

Apache Spark has especially been a popular choice among developers as it allows them to build applications in various languages such as Java, Scala, Python, and R.
Whereas, Amazon Redshift is a petabyte-scale Cloud-based Data Warehouse service. It is optimized for datasets ranging from a hundred gigabytes to a petabyte can effectively analyze all your data by allowing you to leverage its seamless integration support for Business Intelligence tools.
In this blog, we’ll explore the key differences, strengths, and ideal use cases for Spark vs Redshift, helping you make an informed decision based on your business requirements.
Table of Contents
Why use Apache Spark?
Some of its salient features are as follows:
- Accelerated Processing Capabilities
- Ease-to-use
- Advanced Analytics
- Fault Tolerance
- Real-time Processing
1) Accelerated Processing Capabilities
Spark processes data across Resilient Distributed Datasets (RDDs) and reduces all the I/O operations to a greater extent when compared to MapReduce. It performs 100x faster in-memory, and 10x faster on disk. It’s also been used to sort 100 TB of data 3 times faster than Hadoop MapReduce on one-tenth of the machines.
2) Ease-to-use
Spark supports a wide variety of programming languages to write your scalable applications. It also provides 80 high-level operators to comfortably design parallel apps. Adding to its user-friendliness, you can even reuse the code for batch-processing, joining streams against historical data, or running ad-hoc queries on stream state.
3) Advanced Analytics
Spark can assist in performing complex analytics including Machine Learning and Graph processing. Spark’s brilliant libraries such as SQL & DataFrames and MLlib (for ML), GraphX, and Spark Streaming have seamlessly helped businesses tackle sophisticated problems. You also get better speed for analytics as Spark stores data in the RAM of the servers which is easily accessible.
Say goodbye to the hassle of manually connecting Redshift. Embrace Hevo’s user-friendly, no-code platform to streamline your data migration effortlessly.
Choose Hevo to:
- Access 150+(60 free sources) connectors, including Redshift.
- Ensure data accuracy with built-in data validation and error handling.
- Eliminate the need for manual schema mapping with the auto-mapping feature.
Don’t just take our word for it—try Hevo and discover how Hevo has helped industry leaders like Whatfix connect Redshift seamlessly and why they say,” We’re extremely happy to have Hevo on our side.”
Move PostgreSQL Data for Free4) Fault Tolerance
Owing to the Sparks RDDs, Apache Spark can handle the worker node failures in your cluster preventing any loss of data. All the transformations and actions are continuously stored, thereby allowing you to get the same results by rerunning all these steps in case of a failure.
5) Real-Time Processing
Unlike MapReduce where you could only process data present in the Hadoop Clusters, Spark’s language-integrated API allows you to process and manipulate data in real-time.
Spark has an ever-growing community of developers from 300+ countries that have constantly contributed towards building new features improving Apache Spark’s performance. To reach out to them, you can visit the Spark Community page.
Why Use Amazon Redshift?
The key features of Amazon Redshift are as follows:
1) Massively Parallel Processing (MPP)
Massively Parallel Processing (MPP) is a distributed design approach in which the divide and conquer strategy is applied by several processors to large data jobs. A large processing job is broken down into smaller jobs which are then distributed among a cluster of Compute Nodes. These Nodes perform their computations parallelly rather than sequentially. As a result, there is a considerable reduction in the amount of time Redshift requires to complete a single, massive job.
2) Fault Tolerance
Data Accessibility and Reliability are of paramount importance for any user of a database or a Data Warehouse. Amazon Redshift monitors its Clusters and Nodes around the clock. When any Node or Cluster fails, Amazon Redshift automatically replicates all data to healthy Nodes or Clusters.
3) Redshift ML
Amazon Redshift houses a functionality called Redshift ML that gives data analysts and database developers the ability to create, train and deploy Amazon SageMaker models using SQL seamlessly.
4) Column-Oriented Design
Amazon Redshift is a Column-oriented Data Warehouse. This makes it a simple and cost-effective solution for businesses to analyze all their data using their existing Business Intelligence tools. Amazon Redshift achieves optimum query performance and efficient storage by leveraging Massively Parallel Processing (MPP), Columnar Data Storage, along with efficient and targeted Data Compression Encoding schemes.
Redshift can get a little costly to use, Optimize your Redshift Cost with this detailed guide.
Spark vs Redshift: Key Differences
| Aspect | Spark | Redshift |
| Data Processing | Distributed in-memory processing (batch and real-time) | SQL-based, columnar data processing |
| Storage | Supports various data sources (HDFS, S3, etc.) | Uses a columnar storage model within Redshift clusters |
| Performance | High-performance for complex computations and iterative algorithms | Optimized for fast querying with massively parallel processing (MPP) |
| Query Language | Supports SQL, Scala, Python, R, and Java | Primarily SQL, with support for standard SQL functions |
| Real-time Processing | Excellent for real-time processing and streaming data | Primarily designed for batch processing (though can integrate with streaming tools). |
| Cost | Open source (but costs may arise from cloud infrastructure and compute) | Pay-per-usage (based on instance type and storage). |
Comparative Study of Spark vs Redshift
To analyze the comparative study of Spark vs Redshift for Big Data, you can take into consideration the following factors.
- Spark vs Redshift: Usage
- Spark vs Redshift: Data Architecture
- Spark vs Redshift: Data Engineering
- Spark vs Redshift: Final Decision
1) Spark vs Redshift: Usage
Apache Spark
The Apache Spark Streaming platform is a Data Processing Engine that is open source. Spark enables the real-time processing of batch and streaming workloads. It is developed in Java, Scala, Python, and R, and it builds applications using pre-built libraries.
It is a quick, simple, and scalable platform that accelerates development and makes applications more portable and faster to operate.
Amazon Redshift
Amazon Redshift is a Fully Managed Analytical Database that handles tasks such as constructing a central Data Warehouse, conducting large and complicated SQL queries, and transferring the results to the dashboard.
Redshift receives raw data and processes and transforms it. Amazon Redshift is a service that allows you to analyze larger and more complicated datasets.
2) Spark vs Redshift: Data Architecture
In simple terms, you can use Apache Spark to build an application and then use Amazon Redshift both as a source and a destination for data.
A key reason for doing this is the difference between Spark and Redshift in the way of processing data, and how much time each of the tools takes.
- With Spark, you can do Real-time Stream Processing: You get a real-time response to events in your data streams.
- With Redshift, you can do near-real-time Batch Operations: You ingest small batches of events from data streams and then run your analysis to get a response to events.
Let’s take a real-life application to showcase the usage of both Apache Spark and Amazon Redshift.
Fraud Detection: You could build an application with Apache Spark that detects fraud in real-time from e.g. a stream of bitcoin transactions. Given its near-real-time character, Amazon Redshift would not be a good fit for the given use case.
Suppose if you want to have more signals for your Fraud Detection, for better predictability. You could load data from Apache Spark into Amazon Redshift. There, you join it with historic data on fraud patterns. But you can’t do that in real-time, the result would come too late for you to block the transaction. So you use Spark to e.g. block a transaction in real-time, and then wait for the result from Redshift to decide if you keep blocking it, then you can send it to a human for verification, or approve it.
You can also refer to the Big Data blog, “Powering Amazon Redshift Analytics with Apache Spark and Amazon Machine Learning” published by Amazon that showcases the usage of both Apache Spark and Amazon Redshift. The post covers how to build a predictive app that tells you how likely a flight will be delayed. The prediction happens based on the time of day or the airline carrier, by using multiple data sources and processing them across Spark and Redshift.
The image given below illustrates the process flow for the following blog.
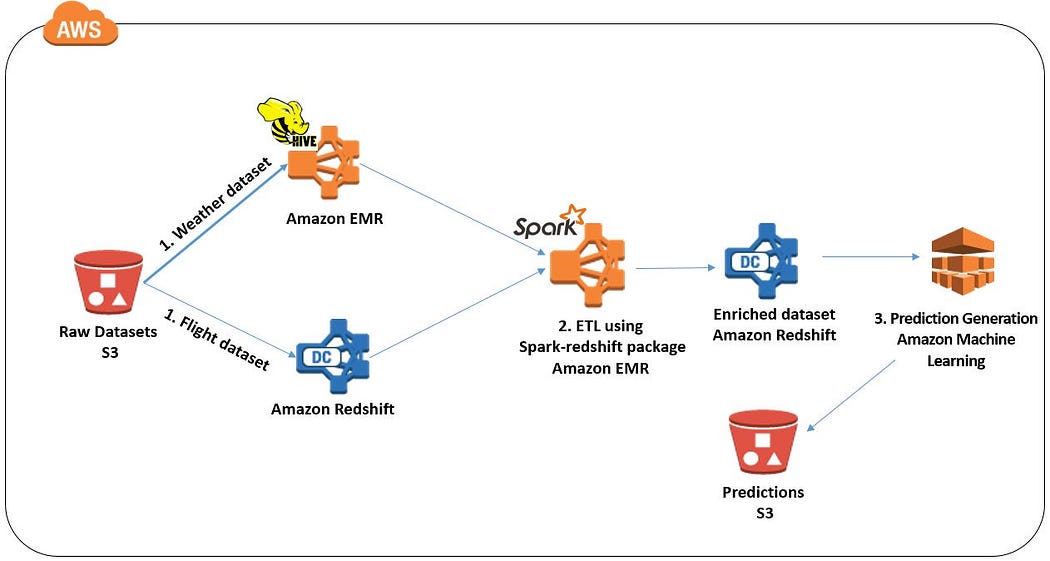
In the above process, it can be seen that the separation of Applications and Data Warehousing showcased in the article is in reality an area that’s shifting or even merging.
3) Spark vs Redshift: Data Engineering
The traditional difference between Developers and BI analysts/Data Scientists is starting to fade, which has given rise to a new occupation: data engineering.
Maxime Beauchemin, creator of Apache Superset and Apache Airflow states “In relation to previously existing roles, the Data Engineering field [is] a superset of Business Intelligence and Data Warehousing that brings more elements from software engineering, [and it] integrates the operation of ‘big data’ distributed systems”.
Apache Spark is one such “Big data” Distributed system, and Amazon Redshift comes under Data Warehousing. And Data engineering is the field that integrates them into a single entity.
Learn about Best Data Engineering Tools for 2025 and enhance your data operations.
4) Spark vs Redshift: Final Decision
In this Spark vs Redshift comparative study, we’ve discussed:
- Use Cases: Apache Spark is designed to increase the speed and performance of application development, whereas Amazon Redshift is designed to crunch big datasets more rapidly and effectively.
- Data Architecture: Apache Spark is best suited for real-time stream processing, whereas Amazon Redshift is best suited for batch operations that aren’t quite in real-time.
- Data Engineering: The discipline of “Data Engineering,” which includes Data Warehousing, Software Engineering, and Distributed Systems, unites Apache Spark with Amazon Redshift.
You’ll almost certainly end up utilizing both Apache Spark and Amazon Redshift in your big data architecture, each for a distinct use case that it’s best suited for. We can stick to the notion that they serve diverse use cases and that the tool to employ is determined by the use cases.


Conclusion
In conclusion, both Apache Spark and Amazon Redshift offer powerful capabilities, but they serve different purposes in the world of big data processing and analytics. Spark excels in real-time data processing, machine learning, and complex ETL workflows, while Redshift shines when it comes to data warehousing and fast, scalable querying of structured data.
The choice between the two largely depends on your use case—whether you need a flexible, distributed processing engine (Spark) or a robust, managed data warehouse for analytical queries (Redshift). Understanding these key differences will help you leverage the right tool for your data needs. Sign up for Hevo’s 14-day free trial and integrate Redshift easily within minutes.
Frequently Asked Questions
1. What is the difference between Spark and Redshift spectrum?
Spark is a general-purpose data processing engine, while Redshift Spectrum is specific to querying data in Amazon S3 using Redshift.
2. Can you use Spark with Redshift?
Yes, you can use Apache Spark with Amazon Redshift. Spark can interact with Redshift via JDBC or by using AWS Glue as a data integration tool. This allows you to read and write data between Redshift and Spark or process large-scale data in Spark and store results in Redshift.
3. What is the difference between Apache Spark and AWS?
Spark is a data processing engine, while AWS is a cloud platform offering a wide variety of cloud-based infrastructure and services, including Spark as a managed service (e.g., Amazon EMR).
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




