




Snowflake Data Warehouse delivers essential infrastructure for handling a Data Lake, and Data Warehouse needs. It can store semi-structured and structured data in one place due to its multi-clusters architecture that allows users to independently query data using SQL. Moreover, Snowflake as a Data Lake offers a flexible Query Engine that allows users to seamlessly integrate with other Data Lakes such as Amazon S3, Azure Storage, and Google Cloud Storage and perform all queries from the Snowflake Query Engine.
This article will give you a comprehensive guide to Snowflake Data Warehouse. You will get to know about the architecture and performance of Snowflake Data Warehouse. You will also explore the Features, Pricing, Advantages, Limitations, and many more in further sections. Let’s get started.
Table of Contents
What is Snowflake Data Warehouse?

Snowflake Data Warehouse is a fully managed, cloud data warehouse available to customers in the form of Software-as-a-Service (SaaS) or Database-as-a-Service (DaaS). The phrase ‘fully managed’ means users shouldn’t be concerned about any of the back-end work like server installation, maintenance, etc. A Snowflake Data Warehouse instance can easily be deployed on any of the three major cloud providers –
- Amazon Web Services (AWS)
- Google Cloud Storage (GCS)
- Microsoft Azure
The customer can select which cloud provider they want for their Snowflake instance. This comes in handy for firms working with multiple cloud providers. Snowflake querying follows the standard ANSI SQL protocol and it supports fully structured as well as semi-structured data like JSON, Parquet, XML, etc.
Architecture of Snowflake Data Warehouse
Here’s a diagram depicting the fundamental Snowflake architecture –
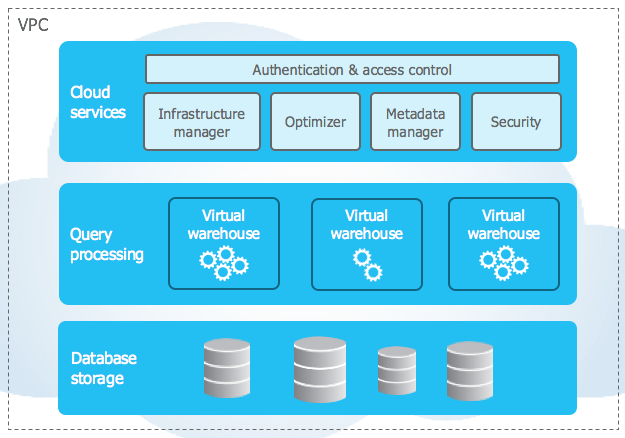
Storage Level
At the storage level, cloud storage includes both shared-disk (for storing persistent data) and shared-nothing (for massively parallel processing or MPP of queries with portions of data stored locally) entities.
Ingested cloud data is optimized before storing in a columnar format. The data ingestion, compression, and storage are fully managed by Snowflake; as a matter of fact, this stored data is not directly accessible to users and can only be accessed via SQL queries.
Query Processing Level
Next up is the query processing level, where the SQL queries are executed. All the SQL queries are part of a particular cluster that consists of several compute nodes (this is customizable) and are executed in a dedicated MPP environment. These dedicated MPPs are also known as virtual data warehouses.
It is not uncommon for a firm to have separate virtual data warehouses for individual business units like sales, marketing, finance, etc. This setup is more costly, but it ensures data integrity and maximum performance.
Cloud Services
Finally, we have cloud services. As mentioned in the boxes, these are a bunch of services that help tie together the different units of Snowflake, ranging from access control/data security to infrastructure and storage management. Know more about Snowflake Data Warehouse architecture.
A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate data from 150+ Data Sources (including 60+ Free Data Sources) to a destination of your choice, such as Snowflake, in real-time in an effortless manner. Check out why Hevo is the Best:
- The Hevo team is available round the clock to extend exceptional customer support.
- Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data
- Hevo allows the transfer of data that has been modified in real-time.
Performance of Snowflake Data Warehouse
The Snowflake Features has been designed for simplicity and maximum efficiency via parallel workload execution through the MPP architecture. The idea of increasing query performance is switched from the traditional manual performance tuning options like indexing, sorting, etc. to following certain generally applicable best practices. These include the following –
1. Workload Separation
Because it is super easy to spin up multiple virtual data warehouses with the desired number of compute nodes, it is a common practice to divide the workloads into separate clusters based on either Business Units (sales, marketing, etc.) or type of operation (data analytics, ETL/BI loads, etc.) It is also interesting to note that virtual data warehouses can be set to auto-suspend (default is 10 minutes) when they go inactive or in other words, no queries are being executed. This feature ensures that customers don’t accrue a lot of costs while having many virtual data warehouses operate in parallel.
2. Persisted or Cached Results
Query results are stored or cached for a certain timeframe (default is 24 hours). This is utilized when a query is essentially re-run to fetch the same result. Caching is done at two levels – local cache and result cache. Local cache provides the stored results for users within the same virtual data warehouse whereas result cache holds results that could be retrieved by users regardless of the virtual data warehouse they belong to.
A Snowflake-native app to monitor Fivetran costs

ETL and Data Transfer in Snowflake Data Warehouse
ETL refers to the process of extracting data from a certain source, transform the source data to a certain format (typically the format that matches up to the target table) and load this data into the desired target table. Snowflake has been designed to connect to a multitude of data integrators using either a JDBC or an ODBC connection.
In terms of loading data, Snowflake offers two methods –
- Bulk Loading
This is basically batch loading of data files using the COPY command. COPY command lets users copy data files from the cloud storage into Snowflake tables. This step involves writing code that typically gets scripted to run at scheduled intervals. - Continuous Loading
In this case, smaller amounts of data are extracted from the staging environment (as soon as they are available) and loaded in quick increments into a target Snowflake table. The feature named Snowpipe makes this possible.


Key Features of Snowflake Data Warehouse
Ever since the Snowflake Data Warehouse got into the growing cloud Data Warehouse market, it has established itself as a solid choice. That being said, here are some things to consider that might make it particularly suitable for your purposes –
- It offers five editions going from ‘standard’ to ‘enterprise’. This is a good thing as customers have options to choose from based on their specific needs.
- The ability to separate storage and compute is something to consider and how that relates to the kind of data warehousing operations you’d be looking for.
- Snowflake is designed in a way to ensure the least user input and interaction required for any performance or maintenance-related activity. This is not a standard among cloud DWHs. For instance, Redshift needs user-driven data vacuuming.
- It has some cool querying features like undrop, fast clone, etc. These might be worth checking out as they may account for a good chunk of your day-to-day data operations.
Pros and Cons of Snowflake Data Warehouse
Here are the advantages and disadvantages of using Snowflake Data Warehouse as your data warehousing solution –
| Pros | Cons |
| Fully managed, cloud-deployed DWH requiring minimal effort to get set up and running. | The dependence that Snowflake has on AWS, Azure, or GCS can be a problem at times when there is an independent (independent of Snowflake operations’ ‘health’) outage in one of these cloud servers. |
| Easy to scale with a lot of flexible options (as discussed above). | Currently, it doesn’t have many options to work with geospatial data. |
| It follows the ANSI SQL protocol and supports fully structured and semi-structured data types like JSON, Parquet, XML, ORC, etc. | Doesn’t have any provision to support unstructured data as of yet. |
| Currently, it doesn’t have many options for working with geospatial data. | It is not known particularly for its customer support. |
| Quite popular and successful with a large number of clients using the service, Snowflake competes in the same league as Amazon Redshift, Google BigQuery, etc. |
Pricing of Snowflake Data Warehouse
Snowflake has a fairly simple pricing model – charges apply to storage and computing, aka virtual data warehouses. The storage is charged for every Terabyte (TB) of usage while computing is charged on a per-second per computing unit (or credit) basis. Before getting into an example, it is worthwhile to note that Snowflake offers two broader pricing models –
- On-demand – Pay per your usage of storage and compute
- Pre-purchased – A set capacity of storage and computing could be pre-purchased at a discount as opposed to accruing the same usage at a higher cost via on-demand.
Now, onto the usage pricing examples; the two popular on-demand pricing models available are as follows –
1. Snowflake Standard Edition
Storage costs you around $23 per TB and computes costs would be approximately 4 cents per minute per credit, billed for a minimum time of one minute.
2. Snowflake Enterprise Sensitive Data Edition
Being a premium version with advanced encryption and security features as well as HIPAA compliance, storage costs roughly the same while compute gets bumped to around 6.6 cents per minute per credit.
The above charges for compute apply only to ‘active’ data warehouses and any inactive session time is ignored for billing purposes. This is why it’s important and profitable to set features like auto-suspend and auto-scale in a way as to minimize the charges accrued for idle warehouse periods.
Data Security & Maintenance on Snowflake Data Warehouse
Data security is dealt with very seriously at all levels of the Snowflake ecosystem. Regardless of the version, all data is encrypted using AES 256, and the higher-end enterprise versions have additional security features like period rekeying, etc.
As Snowflake is deployed on a cloud server like AWS or MS Azure, the staging data files (ready for loading/unloading) in these clouds get the same level of security as the staging files for Amazon Redshift or Azure SQL Data Warehouse. While in transit, the data is heavily protected using industrial-strength secure protocols. Know more about Snowflake Data Warehouse security.
As for maintenance, Snowflake is a fully managed cloud data warehouse, end users have practically nothing to do to ensure a smooth day-to-day operation of the data warehouse. This helps customers tremendously to focus more on the front-end data operations like data analysis and insights generation, and not so much on the back-end stuff like server performance and maintenance activities.
Learn about other effective data loading options by checking out our blog on Snowpipe alternatives for optimizing your Snowflake data warehouse.
Alternatives for Snowflake Data Warehouse
The shift towards cloud data warehousing solutions picked up at a real pace in the late 2000s, thanks to Google and Amazon. Since then, so many traditional database vendors like Microsoft, Oracle, etc., as well as newer players like Vertica, Panoply, etc., have entered this space. Having said that, let’s take a look at some of the popular alternatives to Snowflake.
1. Amazon Redshift vs Snowflake
| Criteria | Amazon Redshift | Snowflake |
| Data Support | Structured and semi-structured (JSON) columnar | Structured and semi-structured, columnar |
| Compute and Storage | Not separate (integrated) | Separate, allowing independent scaling |
| Pricing Model | Generally costlier, usage-based pricing | Discounted pre-purchase pricing |
| Integration | Strong AWS ecosystem integration | Works across multiple clouds, flexible integration |
2. Google BigQuery vs Snowflake
| Criteria | Google BigQuery | Snowflake |
| Data Support | Columnar, structured data | Structured and semi-structured, columnar |
| Compute and Storage | Separate (like Snowflake) | Separate, allowing independent scaling |
| Pricing Model | Flat-rate monthly/yearly pricing | Discounted pre-purchase pricing |
| Integration | Strong integration with Google Cloud services | Works across multiple clouds, flexible integration |
3. Azure SQL Data Warehouse vs Snowflake
| Criteria | Azure SQL | Snowflake |
| Data Support | Columnar, structured data | Structured and semi-structured, columnar |
| Compute and Storage | Separate (like Snowflake) | Separate, allowing independent scaling |
| Pricing Model | Usage-based pricing, competitive with Snowflake | Discounted pre-purchase pricing |
| Integration | Strong integration with Microsoft products | Works across multiple clouds, flexible integration |
How to Get Started with Snowflake?
Here are some resources for you to get started with Snowflake.
- Snowflake Documentation: This is the official documentation from Snowflake about their services, features, and provides clarity on all aspects of this data warehouse.
- Snowflake ecosystem of partner integrations. This takes you to their integration options to third-party partners and technologies having native connectivity to Snowflake. This includes various data integration solutions to BI tools to ML and data science platforms.
- Pricing page: You can check out this link to know about their pricing plans which also contains guides and relevant contacts for Snowflake consultants.
- Community forums: There are different Community Groups under major topics on Snowflake website. You can check out Snowflake Lab on GitHub or visit StackOverflow or Reddit forums as well.
- Snowflake University and Hands-on Lab: This contains many courses for people with varying expertise levels.
- YouTube channel: You can check out their YouTube for various videos that include tutorials, customer success videos etc.
Learn More About:
Conclusion
As can be gathered from the article so far, the Snowflake Data Warehouse is a secure, scalable, and popular cloud data warehousing solution. It has achieved this status by constantly re-engineering and catering to a wide variety of industrial use cases that helped win over so many clients. You can have a good working knowledge of Snowflake by understanding Snowflake Create Table.
Understand how Snowflake’s data model supports complex business needs. More at Snowflake Modeling.
Businesses can use automated platforms like Hevo Data to set the integration and handle the ETL process. It helps you directly transfer data from a source of your choice to a Data Warehouse, Business Intelligence tools, or any other desired destination in a fully automated and secure manner without having to write any code and will provide you with a hassle-free experience.
Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
FAQs
1. Why is Snowflake better than SQL?
Snowflake’s approach to data modeling is a schema-less approach. This will help you to efficiently store and query data without a predefined schema. On the other hand, SQL Server has a traditional relational data modeling approach which needs creating schemas before you can store your data.
2. Snowflake warehouse vs. database
Snowflake and a database are different in the sense that Snowflake is built of database architectures and utilizes database tables to store data. It also uses massively parallel processing capability to compute clusters to process queries for the data stored in it. A database is an electronically stored and structured data collection.
3. What is the difference between Snowflake and ETL?
Snowflake is a good SaaS data cloud platform and data warehouse that can store and help you query your data efficiently. ETL (extract, transform, and load) is the process of moving data from various data sources to a single destination, such as a data warehouse.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



