Many businesses are turning to data warehousing as data use expands to consolidate data for analytics, reporting, governance, and decision making. Modern warehouse systems are more adaptable, quicker, scalable, and cost-effective than ever before. However, data warehousing is not without its difficulties.
ETL and ELT enable you to extract data from various sources (such as Salesforce Customer Data) and push it into a data warehouse. ETL/ELT integration procedures simplify importing data into your data warehouse and preparing it for external consumption.
Consider a scenario where your company is an automobile manufacturer and wants to reward its customers with a gift card worth up to $10,000 to those customers who purchased a car worth more than $100,000 in the previous month. To send these personalized gift cards, you need data about your customers, their transactions, and repeat purchases from different platforms like Marketo, Google Ads, SendGrid, etc. This data needs to be ingested into your warehouse by using ETL pipelines, to be able to further analyze it.
Usually, after a traditional ETL workflow, analytical data is taken on spreadsheets and shared among teams to work on it manually — record by record or, sometimes, this data is pushed through API connectors from the data warehouse to SaaS applications and CRMs. Both these processes are cumbersome, time-consuming, and prone to errors.
When faced with such scenarios, reverse ETL can be a lifesaver, allowing you to send transformed data from the data warehouse to a platform such as Salesforce, keeping Salesforce customer data in sync with multiple sources. Once your data reaches Salesforce, you can now automatically send the offer to your targeted group of people.
Reverse ETL has been developed as a critical component of today’s modern data stack that helps get data from your warehouse to the right platform so that your teams can act on that data (fast) and create a seamless data-driven customer experience.
Table of Contents
Every Business Needs Multiple SaaS Applications
According to a report by Okta, larger enterprises use an average of 175 applications, with smaller organizations deploying as many as 73 applications on average.
Companies need these applications because every application is optimized to serve a specific business function in the best way possible. Marketing teams use CRMs like HubSpot to manage the company’s relationships with customers and potential customers, Online Advertising Tools like Google Keyword Planner, Google Ads to promote their products and services, and Social Media Tools like Buffer to manage their social media channels.
In a similar way, sales teams use CRMs like Monday to integrate emails and automate processes, and Account-based Marketing (ABM) Tools like Outreach to manage outreach and follow-ups. Customer success teams also have their own set of tools.
For most businesses, customer relationship management, leads tracking, funnel management, email, analysis, advertising, and other functions have grown reliant on these apps. However, if these applications expand, they may quickly become walled gardens, aka data silos, resulting in massive fragmentation of the business and customer information.
Add to it the fact that the data generated by these apps is mostly unstructured. Many organizations’ primary difficulty today is converting fragmented, unstructured data acquired from customers into meaningful information. All this creates data silos.
Let’s look at the reasons why data silos are bad for your organization:
- Incomplete Data Sets: Data silos isolate data from people who cannot access it. As a result, company plans and judgments are not based on all available facts, resulting in poor decision-making. Silos can also hamper efforts to construct data warehouses and data lakes that connect disparate data sources for gaining holistic customer insights, business intelligence (BI), and analytics.
- Data Inconsistency: Many data silos are inconsistent with one another. A marketing team, for example, may style customer data differently than other departments. Data inaccuracies made by a sales team may go undetected and uncorrected. Data changes in other systems are not made in an isolated customer service system. Such anomalies cause data quality, accuracy, and integrity problems, affecting end-users in both operational and analytical applications.
- Poor Data Collaboration: Isolated data sets in silos limit prospects for data exchange and cooperation among users across departments. It is more challenging to collaborate successfully when people do not have access to segregated data.
- Data Security Issues: Some individual users keep data in Excel spreadsheets or online business platforms like Google Drive, typically on mobile devices. Organizations face increased data security and privacy concerns if appropriate measures are not in place. Silos also complicate efforts to comply with data privacy and protection laws.
Salesforce Customer Data Sync Builds 360-Degree Customer Views
SaaS applications like Salesforce have their own data analytics capabilities that can enhance your data warehouse’s BI and analytics workloads. Giving Salesforce access to your entire organization data set can help in finding hidden patterns, insights, and connections that it would not have been able to identify with CRM data alone.
You may, for example, utilize this new information to build a 360-degree view of your customers and prospects, supplementing each customer profile and making the image as complete as possible.
By providing a 360-degree view of your customers, you ensure all your customer’s data is available in a single location that is accessible to all the departments. With this data, your data and business teams can build a relationship that is experiential rather than transactional – make more personalized decisions that improve the overall customer’s experience.
Moreover, sending your data back to Salesforce and performing Salesforce customer data sync can leverage your marketing, sales, and customer support teams with the following capabilities:
Automation
Salesforce has surpassed its competitors to become the most popular CRM in the world. More individuals are using Salesforce thanks to the system’s customization to your specific process requirements.
Salesforce’s automation capabilities can reduce tedious activities, giving administrators more time to focus on essential responsibilities. It automates routine processes like developing records based on lead acquisition, delivering planned or prompted communications, creating approval workflows, etc.
For example, using Salesforce customer data sync, the marketing team might build automation that when a reader clicks on a CTA on the newsletter (email), their details can be sent to the sales team for further enrichment.
Easier Access for End Users
Salesforce has a flexible, adaptable data-sharing architecture that enables admins to manage user access to data. By only exposing data pertinent to users, managing data access improves security.
Different teams use different applications to get the most out of the data, and non-tech people find it challenging to use data from such discrete systems. Since these applications require teams to have programming knowledge or technical nuances that only tech people are familiar with.
Salesforce customer data sync gives users an easy-to-use interface to users and allows these non-tech folks to utilize the same familiar functionality of Salesforce CRM.
Why is Centralizing Data the First Step to Keep Salesforce Customer Data in Sync?
Application integration allows your apps to communicate with one another by exchanging data and calling services.
In a traditional business arrangement, apps operate independently of one another within distinct business units or activities, and they do not interchange data. This is problematic since these applications are frequently utilized to conduct business activity or to assist you in better understanding how your customers are responding or how your firm is operating.
In these circumstances, people must manually write code to integrate different applications and enable data transfer between them, which consumes time and is prone to mistakes.
Challenges of Application Integration
Businesses utilize a lot of apps due to the emergence of creative business software applications such as marketing, HR, messaging and collaboration, accounting and finance, and project management tools.
These apps are frequently vital for employees to assist the firm in achieving its goals and giving superior service to its consumers; hence, businesses need application integration to create 360-degree customer profiles, gain a comprehensive understanding and use these customer insights to boost their top line.
The more cloud and on-premise apps that are added, the more complicated the primary business integration data flow might become. These pieced-together applications risk causing havoc since they are not properly linked inside the IT environment. However, because there are so many different solutions to integrate, including cloud apps and services, businesses are sometimes stymied in their search for a dependable solution that allows agile deployment and integration of best-of-breed enterprise application technologies.
Companies who do not have the correct integration platform will drown in a custom-coded, unscalable, and difficult-to-manage application environment. Here are the challenges that companies face in application integration:
- Siloed Applications: Applications set up independently and outside of an enterprise’s core keep employees getting insights from it. These data “stovepipes” frequently occur when your IT infrastructure cannot support integration for SaaS solutions and other cloud-based services.
- Integration is Time Consuming: One-time integrations lengthen the time it takes to onboard and consume an application, necessitating specific skill sets to maintain these integrations. Furthermore, custom-built connectors can cause transaction mistakes, restrict data flows, and stymie partner relationships and organization progress.
- No Process Automation: Without proper data transformation and mapping capabilities, organizations cannot accept and route partner data efficiently, and the application works outside the automated data orchestration process. This prevents firms from having real-time data visibility, which prevents them to respond to consumer and partner requests more quickly.
Why Should You Centralize Your Data?
Many organizations have silos of data, ranging from internal systems and digital platforms to third-party data providers. For example, a company’s Google Ads data may be in their Google account, but consumer click data may reside in another vendor’s platform.
According to a study by Gartner, by the year 2026, 50 percent of companies using numerous SaaS services will use a SaaS management platform (SMP) to centralize administration and consumption information.
When you centralize your data, you take it out of its various silos and store it in a way that allows your whole business to access it. To acquire a 360-degree perspective of your organization and consumers, data centralization is required. Without a consolidated data collection, you can’t connect marketing data to sales and sales to clients. Data from all consumer contact points and business processes must automatically and dependably flow into a single place for deep, comprehensive analysis for your firm to move swiftly.
Today, most companies are using a data warehouse to centralize their data. According to a report by Yellowbrick, the global data warehouse market will cross the $30 billion mark by 2025.
Here are some of the reasons why centralizing data is the first step to keeping Salesforce customer data in sync:
Enhances Data Consistency
Teams may be on the same page for consistency and quality control with consolidated data, resulting in a better customer experience and excellent business consequences. This consistency adds value to an organization in the following ways:
- Teams are more able to meet and exceed the high expectations of customers.
- Centralized data facilitates better transparency within any company.
- Reporting and analytics are more consistent and straightforward.
Optimizes Data Assets
Thanks to centralized data, the team can focus on continuous development while prioritizing assets that affect its growth and performance. A consolidated data platform makes more significant optimization possible since it:
- Encourages ongoing improvements in decision-making processes.
- Improves business process tracking and optimization.
- Reduces an organization’s risk while avoiding the negative consequences of errors and redundancy.
Data Security
Detecting and safeguarding data exchanges is difficult when data management is segregated. Here’s how a consolidated data platform may help with security:
- Data access may be readily monitored and controlled by organizations.
- Data access methods and processes may be developed using centralized data.
- The organization can reduce the danger of secure data mistreatment.
Enhanced Focus on Data
Because the data is centralized, the team spends less time cleaning or preparing it and more time focused on its critical development and success. Consider the following top ways a consolidated data platform leads to increased focus:
- The use of centralized data simplifies the training needs.
- Employees are taught a single enterprise data model.
- It promotes cross-organizational collaboration and awareness of roles and responsibilities.
Saves Time and Cost
With fewer staffing needs and simplified procedures, centralized data is more efficient and cost-effective. Consider the time and money savings:
- Data processing and reporting are faster, allowing for more rapid data visualization possibilities.
- Teams can strategize, plan, and execute strategic projects more effectively.
Sync Data from Warehouse to Salesforce Using Reverse ETL
What is Reverse ETL?
Now that enterprises have a centralized source of truth, it’s time to communicate the acquired data to other frontline apps such as CRM, e-commerce, and cloud services. Sales, marketing, production, support, and analytics teams rely on consistent and trustworthy data, and they prefer to access it through their preferred applications. Reverse ETL allows you to send the consolidated data from a data warehouse to frontline applications like Salesforce, Zendesk, Marketo, etc.
For example, your company is an OTT platform offering essential features to non-subscribed users. Your sales team is, let’s say, using Salesforce as a CRM platform. Tracking freemium accounts and looking for methods to convert them to premium customers is one of the things they do manually. Your account managers will need to switch back and forth between BI and CRM applications to see where these users are in the sales funnel.
What a reverse ETL can do is it can send this data from the data warehouse to Salesforce and allow the sales team to target the customers when they clear certain criteria, let’s say the criteria is of using their platform for 20 hours or 10 times they have clicked on paid videos, etc.
How Does Reverse ETL Help in Operationalizing Data?
Most firms have jumped onto BI platforms by using Looker, Power BI, Mode, Superset, or one of the many other tools available today. BI provides insights in ready-to-use dashboards to engage the less involved, and it enables many team members to generate visualizations with little or no coding.
However, dashboard visualizations are only as valuable as the activities they allow when people look at them. As a result, human consumption of the BI tool restricts automation, which is where reverse ETL comes in.
Reverse ETL makes data operational by equipping data-driven business stakeholders with the tools they need to automate as many operations as possible, effectively releasing data insights from the limits of dashboards.
How Mixpanel Uses Reverse ETL for Product-Led Growth

Mixpanel is a business analytics service company that monitors users’ interactions with web and mobile applications and provides tools for targeted communication with them. Their product analytics technology helps businesses to engage and retain people by analyzing product patterns and behaviors. Their primary challenge was that their product usage data was not reaching the commercial teams who required it.
By using the reverse ETL platform, Mixpanel was able to break down the data silos and achieved the following:
- The Sales team was able to identify suitable clients from sign-ups and create relationships early.
- They discovered the worth of their user sign-up flow.
- They found new applications for the data they had already gathered.
How Reverse ETL to Salesforce Makes Your Teams More Effective?
Reverse ETL in Sales
A Product-Led Growth (PLG) sales team may use reverse ETL to sync relevant and useful data into a CRM like Salesforce to identify highly engaged leads. Here’s a business case study to demonstrate how reverse ETL has helped boost sales for Zeplin.
How Zeplin Improves Sales Productivity with Reverse ETL

Zeplin is a well-organized workspace for teams to collaborate and ship attractive products. The challenge Zeplin faced was a lack of visibility into how their leads interacted with the product.
Using reverse ETL, their sales team has become more effective at prioritizing and closing sales when they have access to crucial product data within Salesforce. This data-driven sales methodology has assisted Zeplin in meeting its sales target and expanding into the enterprise segment.
Reverse ETL in Marketing
Marketers may employ reverse ETL technologies to gain direct access to a real-time consumer profile for segmentation, analytics, and activation via a user-friendly interface. Because segmentations and messages can be refreshed in near real-time, operational latencies are reduced, and customer experiences are improved.
How LogDNA Improves Customer Experience with Reverse ETL

LogDNA is a log management solution that allows DevOps teams to aggregate their system and application logs onto a single platform. Within the sales team at LogDNA, they were facing a problem – they were unable to log information properly into Salesforce.
They were not able to answer simple questions like ‘How many clients are paying them?’, ‘How many individuals registered for a trial last week?’ ‘How many of those folks converted?’ Simply put, LogDNA didn’t have answers to these questions while making crucial business decisions.
Using reverse ETL, LogDNA’s sales team could leverage Salesforce reports and discover which clients were expanding and who their heavy users were. With this framework, they could introduce product scoring to assist them in organizing and prioritizing accounts that may be high-priority in the long run.
Putting Data to Work in Salesforce With Real-time Sync Using Hevo Activate

Hevo Activate is a data automation software that allows you to connect raw data from your data warehouse with your Target CRM program. The data warehouse tables may contain data imported from several sources, such as SaaS apps like Facebook and LinkedIn, database sources like MySQL, and webhook sources like SendGrid.
You may use Hevo Activate to create sophisticated SQL queries that will provide a unified view of this fragmented data and modify it for usage by your CRM application.
With Hevo Activate, you can get keep your Salesforce customer data in sync in just three steps:
- Step 1: Configure Your Data Warehouse
- Step 2: Configure Salesforce as a Target
- Step 3: Mapping Fields in Salesforce
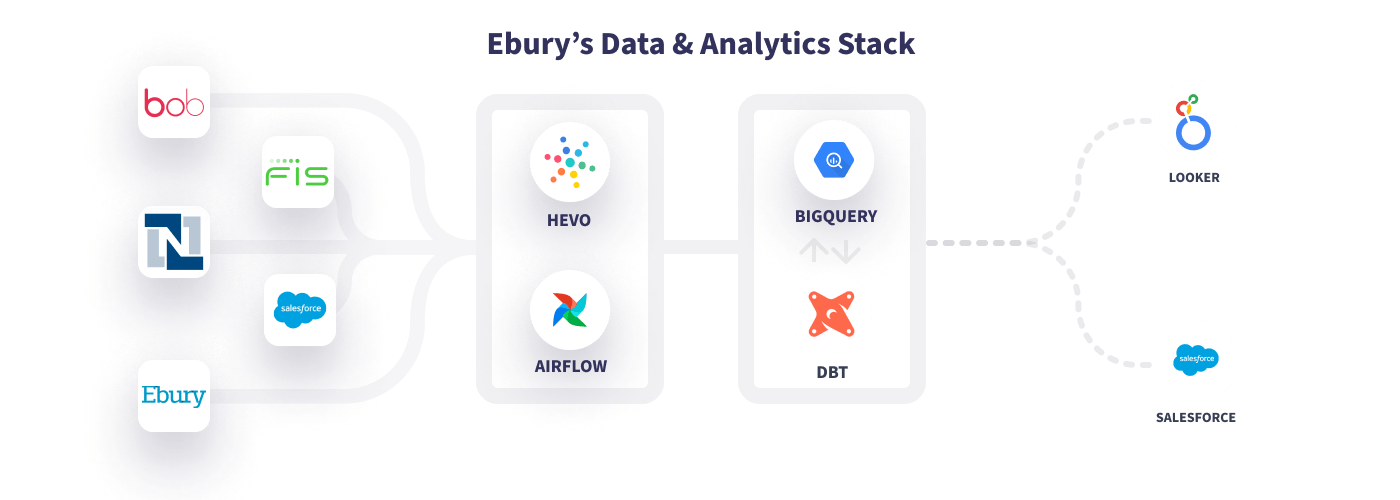
How Ebury Builds Reliable Data Products Using Hevo Activate

Ebury is a global fintech firm that uses modern data technologies to improve and automate financial services and processes for small and medium-sized enterprises (SMEs) that trade and transact globally.
Ebury helps such companies in removing transactional barriers associated with more traditional methods. Ebury’s entire business verticals, from sales to core platform products, rely on data to perform well. It must also comply with the regulatory regulations of numerous geographies since it operates worldwide and processes financial data from approximately 49,000 firms across the globe.
Using Hevo Activate, Ebury achieved near real-time data replication by sending insights from Looker to Salesforce with automatic schema detection and 100 percent data accuracy. Not only this, but Hevo Activate has also contributed to boosting team collaboration and improving data reliability.
“With Hevo, our data is more reliable than before. Hevo allows us to build complex pipelines with ease and after factoring in the excellent customer service and reverse ETL functionality, it is undoubtedly the best solution available in the market.”
– Juan Ramos, Analytics Engineer, Ebury
How to Create an End-to-End Data Analytics Platform with Hevo?
Data and business teams have used ETL/ELT to feed data into their systems for years. They would begin by gathering data from multiple third-party systems, cleaning it up, and placing it into data warehouses like Google BigQuery, Amazon Redshift, Snowflake, etc. In the majority of businesses, such teams are known to dump raw data into their systems and then somehow deal with it.
With the use of ELT (Extract, Load, Transform), companies would enter raw data into a data warehouse, and perform the data transformation later for a specific use case to reap the benefits of the data warehouse.
There remains a last-mile gap between the warehouse and frontline tools. Reverse ETL is the last mile of your contemporary data stack, allowing you to transition from your current data reality to your data dreams of leveraging near real-time data.
Reverse ETL allows you to make data actionable by syncing data from data warehouses to third-party apps like Salesforce, HubSpot, Google Ads, Facebook Ads, and others. Businesses may utilize Reverse ETL to retrieve data in near real-time and use it to inform about day-to-day operations. By utilizing both ETL and Reverse ETL, you can create an end-to-end analytics platform for your organization.
Today most companies consider ETL and reverse ETL as two distinct platforms. However, both offer data pipelines in which source and destination are reversed, which can be considered the “opposite side of the same coin.” However, today’s demand is to use both facilities simultaneously to make the best use of data for the company.

To achieve end-to-end analytics in your organization, you don’t require multiple platforms for ETL/ELT and Reverse ETL needs. It can be achieved using a bi-directional data pipeline platform such as Hevo Data. With Hevo, you can extract your data from multiple sources into the data warehouse of your choice. Once insights are drawn from that data, you can operationalize those insights by sending them back to your application using Hevo Activate.
Final Thoughts
While Reverse ETL appears to be a new method, it is only an extension of the classic ETL pipeline and its replacement, ELT. Reverse ETL arose organically from the need to transform massive amounts of data into daily actionable insights.
While ETL aids in the creation of a single source of truth (data warehouse) for the organizations, Reverse ETL sends data warehouse insights to downstream applications to improve customer experience through real-time analytics. For example, sending your customer’s data from the data warehouse to Salesforce will help you in customizing your marketing efforts, targeting your leads, etc. which you would not have been able to identify with CRM data alone.
Although reverse ETL is still in its early adoption phases for many, it is a good hint of many things to come. The current data stack’s key benefit is its agility. An organization can only adopt solutions that give the most immediate benefit, then add to the data stack as requirements and resources evolve. Consequently, the solution will be effective, efficient, and responsive.
While the new data tech stack has many advantages, it also has several gaps. And while the environment is continually changing, the modern data stack lacks completely developed modules for data quality, cataloging, or governance.
One of these holes is being filled by reverse ETL, which closes the loop between business applications and the data warehouse. New technology, methods, and products will continue to emerge throughout time to narrow more of those gaps.
Businesses can use automated platforms like Hevo Data to set the integration and handle the ETL process. It helps you directly transfer data from Salesforce for free to a Data Warehouse, Business Intelligence tools, or any other desired destination in a fully automated and secure manner without having to write any code and will provide you with a hassle-free experience. Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
Frequently Asked Questions
1. Does Salesforce have access to customer data?
Salesforce stores customer data, but only the account owner and authorized users can access it. Salesforce itself doesn’t use your data.
2. What is the difference between Salesforce CRM and CDP?
Salesforce CRM focuses on managing customer interactions, while Salesforce CDP unifies data from multiple sources to create a comprehensive customer profile.
3. How do I export customer data from Salesforce?
You can export customer data using Salesforce’s Data Export tool or by creating reports and saving them in formats like CSV or Excel.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link