies in the ability to operationalize your pipeline. Currently, most pipelines lack intelligence, making it challenging to leverage their full potential.
In the future, data observability is going to power everything related to data quality and pipeline orchestration. This includes metrics that automatically classify data quality and provide insights. I also feel that a new breed of data quality product managers will emerge as a result, which will play a crucial role in organizations that focus on KPIs and visibility in data quality. Up until now, that was like an underserved area, but I’m already starting to see a shift within companies, where roles with a keen eye for observability are blooming.
Despite these promising developments, we have barely scratched the surface of the possibilities that lie ahead. The truth is the success of many initiatives hinges on the robustness of our data observability.
As we look ahead to the future of modern data stacks, data observability will become a vital driving force. By embracing and maximizing the potential of data observability, we can create a world where data quality is paramount, leading to groundbreaking discoveries that can change
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link

