




 Key takeaways
Key takeawaysSlowly Changing Dimensions (SCDs) help you keep your data warehouse accurate by tracking changes in evolving data like customer addresses, product details, or employee roles. Choosing the right SCD type—from retaining originals to combining approaches—lets you balance historical tracking with performance and storage efficiency.
By capturing data history smartly, SCDs empower better insights, helping your team make decisions based on reliable, time-aware information. Whether you’re analyzing sales trends, customer behavior, or inventory changes, these dimensions ensure nothing gets lost in the shuffle.
Start planning SCDs early in your database design or audit existing data to implement the right type. This way, you can preserve history, optimize queries, and keep your analytics fast, flexible, and future-proof.
In modern data analytics, organizations utilize data warehouses to store vast amounts of historical data, ensuring data analysts can easily access critical information. The historical data is vital for deriving actionable insights and driving effective decision-making. However, while most attributes or dimensions of data in a warehouse remain static, certain dimensions like customer addresses, product specifications, or employee designations evolve over time.
The evolving dimensions are also known as slowly changing dimensions (SCDs) in data science along with change data capture(CDC). SCDs help businesses retain their original records while also tracking changes over time. As a result, SCDs maintain the integrity of data warehouses and ensure that the insights derived from the stored data take into account the data’s slowly evolving nature. Let’s first understand what dimensions and measures are in data science.
Table of Contents
Dimensions and Measures in Data Science
In data science, dimensions and measures are significant elements of data analysis.
Dimensions comprise qualitative values, such as names, dates, or geographical data. You can use dimensions to categorize, segment, and reveal essential details in your data. For instance, sales data can include different dimensions, such as Region, Product Type, or Time Period. The dimensions affect the level of detail in examining the data.
On the other hand, measures are the numeric or quantitative values you can measure. These metrics, within the scope of the dimensions, can be evaluated, compared, or aggregated for data analysis. For example, with sales data, some associated measures include Total Sales, Profit Margin, or Number of Units Sold.
Use Hevo’s no-code data pipeline platform to effortlessly integrate your data in just a few clicks. You can extract and load data from more than 150+ different sources directly to your data warehouse.
Why choose Hevo?
- Provides real-time sync for better insights.
- Get 24/7 live chat support.
- Provides an automapping feature to automatically map your schema.
Experience why Ebury chose Hevo over Stitch and Fivetran to build complex pipelines with ease and after factoring in the excellent customer service and reverse ETL functionality. Try a 14-day free trial to experience hassle-free data integration.
Get Started with Hevo for FreeWhat are Slowly Changing Dimensions in Data Science?

Slowly changing dimensions in data science refers to a data warehousing concept. SCDs are dimensions that change over time but at a slow pace. These dimensions typically store and manage both historical and current data in a data warehouse.
A slowly changing dimension (SCD) is a method used in data warehouses to handle and update information that evolves over time. SCDs play a crucial role in data analytics by preserving the history of record changes. Unlike rapidly changing dimensions such as customer ID, product ID, quantity, or price—which update frequently—SCDs contain relatively stable data that may change occasionally and unpredictably. Common examples include geographic locations, customer details, and product attributes.
SCDs are considered critical in tracking the history of dimension records. These dimensions are important for tracking changes, especially attributes that change infrequently or slowly over time but not at predictable intervals.
Slowly changing dimensions in data science are important for tracking changes in data over time for accurate analysis. Data practitioners can use SCDs for employee performance analysis, sales analysis, and inventory management.
Differences Between Slowly Changing Dimensions (SCD) and Rapidly Changing Dimensions (RCD)
| Aspect | Slowly Changing Dimensions (SCD) | Rapidly Changing Dimensions (RCD) |
| Definition | Data changes slowly and infrequently over time. | Data changes quickly and frequently within a short period. |
| Examples | Customer address, employee designation. | Product stock levels, real-time user activity. |
| Change Frequency | Low: Changes happen occasionally. | High: Changes happen frequently and continuously. |
| Storage Requirements | Requires less storage as changes are less frequent. | May need more storage to handle frequent updates. |
| Implementation Complexity | Easier to manage with simpler ETL processes. | More complex due to high frequency of updates. |
| Impact on Performance | Minimal impact on database performance. | Can significantly affect performance if not optimized. |
Types of SCD with Examples
There are five types of slowly changing dimensions in data science.
- Type 0: Retain Original – Attributes that do not change and always retain the original value without tracking history, such as zip codes.
- Type 1: Overwrite – Old data is replaced with new data without retaining historical records, commonly seen in customer address updates.
- Type 2: Add New Row – A new record is added for each change, preserving history in the table, like customer address changes with timestamps.
- Type 3: Add New Attribute – Stores the current and one previous value in columns, useful for product pricing tracking current and prior prices.
- Type 4: Add History Table – Current data stays in the main table, while a separate history table holds past data, such as product price changes.
- Type 6: Combined Approach – It is called Type 6 because it is a hybrid of Types 1, 2, and 3, where columns hold current and historical data, and a version column tracks changes, like employee role and department updates.
Now, let’s dive into each type in more detail to understand their characteristics and use cases.
Type 0: Retain Original
Type 0, also known as Retain Original type, refers to dimensions or attributes that never change and will not be updated in the data warehouse. The original dimension value is always retained, and no tracking of historical data takes place. Type 0 is applicable to most date dimension attributes.
Examples of SCD Type 0 include:
- States
- Zipcodes
- Social security number
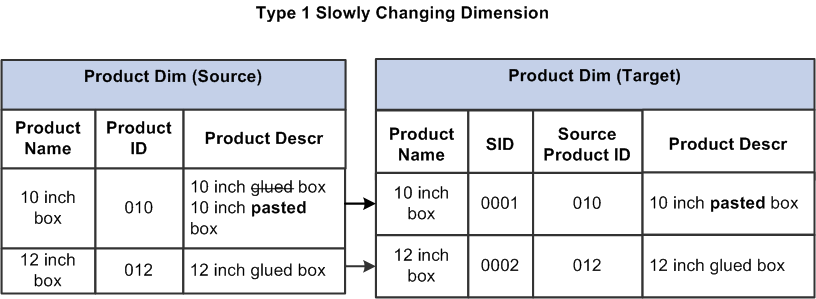
Type 1: Overwrite
Type 1, or Overwrite type, refers to an instance where old data is overwritten with new data. The old data is lost as it is not stored anywhere, and the latest snapshot of a record is maintained in the data warehouse without any historical records. With this SCD type, you cannot keep track of changes over time.
The benefits of SCD Type 1 include requiring less storage space and being easy to maintain. However, the disadvantage of the Type 1 method is that historical data is lost. Also, it doesn’t support the analysis and reporting of historical data.
This type is commonly used to correct errors in a dimension, updating irrelevant or wrong values. No history is retained.
Here are some SCD Type 1 examples:
- Customer address data: The old address is replaced with the new address, and the history of the old address is not required.
- Inventory data: When an item’s stock is updated, the new stock level replaces the old stock level.
- Employee salary data: When an employee’s salary is updated, the new salary replaces the old salary, and the history of the old salary is not maintained.
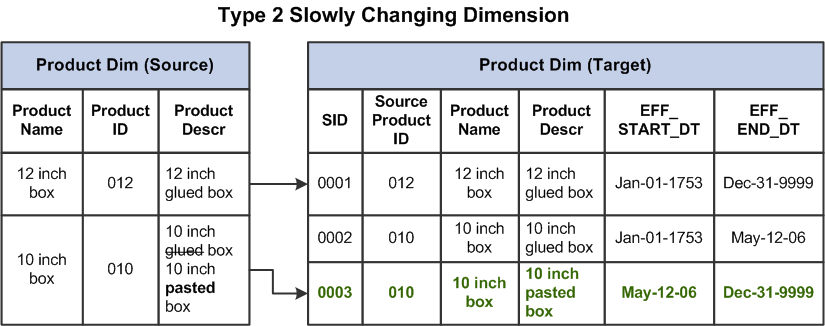
Type 2: Historical Tracking Method
SCD Type 2, also known as the historical tracking method, enables tracking changes in dimension data over time by adding a new row for each change. Each record in the table has a unique identifier, and historical data is preserved.
Every time the source system changes, a new row with a unique identifier is added to the dimension table. The resulting table retains the prior history, allowing full history tracking.
How it works:
When an attribute in the source system changes, a new record with a unique identifier is added to the dimension table. The old record is retained with an “inactive” status, and the new record is assigned as “active” with a fresh timestamp or version number.
There are two main ways to manage SCD Type 2:
- Timestamp Columns: Timestamps or version numbers are used to mark when records were created or made inactive, keeping a historical log.
- Flag Column: A flag column (e.g., 0/1 or Y/N) indicates which record is currently active.
Benefits:
- Audit trail: Provides an audit trail for data changes, supporting effective reporting.
- Historical data retention: Full history is preserved, allowing accurate analysis based on different time points.
Challenges:
- Complexity: Implementing SCD Type 2 can be complex, requiring careful planning around data structure changes and storage.
- Storage management: As more records are added, the table can grow large, impacting performance and manageability.
Examples of SCD Type 2
- Sales data: You can track your sales of a particular item or profit over time to help you analyze your sales.
- Customer or order data: You can keep track of previous orders of a person and recommend items based on that.
- Customer address: When a customer relocates, a new address entry with a new timestamp is added to the data warehouse. The previous address is retained with its respective timestamp.
Type 3: Add New Attribute
Similar to SCD Type 2, you can also track record changes with SCD Type 3. However, instead of adding a new row for every change, a new column is added to track the previous value. But, this method preserves the most recent history, as it is limited to the number of columns designated for storing historical data.
The SCD Type 3 stores two versions of values for the selected level attributes. Each record will store the current and previous values of the selected attribute. Whenever the value of the attribute changes, the current value gets stored as the old value, and the new value becomes the current value.
The benefit of this SCD type is it requires less storage space. Also, it enables fast queries since there’s limited history to scan. However, it doesn’t provide a complete history of changes since it only tracks limited changes. Columns that require full history might not be suitable for tracking changes.
An example of SCD Type 3 is in product pricing or financial reporting, where the previous and current values of a service or product are important.
Type 4: Add History Table
This slowly changing dimension involves maintaining the records in two different tables—a current record table and a historical record table. Changes are tracked in a separate history table. While the main dimension table stays current, the history table stores past data.
With SCD Type 4, a record will be added to the history table for each change in the source system. It’s useful for keeping track of records that have many changes over time. It allows to retain both the original and updated data while still maintaining a small footprint for the main table. The method resembles how change data capture techniques and database audit tables function.
An example of SCD Type 4 is when a product’s price changes. The old price and the effective date are added to a separate history table, while the current price is stored in the main dimension table.
Type 6: Combined Approach
The SCD Type 6 is a hybrid approach of Type 1, Type 2, and Type 3. This includes columns for both historical and current data and a column to track the current version of the record.
Both historical and current data can be stored in the same row, with the current version being easily accessible. This SCD type is useful when a business wants to view both current and historical data in the same report.
An example of SCD Type 6 is when an employee’s role and department might change. While the role change can be presented in a new row (Type 2), the department can be overwritten (Type 1). A column can indicate the previous role (Type 3).
Limitations of Slowly Changing Dimensions in Data Science
While SCDs are an essential part of data warehousing, allowing historical data to be preserved along with changes over time, there are some associated limitations, such as:
- Storage Space: A dataset with a vast number of input features can rapidly increase storage requirements. This is especially true for SCD Type 2, which involves adding a new row for each change.
- Maintenance: With an increase in the number of attributes or dimensions, tracking becomes complex. This can result in an increased possibility of errors.
- Performance: As the data volume increases to track historical changes, the machine learning model’s performance may sometimes deteriorate.
- Scalability: With growing data and accumulated changes, some SCD types might not scale efficiently. This affects storage, computation, and visualization.
- Storage: With slowly changing dimensions in data science, every change captured results in an increase in data storage requirements. Additionally, processing datasets with increasing dimensions can be computationally expensive.
- Redundancy: Most slowly changing dimensions in data science involve redundancy. For example, in SCD Type 2, a new row is added for every change in a dimension. Eventually, this results in multiple rows for the same entity and increased dimensionality. Dimension reduction helps identify and manage such redundancy.



How to Implement Slowly Changing Dimensions in a Data Warehouse?
Ideally, slowly changing dimensions are best considered right at the start of your database creation. If you’re just beginning to build your data infrastructure or working for a startup, this is easier to implement.
For existing databases, start by assessing the data that currently exists in your database. Document the different types of dimensions you find and how they relate to one another. If there are dimensions of type 0 that shouldn’t be, start with those. And if required, add historical tracking as soon as possible.
Next, determine whether you would prefer types 2, 3, or 4 and if they are suitable for your business. Some questions to evaluate are:
- How often do these dimensions change?
- Would you use a timestamp column or a flag column?
- Should you add a historical table that can store a lot of records?
Such a process will involve analytics engineers, data engineers, and data analysts.
Another important thing to consider is how you want to handle previous records that weren’t tracked over time. While you can forgo the historical data and implement SCD for future operations, it would be best to put together old records and create your own version of a timestamp or flag column.
Conclusion
Slowly changing dimensions in data science accommodate the slowly evolving nature of datasets and help preserve historical records. The five types of slowly changing dimensions in data science provide different mechanisms to track and store changes in evolving data. You can implement the appropriate slowly changing dimension type based on your business needs and experience change data capture techniques.
Hevo is an intuitive no-code integration platform connecting over 150+ sources. Take a look at our unbeatable pricing plans and find the perfect one that works best for you and your business needs. Try a 14-day free trial and experience the features of the Hevo suite for yourself!
FAQ on Slowly Changing Dimensions
1. What is a Slowly Changing Dimension (SCD)?
Slowly Changing Dimensions (SCD) refers to a data warehousing method for handling and tracking changes in dimensional data over time. This ensures that historical data remains accurate and up-to-date.
2. What are the different types of Slowly Changing Dimensions (SCDs)?
SCD types include
– Type 0: Attribute remains unchanged.
– Type 1: Overwrites old data.
– Type 2: Adds new rows for changes.
– Type 3: Adds new columns for changes.
– Type 4: Uses separate history tables.
– Type 6: Combines Types 1, 2, and 3 for comprehensive tracking.
3. What is the most common Slowly Changing Dimension?
Type 2 SCD is the most common, as it preserves full historical data by adding new records for each change, allowing users to track changes over time.
4. Which SCD type suits different reporting needs?
The ideal SCD type varies based on reporting requirements. For instance, Type 0 works best for static attributes or those not crucial for analysis, offering simplicity and speed. Type 1 is more suitable for frequently changing attributes where maintaining historical data isn’t necessary.
5. What are some examples of Slowly Changing Dimensions (SCDs)?
Examples of Slowly Changing Dimensions (SCDs) include geographical locations, customer details, and product attributes that change over time.
6. How are Slowly Changing Dimensions (SCDs) different from Change Data Capture (CDC)?
SCDs manage historical changes in a data warehouse to track how data evolves over time, while CDC provides real-time updates on changes made to data. Together, they ensure accurate and up-to-date data management.


Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



