

Amazon Redshift is a petabyte-scale data warehouse, managing such mammoth disk space is no easy job. Unlike traditional databases which have limited disk space and performs housekeeping activity without user intervention, Redshift leaves it up to the user to perform its housekeeping activity so as not to hamper its performance. Ensuring the real-time availability of data should be one of the first things that you should work on to get the most out of your Redshift Data Warehouse. If you are dealing with a huge amount of data, then it will be an absolute necessity to guarantee accurate, consistent and latest data in the warehouse.
For the scope of this article, we will talk about Amazon Redshift Vacuum and Analyze and how they can help optimize Redshift Performance by improving Redshift space utilization.
Table of Contents
What is Redshift?

Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud, provided by Amazon Web Services (AWS). It allows you to run complex queries and analytics on massive datasets quickly, making it ideal for business intelligence, reporting, and data warehousing.
Key Features of Redshift
- Automated backups: Redshift automatically backs up your data to Amazon S3 (Simple Storage Service). You can configure backup retention periods, and it will retain snapshots for up to 35 days by default.
- Petabyte-scale data warehouse: Redshift can scale from a few hundred gigabytes to petabytes of data. You can easily resize clusters up or down as your data needs grow or shrink.
- Redshift uses a columnar storage format to store data, which drastically reduces the amount of I/O required to execute queries.
- Redshift employs Massively Parallel Processing (MPP) architecture, which distributes data and query execution across multiple nodes.
For further information check out Amazon Redshift.
Ditch the manual process of writing long commands to migrate your data and choose Hevo’s no-code platform to streamline your migration process to get analysis-ready data.
With Hevo:
- Transform your data for analysis with features like drag and drop and custom Python scripts.
- 150+ connectors like Redshift(including 60+ free sources).
- Eliminate the need for manual schema mapping with the auto-mapping feature.
Try Hevo and discover how companies like EdApp have chosen Hevo over tools like Stitch to “build faster and more granular in-app reporting for their customers.”
Get Started with Hevo for FreeWhy is Amazon Redshift Vacuum and Analyze Needed?
- Running the Analyze command updates the table’s statistics, helping the query optimizer make informed decisions.
- When data is deleted or updated in Redshift, the old versions of rows are marked as “deleted” but are not immediately removed from disk. These deleted rows take up storage space until a vacuum operation physically removes them.
- Vacuum re-sorts the data in the table, ensuring that sorted columns remain in order. This improves query performance by reducing the need for Redshift to scan large portions of the dataset unnecessarily.
How to Use Amazon Redshift Vaccum for High-Performance?
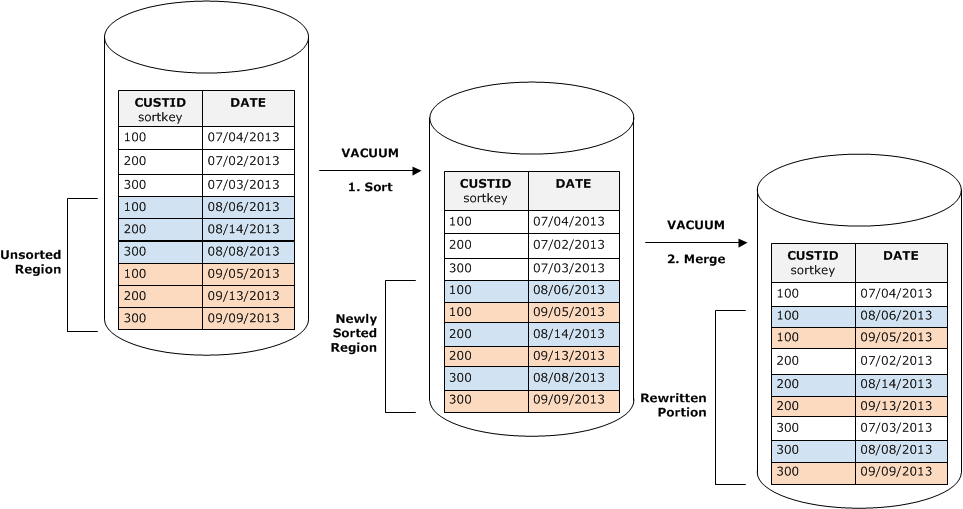
Privileges Required for VACUUM
Following are required privileges for VACUUM:
- Database owner whom the table is shared to
- Superuser
- Users with the VACUUM privilege
- Table owner
When data is inserted into Redshift, it is not sorted and is written on an unsorted block. With unsorted data on disk, query performance might be degraded for operations that rely on sorted data, such as range-restricted scans or merge joins. When you run a DELETE query, redshift soft deletes the data. Similar is the case when you are performing UPDATE, Redshift performs a DELETE followed by an INSERT in the background. When vacuum command is issued it physically deletes the data which was soft-deleted and sorts the data again.
Among other things, you might want to focus on Amazon Redshift Sort Keys and Amazon Redshift Distribution keys to optimize the query performance on Redshift.
When to Use Amazon Redshift Vaccum?
Although VACUUM improves query performance it comes at a cost of time and hits performance during its execution. It is recommended to perform Redshift Vacuum and Analyze depending on the amount of space that needs to be reclaimed and also upon unsorted data. To figure out which tables require vacuuming we can run the following query.
SELECT "schema" + '.' + "table" FROM svv_table_info where unsorted > 10The query above will return all the tables which have unsorted data of above 10%.
Figuring out tables which have soft deleted rows is not straightforward, as Redshift Vacuum and Analyze does not provide this information directly. What it provides is the number of total rows in a table including ones that are marked for deletion(tbl_rows column in the svv_table_info table). To get an actual number of rows (excluding ones which are marked for deletion) you will simply have to run a count query on the table and figure out the number of rows which have been marked for deletion. For example, let’s consider a hypothetical table ‘users’ in ‘public’ schema. we have to calculate soft deleted rows in the users table.
SELECT tbl_rows - (SELECT count(*) FROM public.users)
FROM svv_table_info
WHERE "schema" = 'public' AND "table" = 'users';How to Run Amazon Redshift Vaccum?
You can issue vacuum either on a table or on the complete database.
There are following 4 options available:
- VACUUM DELETE ONLY: A
DELETE ONLYvacuum reclaims disk space and do not sort new rows. For example, you might perform aDELETE ONLYvacuum operation if you don’t need to resort rows to optimize query performance. - VACUUM SORT ONLY: A
SORT ONLYvacuum do not reclaim disk space it just sort new rows in the table. - VACUUM FULL: It is a combination of
DELETE ONLYandSORT ONLYvacuum. As the operation is handled internally by Redshift it is better to runVACUUM FULLrather than manually runningDELETE ONLYfollowed bySORT ONLYvacuum.VACUUM FULLis the same asVACUUMmeaningVACUUM FULLis the default vacuum operation. - VACUUM REINDEX: Use this for tables that use interleaved sort keys. When you initially load an empty interleaved table using
COPYorCREATE TABLE AS, Redshift automatically builds the interleaved index. If you initially load an interleaved table usingINSERT, you need to runVACUUM REINDEXafterwards to initialize the interleaved index.
To perform vacuum use the query below

E.g VACUUM FULL users;
This completes the first section of Amazon Redshift Vacuum and Analyze tutorial on when and how you can leverage Amazon Redshift Vacuum.
How to Use Amazon Redshift Analyze for High Performance?
When a query is issued on Redshift, it breaks it into small steps, which includes the scanning of data blocks. To minimize the amount of data scanned, Redshift relies on stats provided by tables. Stats are outdated when new data is inserted in tables. ANALYZE is used to update stats of a table.
Although when there is a small change in the data in the table(i.e. When new rows are added in the table) it may not have a huge impact when there is a major change in stats, redshift starts to scan more data. So as to make the right query execution plan, Redshift Vacuum and Analyze requires knowing the stats about tables involved. Stats for table changes when new data is inserted or deleted.
When to Use Amazon Redshift Analyze?
Similar to Redshift Vacuum, analyze too is a time-consuming operation. To get all the tables which need to have its stats updated you can run the query below.
SELECT "schema" + '.' + "table" FROM svv_table_info where stats_off > 10This Redshift Vacuum and Analyze query will return all the tables whose stats are off by 10%.
How to Run Amazon Redshift Analyze?
You can run the Amazon Redshift Vacuum and Analyze command using the following syntax:

E.g. ANALYZE VERBOSE users;
Another way to improve the performance of Redshift is by re-structuring the data from OLTP to OLAP. You can create derived tables by pre-aggregating and joining the data for faster query performance. Solutions such as Hevo Data Integration Platform offer Data Modelling and Workflow Capability to achieve this in a simple and reliable manner. You can use Hevo for 14-day Free Trial.
Apart from this guide on Amazon Redshift Vacuum and Analyze, we have also discussed the right way to choose distribution keys and sort keys. Also, as part of our Amazon Redshift blog series, you can read a detailed account where we have gone deep into understanding Amazon Redshift architecture.
This completes the second section of the Amazon Redshift Vacuum and Analyze tutorial on when and how you can leverage Amazon Redshift Vacuum.


What are a Few Things You Need to Keep in Mind While Using VACUUM Command?
- You can’t run VACUUM within a transaction block (BEGIN … END). For more information about transactions, see Serializable isolation.
- You can run only one VACUUM command on a cluster at any given time. If you attempt to run multiple vacuum operations concurrently, Amazon Redshift returns an error.
- Vacuum operations are skipped when there is no work to do for a particular table; however, there is some overhead associated with discovering that the operation can be skipped.
- Any data that is written after a vacuum operation has been started can’t be vacuumed by that operation. In this case, a second vacuum operation is necessary.
- Automatic vacuum operations pause if any of the following conditions are met:
- A user runs a data definition language (DDL) operation, such as ALTER TABLE, that requires an exclusive lock on a table that automatic vacuum is currently working on.
- A user triggers VACUUM on any table in the cluster (only one VACUUM can run at a time).
- A period of high cluster load.
Conclusion
This article teaches you about the Amazon Redshift Vacuum and Analyze. It provides in-depth knowledge about the concepts associated with it to help you implement them and improve your query and data performance. Integrating complex data from numerous sources into a destination of your choice such as Amazon Redshift can be challenging especially for a beginner & this is where Hevo saves the day.
Hevo Data, a No-code Data Pipeline, helps you transfer data from a source of your choice in a fully automated and secure manner without having to write the code repeatedly.
Sign up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
FAQs
1. What is the difference between VACUUM and ANALYZE?
VACUUM in Redshift reclaims disk space and re-sorts data on the disk for optimized query performance.
ANALYZE updates the statistics metadata for query planners to improve query execution efficiency.
2. What does a VACUUM do in Redshift?
VACUUM reorganizes the table by removing deleted rows and re-sorting the data, improving storage efficiency and query performance.
3. Does Redshift automatically VACUUM?
No, Redshift does not automatically VACUUM. You need to manually run it or schedule it to maintain table performance, though auto-vacuum is available for Amazon Redshift RA3 nodes to manage some vacuum tasks automatically.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




