




Snowflake is a Cloud-Based Data Warehouse created in 2012 by three Data Warehousing professionals. Six years later, the firm was valued at $3.5 billion after receiving a $450 million venture capital investment. But what is Snowflake, and why is this Cloud-Based Data Warehouse making such a stir in the analytics community?
This article helps you uncover the unique features of the Snowflake Data Warehouse. You will also get a quick walk-through on the implementation of some of the important Snowflake features such as schemaless loading of JSON/XML, Time Travel, Cloning, Data Clustering, etc., provided by Snowflake. You will also look into the benefits of using Snowflake in comparison to other Data Warehouse Providers. Let’s get started.
Table of Contents
What is Snowflake?

Snowflake is a fully managed Cloud Data Warehouse that is offered as Software-as-a-Service (SaaS) or Database-as-a-Service (DaaS) to clients. Snowflake uses the ANSI SQL protocol, which supports both fully structured and semi-structured data formats such as JSON, Parquet, and XML. It is highly scalable in terms of user count and processing capacity, with pricing based on per-second resource use.
Snowflake Features and Capabilities
Snowflake takes care of all the database management and assures the best performance when tables are queried. All one needs to do is create tables, load the data, and query it. One need not create partitions, and indexes like in RDBMS or run vacuum operations like in Redshift either.
The details of how Snowflake accomplishes this can be best understood by knowing the Snowflake Table structures and its principal concepts.
Hevo Data, a No-code Data Pipeline, helps load data from any data source, such as Databases like Snowflake, SaaS applications, Cloud Storage, SDK, and Streaming Services, and simplifies the ETL process. It supports 150+ data sources and is a three-step process that involves selecting the data source, providing valid credentials, and choosing the destination.
Hevo not only loads the data onto the desired Data Warehouse/destination but also enriches it and transforms it into an analysis-ready form without writing a single line of code.
Check out why Hevo is the Best:
- Live Monitoring: Hevo allows you to monitor the data flow and check where your data is at a particular time.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional customer support through chat, E-Mail, and support calls.
Overview of Snowflake Table Structures
Two principal concepts used by Snowflake to physically maintain Table Structures for best performance are:
- Micro-Partitions
- Data-Clustering
1) Micro-Partitions
Snowflake stores the data in a table using a columnar fashion divided into a number of micro-partitions which are contiguous units of storage of size around 50 MB to 500 MB of uncompressed data. Unlike traditional databases, partitions aren’t static and aren’t defined and maintained by users but are automatically managed by the Snowflake Data Warehouse in a dynamic fashion.
A table can consist of thousands or millions of micro-partitions in Snowflake depending on the table size.
Example:
Let’s consider a table consisting of Student data as shown below: This data will be broken into multiple micro-partitions in Snowflake. Let’s assume 3 micro-partitions are created for this table, data will be partitioned as below in a columnar fashion:
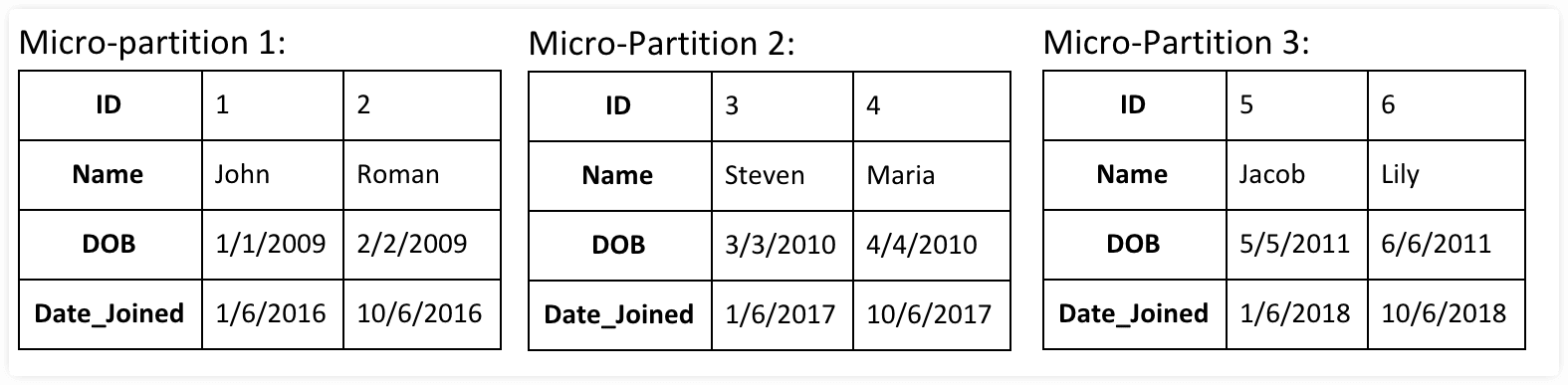
As seen in the above tables, data will be partitioned into 3 parts and stored in a columnar fashion. Data is also sorted and stored at each micro-partition level.
2) Data-Clustering
Data-Clustering is similar to the concept of sort-key available in most MPP Databases. As data is loaded into Snowflake, it co-locates column data with the same values in the same micro-partition. This helps Snowflake to easily filter out data during data scan, as the entire micro-partition can be skipped if a value doesn’t exist in the range of that micro-partition.
Snowflake automatically does the job of clustering on the tables, and this natural clustering process of Snowflake is good enough for most cases and gives good performance even for big tables.
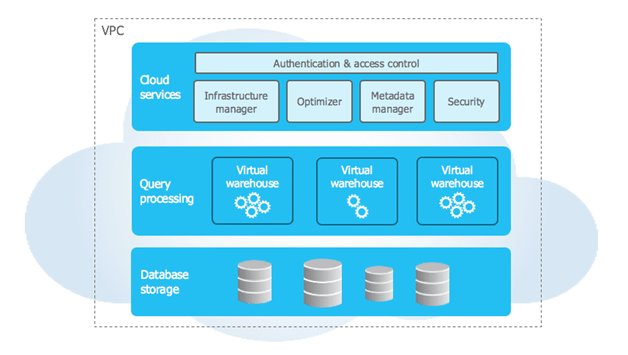
However, if a user wants to do manual clustering, there is a concept of the clustering key which can be defined on the table by the user and Snowflake uses this key to do the clustering on the table. This can be useful only for very large tables. Below is the architecture of Snowflake for your reference.
Few Other Important Snowflake Features
Snowflake is a cloud-based data warehousing platform packed with advanced capabilities. Here’s a summary of its standout features:
- Scalable Storage and Compute: Automatically scales to handle nearly unlimited data storage and processing needs.
- Data Security and Governance: Offers robust security features like role-based access control, object tagging, masking policies, and end-to-end encryption.
- Data Management: Enables un-siloed access, optimized compression, and secure cloning of production databases for development or testing.
- AI and ML Capabilities: Supports advanced AI and ML workflows with Cortex AI for NLP tasks, distributed feature engineering, and model training.
- Cross-Cloud Collaboration: Snowgrid allows seamless data sharing, access, and global collaboration across different cloud environments.
- Marketplace: Provides access to over 2,300 third-party datasets, services, and apps via the Snowflake Marketplace.
Additional Unique Features
1) Time Travel
Time Travel is one of the unique Snowflake features. Time Travel allows you to track the change of data over time. This Snowflake feature is available to all accounts and enabled by default to all, free of cost. Moreover, this Snowflake feature allows you to access the historical data of a Table. One can find out how the table looked at any point in time within the last 90 days.
For standard accounts, a maximum of 1 day Time Travel retention period is given by default. In the Enterprise edition, this can be extended up to 90 days.
2) Cloning
Another important Snowflake feature is Cloning. We can use the clone feature to create an instant copy of any Snowflake object such as databases, schemas, tables, and other Snowflake objects in near real-time without much waiting time. This is possible due to Snowflake’s architecture of storing data as immutable in S3 and versioning the changes and storing the changes as Metadata.
Hence a clone of an object is actually a Metadata operation and doesn’t actually duplicate the storage data. So let’s say you want a copy of the entire Production database for some testing purpose, you can create it in seconds using the Clone feature. Thus, Cloning is one of the important Snowflake features.
3) Undrop
UNDROP is also one of the unique Snowflake features. Using this, a dropped object can be restored using the Undrop command in Snowflake, as long as that object is still not purged by the system.
Undrop restores the object to the state it was before dropping the object. Objects such as Databases, Schemas, or Tables can be undropped.
drop database testdb;
undrop database testdb;
drop table some_table;
undrop table some_table;Undrop can be used to restore multiple times as well, let’s say a table has been dropped 3 times and re-created each time. Each dropped version can be undropped in reverse order of drop i.e. last dropped version is restored first. This works as long as the existing table with the same name is renamed before Undrop operation.
4) Fail-Safe
Another important Snowflake feature is Fail-Safe. Fail-Safe ensures historical data is protected in event of disasters such as disk failures or any other hardware failures. Snowflake provides 7 days of Fail-Safe protection of data which can be recovered only by Snowflake in event of a disaster.
Fail-Safe 7-day duration starts after the Time Travel period is ended. Hence, a table with 90 days of Time Travel will have an overall of 97 days for recovery. However, Fail-Safe cannot be recovered by users or through DDLs. It is handled by Snowflake only during catastrophic disasters.
5)Support for Semi-structured Data
Snowflake’s ability to combine structured and semi-structured data without the use of complex technologies like Hadoop or Hive is one of the most significant steps toward big data. Data can come from a variety of places, including machine-generated data, sensors, and mobile devices. Snowflake supports semi-structured data ingestion in a variety of formats, including JSON, Avro, ORC, Parquet, and XML, using the VARIANT data type, which has a size limit of 16MB. Snowflake also optimizes the data by extracting as much as possible in columnar format and storing the remainder in a single column. Data functions that can parse, extract, cast, and manipulate data can also be used to flatten nested structures in semi-structured data.
6) Continuous Data Pipelines
Snowflake has a number of features that allow for continuous data ingestion, change data tracking, and the creation of recurring tasks in order to create continuous data pipeline workflows.
6.1. Snowpipe for continuous data ingestion
Snowpipe is Snowflake’s data ingestion service that runs in the background. Snowpipe is a pipeline that allows you to load new data in micro-batches as soon as it becomes available in an external stage like AWS S3, allowing you to access it in minutes rather than having to manually load larger batches using COPY statements.
6.2. Change data capture using Streams
It’s helpful to know which data has changed when copying new data from staging tables to other tables so that only the changed data is copied. Snowflake table streams are a useful feature for doing exactly that: capturing metadata about DML changes made to a table, as well as the state of a row before and after the change so that actions can be taken with the changed data. Change data capture is another name for this.
6.3. Schedules SQL statements using Tasks
Tasks are a feature that allows you to run SQL statements on a schedule that you set when you create the task. Single SQL statements or stored procedures can be executed by tasks. They’re great for things like generating report tables on a regular basis, or as part of data pipelines that capture recently changed table rows from table streams and transform them for use in other tables.
7) Caching Results
To help speed up your queries and reduce costs, the Snowflake architecture includes caching at various levels. When a query is run, for example, Snowflake keeps the results of the query for 24 hours. So, if the same query is run again by the same user or another account user, the results are already available to be returned, assuming the underlying data hasn’t changed. This is especially useful for analysis work, as it eliminates the need to rerun complex queries to access previous data or compare the results of complex queries before and after a change.
8) Sharing data between accounts
Snowflake’s Secure Data Sharing feature allows you to share objects (such as tables) from a database in your account with another Snowflake account without having to duplicate the data. As a result, the shared data does not require additional storage space and does not add to the data consumer’s storage costs. Because data sharing is done through Snowflake’s metadata store, the setup is simple, and data consumers have immediate access to the information.
These were some of the Snowflake features that set it apart from other Data Warehouses.
Connectivity Support in Snowflake Data Warehouse
One of the important Snowflake features is Connectivity. Snowflake provides various Connectivity options including Native connectors (e.g. Python), JDBC/ODBC drivers, a Command-Line tool called “SnowSQL”, Web Interface which helps to manage Snowflake as well as to query the data.
Snowflake accounts can be hosted on either Amazon AWS or Microsoft Azure cloud platforms. Hence depending on the organizations existing Cloud service provided one among AWS or Azure can be chosen.
A Snowflake-native app to monitor Fivetran costs.

What is the Pricing of Snowflake Data Warehouse?
Snowflake features come with reasonable pricing. Below are some of the insights related to Snowflake pricing.
- Snowflake Data Warehouse charges for Storage and Computing separately.
- Data stored in the Snowflake will be charged as per the average monthly usage per TB or can be paid upfront costs per TB to save storage costs.
- Compute costs are separate and will be charged at per second usage depending on the size of the virtual warehouse chosen from X-Small to 4X-Large.
- Snowflake bills compute costs as credits, depending on the size of the warehouse, per hour credit cost varies from 1 credit per hour for X-Small to 128 credits per hour for 4X-Large. Note, Snowflake charges per second.
- Depending on the Cloud Platform i.e. AWS or Azure and the region costs can vary.
What are the Benefits of Creating an Account on Snowflake?
Before getting started with the Snowflake features, some of the benefits provided by Snowflake include:
- Snowflake provides $400 free credits to try and explore the warehouse.
- Once registered, one needs to set up the warehouse to use for loading the data.
- Loading data into the warehouse is one of the trickiest things in Snowflake.
There are two ways to do this:
You can create databases/schemas/tables as required and load the data using the “COPY INTO” command or query a file directly on cloud storage like S3 using the Select statement.
Alternatively, you can use an official Snowflake ETL Partner like Hevo (14-day free trial) to easily load data from a wide array of sources into Snowflake.
What are the Use-Cases of Snowflake Data Warehouse?
Snowflake features can be used to host a Data Warehouse in the cloud of any scale for analysis of various data from different sources. Snowflake feature supports loading from various formats including traditional compressed CSVs to semi-structured data such as JSON/XML from Cloud storage like S3 or Azure. If you need to load data from a variety of different sources, you could use a data integration platform like Hevo.
Common use cases for using Snowflake features include:
- Analytics on data available in Data Lake on Cloud Storage like S3.
- Rapid delivery of analytics to Business without worrying about managing the warehouse.
- Data Sharing: If an organization wants to share data outside then Snowflake can be used to quickly set up to share data without transferring or developing pipelines.
- Snowflake can be used to set up an Insights-as-a-Service platform.



Conclusion
If you are considering setting up a data warehouse, Snowflake is a strong contender, you can check out our article to know about Snowflake Architecture and Snowflake’s best practices for high-performance ETL. There are many features that work out of the box on Snowflake in comparison to Redshift and Bigquery, the other popular choices for Data Warehousing.
Businesses can use automated platforms like Hevo Data to set this integration and handle the ETL process. It helps you directly transfer data from a source of your choice to a Data Warehouse, Business Intelligence tools, or any other desired destination in a fully automated and secure manner without having to write any code and will provide you a hassle-free experience. Try a 14-day free trial to explore all features, and check out our unbeatable pricing for the best plan for your needs.
Frequently Asked Questions
1. What is Snowflake’s Time Travel feature?
It basically allows a user to browse historical data and recover dropped tables or schemas. This feature allows for the viewing of data at points up to 90 days ago.
2. What is Snowflake’s Cloning feature?
With Cloning, users can copy virtually instantly any Snowflake object, ranging from a table to a database, by proliferating metadata without actually copying data, which helps to test and make development easier.
3. Does Snowflake support data sharing?
Snowflake charges based on actual usage of storage and compute resources, thus directly helping the business organization with cost optimization through upscaling or downscaling as necessary.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



