



Have you just started with Snowflake? Are you confused about how to create a database in Snowflake? If yes, then you are in the right place. In this blog post, you’ll learn about Snowflake, databases, and how to create a database in Snowflake.
Table of Contents
Introduction to Snowflake
Snowflake is a cloud-based data warehouse that uses Amazon web services or Azure as its cloud infrastructure and is entirely a Software-as-a-Service offering. Snowflake handles all the maintenance and performance tuning activities, and you don’t need to install, configure, or manage any hardware or software.
Components of Snowflake
There are three main components in the Snowflake architecture (assuming AWS as its cloud infrastructure):
- Database Storage: Snowflake uses Amazon S3 as the file system to store the encrypted, compressed, and distributed data to optimize performance. The data stored in these file systems are not visible to the user and can only be accessed via the SQL interface provided by Snowflake. Snowflake handles all the aspects of the data like metadata, compression, encryption, data storage, statistics, etc.
- Query Processing: Snowflake has the concept of a virtual warehouse, which are Amazon EC2 clusters that provide compute power to the queries. Each virtual warehouse contains an MPP EC2 compute cluster with multiple nodes to perform quick analysis over data. Snowflake automatically manages the scale-up or down of these virtual warehouses on demand and allows you to pause these clusters when not in use.
- Cloud Services: This layer is a collection of all the services offered by Snowflake. It coordinates and handles services in Snowflake that includes sessions, authentication, metadata management, infrastructure management, SQL compilation, encryption, etc.
Migrating your data to Snowflake doesn’t have to be complex. Relax and go for a seamless migration using Hevo’s no-code platform. With Hevo, you can:
- Effortlessly extract data from 150+ connectors.
- Tailor your data to Snowflake’s needs with features like drag-and-drop and custom Python scripts.
- Achieve lightning-fast data loading into Snowflake, making your data analysis-ready.
Try to see why customers like EdApp and Harmoney have upgraded to a powerful data and analytics stack by incorporating Hevo!
Get Started with Hevo for FreeKey Features of Snowflake
- Query Optimization: Snowflake can optimize the query by clustering and partitioning on its own. You don’t need to worry about query optimization.
- Support for Different File Formats: Snowflake allows you to import semi-structured data such as JSON, Avro, ORC, Parquet, and XML data. It provides a particular column type, VARIANT, which allows you to store semi-structured data.
- Standard and Extended SQL Support: Snowflake has excellent support for ANSI SQL and supports advanced SQL functionality like merge, lateral view, statistical functions, and many more.
- Fault-Tolerant: Snowflake provides exceptional fault-tolerant capabilities to recover the Snowflake object (tables, views, database, schema, etc.) in case of failure.
Introduction to Database
A database controls and organizes structured information or data with the help of a database management system (DBMS). The database allows you to easily access, monitor, organize, and manage the data. A large number of databases use structured query language (SQL) for writing and querying data. Snowflake is a data warehouse that is used to manage and analyze data from different sources. The key differences between a database and a data warehouse are as follows:
- The database is typically used to store or record the data, whereas a data warehouse is designed to analyze the data with the help of its programming interface. In the case of Snowflake, SQL is used to perform complex calculations.
- The database is application-oriented and is used based on the application, whereas a data warehouse is a subject-oriented collection of data.
- The database uses Online Transactional Processing (OLTP), whereas the data warehouse uses Online Analytical Processing (OLAP).
- The database is designed to hold the data up to gigabytes, whereas data warehouses can store data up to terabytes.
- The database is used for query processing, whereas a data warehouse is used when there is a need for data analytics and decision-making.
Need for Database
In the relational world, databases organize and manage database objects like tables, views, etc. Snowflake is a fully managed data warehouse that manages data centrally to perform faster analysis. In Snowflake, schema organizes the data stored in Snowflake, whereas the database logically groups the data. In contrast, schema logically arranges the database objects like tables, views, etc. In Snowflake, the database and schema together comprise a namespace. A namespace is explicitly required when you want to execute any operation on Snowflake. If the schema and database are already selected, then this parameter is optional.
Also, understand the concept of Snowflake Replication to get an advanced understanding of how you can work with your Snowflake data.
ETL cost visibility without leaving Snowflake.

Snowflake Create Database Command
Let’s understand the semantics of Snowflake. The Snowflake create database command creates a new database in the system as well as can be used:
- To clone the existing database.
- To create a database from another Snowflake account.
- To create a replica of the current database.
Let’s learn about the various syntax of Snowflake create database command:
- Snowflake Create Database: The Syntax for Standard Database
- Snowflake Create Database: The Syntax for Shared Database
- Snowflake Create Database: The Syntax for Database Replication
1. The Syntax for Standard Database

- <name>: Specifies the case-sensitive unique identifier name for the database.
- TRANSIENT: Specifies a transient (temporary) database. It is not fail-safe and is session-based. Once you terminate the session, complete data, i.e., tables, views, objects, are wiped out.
- CLONE: This is used to create the clone of the existing database.
- AT | BEFORE ( TIMESTAMP | OFFSET | STATEMENT ): When cloning a database, “AT | BEFORE” specifies time travel to the clone database at or before a specific period in the past.
- DATA_RETENTION_TIME_IN_DAYS: The default value is 1 (Standard database), and it specifies the period to retain the objects created in the database.
- COMMENTS: It specifies an explanation for the database.
2. The Syntax for Shared Database

- <name>: It specifies the case-sensitive unique identifier name for the database.
- <provider_account.share_name>: It specifies the account name and shares the name of the sharing database.
3. The Syntax for Database Replication

- <name>: It specifies the case-sensitive unique identifier name for the database.
- AS REPLICA OF Snowflake_region.account_name.primary_db_name: It specifies a namespace along with the region and account name while cloning the primary database.
- AUTO_REFRESH_MATERIALIZED_VIEWS_ON_SECONDARY = TRUE | FALSE: This command enables the automatic refresh of the views/database in the secondary database. By default, it is false. When set true, this enables automatic maintenance of materialized views in the secondary database. When set false, it disables the automatic background maintenance of materialized views.



Examples of Snowflake Create Database Command
In this section, you will see some examples of using Snowflake’s “create database” command.
- Snowflake Create Database: Create a Permanent Database
- Snowflake Create Database: Create a Transient Database
- Snowflake Create Database: Create a Database Replication
1. Create a Permanent Database
You can create a standard database alone, or you can create a standard database with the retention period.
- To create standard database:
create database db_test1;- To create standard database with retention period:
create database db_test2 data_retention_time_in_days = 10;- To show the created database:
show databases like 'db%';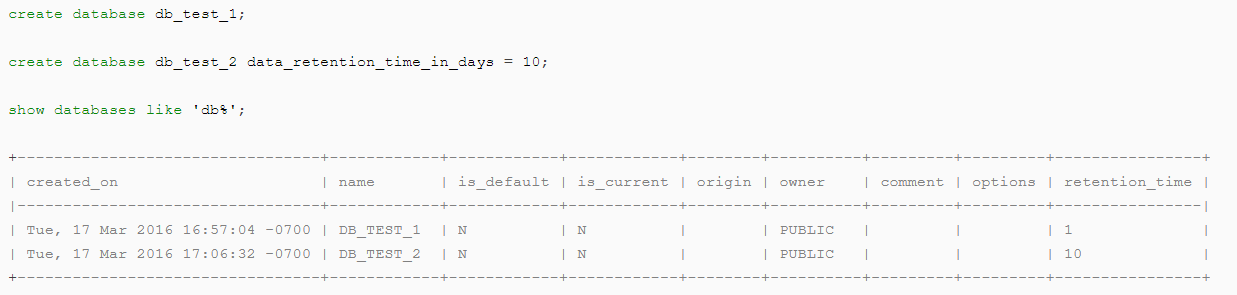
2. Create a Transient Database
Here’s an example of a transient database.
create transient database db_transient_1;
show databases like ‘db%';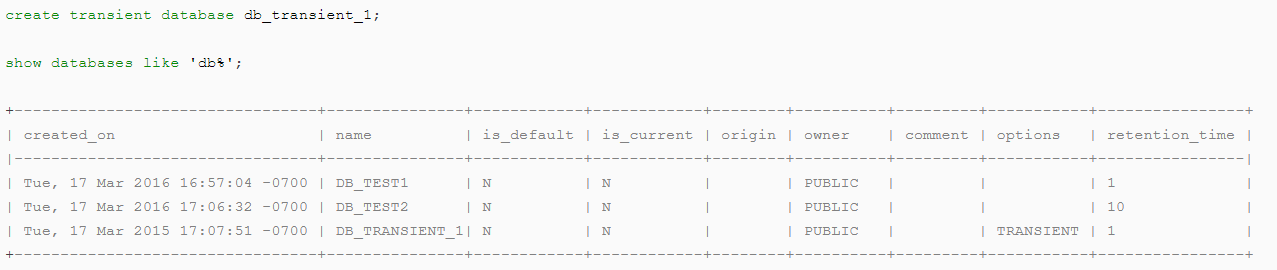
3. Create a Database Replication
To create a replication of a database, below command can be used:
create database mydb1
as replica of aws_us_west_2.myaccount.mydb1
auto_refresh_materialized_views_on_secondary = true;
Limitations of Snowflake Create Database Command
Although Snowflake is a fully managed advanced data warehouse, certain shortcomings cannot be overlooked. Some of them are as follows:
- Snowflake owns the development infrastructure, and in case of any failure, you have to be dependent on the Snowflake support team.
- Snowflake also holds complete data of the user in its private cloud, and all the services are shared. In case of any security-related issue, there is a risk of data exposure.
- Snowflake has a small ecosystem, and a lot of advanced functionality is missing. It has no geospatial support, minimal user interface functionality, and immature ETL tool integration.
- Snowflake UDF’s work only on SQL and Javascript. You cannot use python or other languages to create UDF’s.
Conclusion
Snowflake is a powerful, fully managed platform used for data warehousing and analytics. In this blog post, you have learned about the Snowflake’s database, its uses, and ways to create various types of databases. However, when it comes to fully managed ETL, you can’t find a better solution than Hevo.
Hevo is a No-code Data Pipeline product that will help you move data from multiple data sources to your destination. It is consistent and reliable. It has pre-built integrations from 100+ sources.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
FAQs
1. How to create a database in Snowflake example?
In Snowflake, you can create a database using the following SQL command:
CREATE DATABASE my_database;
2. Can Snowflake be used as a database?
Yes, Snowflake is a cloud-based data warehouse and can be used as a database for storing, querying, and analyzing structured and semi-structured data.
3. Which role can create a database in Snowflake?
The ACCOUNTADMIN or SYSADMIN roles, along with any role with the appropriate CREATE DATABASE privilege, can create a database in Snowflake.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





