



Splunk is a software platform widely used for monitoring, searching, analyzing, and visualizing machine-generated data in real-time. It performs capturing, indexing, and correlating the real-time data in a searchable container and produces graphs, alerts, dashboards, and visualizations. Splunk provides easy to access data over the whole organization for easy diagnostics and solutions to various business problems.
In this article, you will gain information about Splunk Data Ingestion Methods. You will also gain a holistic understanding of Splunk, its key features, data ingestion, input types and data sources supported by Splunk, the best Splunk Data Ingestion Methods, and a demo that showcases an example on the Splunk Data Ingestion Methods.
Read along to find out in-depth information about Splunk Data Ingestion Methods.
Hevo Data, an Automated No Code Data Pipeline, a fully managed Data Pipeline platform, can help you automate, simplify & enrich your data replication process in a few clicks. With Hevo’s wide variety of connectors and blazing-fast Data Pipelines, you can extract & load data from 150+ Data Sources straight into your Data Warehouse or any Databases.
To further streamline and prepare your data for analysis, you can process and enrich raw granular data using Hevo’s robust & built-in Transformation Layer without writing a single line of code!
Get Started with Hevo for FreeTable of Contents
What is Data Ingestion?
There is a massive amount of data coming from various sources, including your website, mobile application, REST Services, external queues, and even your own business systems. Data must be collected and stored securely, with no data loss and as little latency as possible. This is where Data Ingestion enters the picture.
The process of collecting and storing mostly unstructured sets of data from multiple Data Sources for further analysis is referred to as data ingestion. In simple terms, it is a process by which data is transferred from one point of origin to another, where it can then be stored and analyzed. The data transferred during the data ingestion process could be from any format, such as DBMS, RDBMS, files such as CSVs, and so on. It is preferable to clean and munge the data before analyzing it; otherwise, the data will not make sense.
This data can be accessed in real-time or in batches. When real-time data arrives, it is ingested immediately, whereas batch data is ingested in chunks at regular intervals.
There are basically 3 different layers of Data Ingestion.
- Data Collection Layer: This layer of the Data Ingestion process decides how the data is collected from resources to build the Data Pipeline.
- Data Processing Layer: This layer of the Data Ingestion process decides how the data is getting processed which further helps in building a complete Data Pipeline.
- Data Storage Layer: The primary focus of the Data Storage Layer is on how to store the data. This layer is mainly used to store huge amounts of real-time data which is already getting processed from the Data Processing Layer.
Input Types & Data Sources Supported by Splunk
Data Sources
The different data sources supported by Splunk are as follows.
- Web and Cloud Services
- IT operations and network security
- Databases
- Application and Operating system data
1) Web and Cloud Services
- Apache and Microsoft IIS are the most widely used web servers.
- Linux-based web services are hosted on Apache, while Windows-based web services use IIS.
- Linux web server logs are simple plain text files.
- Microsoft IIS logs can be in W3C-extended format or stored in a database using the ODBC format.
- Cloud services like Amazon AWS, S3, and Microsoft Azure can connect to Splunk Enterprise for data forwarding.
- Splunk offers various technology add-ons to create data inputs from cloud services to Splunk Enterprise.
- Splunk has a preconfigured source type for Apache logs, which formats the data for effective visualization.
2) IT operations and network security
- Splunk Enterprise offers many apps in the Splunk app store focused on IT operations and network security.
- Splunk is widely used for intrusion detection, network security, fraud detection, theft detection, user behavior analytics, and compliance.
- A Splunk Enterprise app provides built-in support for Cisco ASA firewall, Cisco SYSLOG, CDR logs, and Snort intrusion detection.
- The Splunk app store has numerous add-ons to collect data from security devices like firewalls, routers, and DMZ.
- The app store also features a Splunk application that provides graphical insights and analytics for data from IT and security devices.
3) Databases
- Splunk Enterprise supports databases like MySQL, Oracle Syslog, and IBM DB2.
- Technology add-ons on the Splunk app store allow data retrieval from Oracle and MySQL databases.
- These add-ons can retrieve, parse, and upload data from databases to the Splunk Enterprise server.
- A single source can generate multiple types of data, and Splunk supports all data types from a given source.
4) Application and Operating system data
- Splunk has built-in configurations for Linux dmesg, syslog, security logs, and other Linux logs.
- It also provides data input configurations for Windows and iOS logs.
- Splunk includes default Log4j-based logging for Java, PHP, and .NET enterprise applications.
- Splunk supports data from various applications like Ruby on Rails, Catalina, WebSphere, and more.
- It offers predefined configurations for applications, databases, operating systems, and cloud/virtual environments, enhancing data parsing and event breakdown for better insights.
- For sources without built-in settings, apps or add-ons from the Splunk app store can be used.

Input Methods
Splunk offers tools for configuring various kinds of data inputs, including those unique to application needs. Splunk also provides the tools to configure input forms of any arbitrary data. In general, Splunk inputs can be defined as follows:
1) Files and directories
Splunk Enterprise offers a simple interface for uploading data via files and directories. Files can be uploaded manually from the Splunk web interface, or you can configure Splunk to monitor the file for changes in content and upload new data to Splunk whenever it is written in the file.
Splunk can also be configured to upload multiple files by either uploading all of the files at once or monitoring the directory for new files and indexing the data on Splunk as it arrives. You can use files and directories to track input processors in order to get data from them.
2) Network events
Splunk accepts data from network sources via TCP and UDP. It can scan any network port for incoming data and index it in Splunk. For increased reliability, you can use TCP whenever possible.
Splunk Enterprise can also accept and catalog SNMP events. In general, when sending data from network sources to Splunk, it is recommended that you use a Universal forwarder, as the Universal forwarder buffers the data in case of any issues on the Splunk server thus preventing data loss.
3) Windows sources
Splunk Cloud and Splunk Enterprise Windows support a wide range of Windows-specific inputs. Splunk Enterprise allows for direct data access from a Windows system. It can handle both local and remote collections of various types and sources from a Windows system. Splunk Web allows us to configure the following Windows-specific input forms:
- Windows Event Log data
- Windows Registry data
- Active Directory data
- WMI data
- Active Directory data
- Performance monitoring data
Splunk includes predefined input methods and settings for parsing event logs, performance monitoring reports, registry information, hosts, networks, and print monitoring of both local and remote Windows systems.
To search and index Windows data on a non-Windows instance of Splunk Enterprise, you must first gather the data on a Windows instance.
4) Other input types
Splunk software also supports different kinds of data sources. For example:
- Metrics
- First-in, first-out (FIFO) queues
- Scripted inputs
- Modular inputs
- The HTTP Event Collector endpoints
Best Splunk Data Ingestion Methods
In Splunk, data is ingested by selecting the “Add Data” option. This is the second option available on the welcome screen or the default dashboard, as shown in the image below.
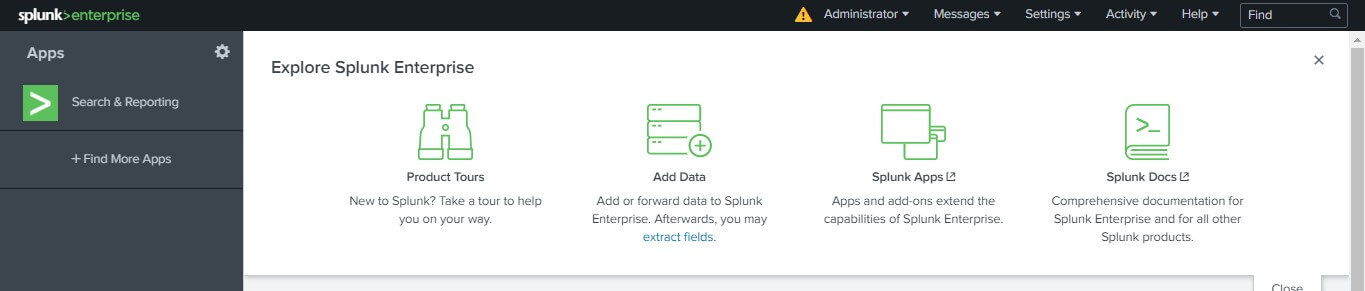
This option allows you to import or forward data into Splunk. It can be used to extract the data’s essential features after it has been added.
The Add Data window appears on the screen after you click the “Add Data” button. You can then select the type of data to send to the Splunk platform. These options are:
- Splunk Data Ingestion Methods: Upload
- Splunk Data Ingestion Methods: Monitor
- Splunk Data Ingestion Methods: Forward
1) Splunk Data Ingestion Methods: Upload
The Upload option is used to upload the data from an external source into our system. Through this option you can upload data in a variety of file formats in your systems. The following image illustrates the different file formats supported by the Upload option.
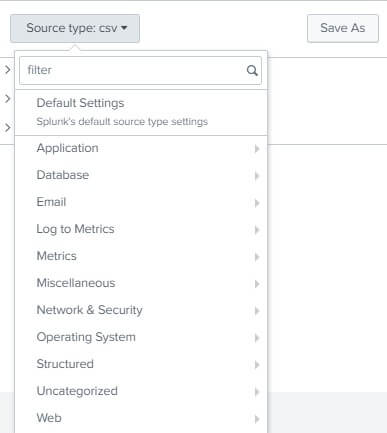
2) Splunk Data Ingestion Methods: Monitor
If you have the need to monitor data from any outer source such as any website, app, etc. in the Splunk platform, then in that case you can use the monitor option. For example, HTTP, WMI, TCP/UDP, etc.
3) Splunk Data Ingestion Methods: Forward
You can get the incoming data and visualize it in Splunk Forwarder by using the forward option.
Key Features of Splunk Forwarders
- Function: Retrieves data from various sources like system logs, application logs, and network traffic.
- Deployment: Installed on the source machine where the data is created.
- Lightweight: Optimized to have minimal impact on the performance of the source system.
Demo : Splunk Data Ingestion Methods
In order to understand the steps involved for data ingestion in Splunk, you can consider the following example. This is a step-by-step guide to ingest a data file in the Spunk dashboard.
- Step 1: Go to the Splunk CLI, and start the Splunk server.
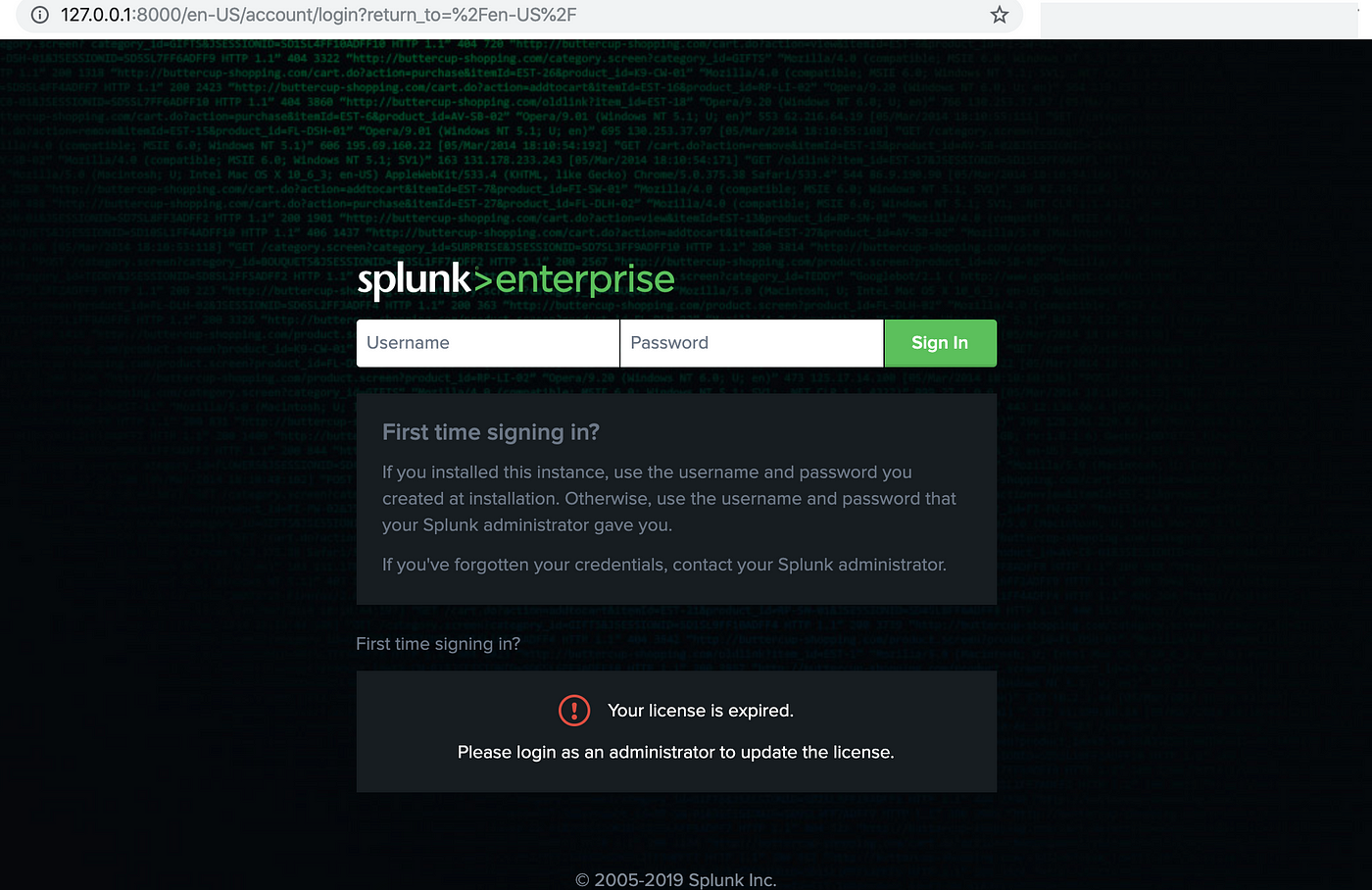
- Step 2: The login page appears. You can log in with your Splunk credentials.
- Step 3: After successfully logging in, you will be navigated to the Splunk dashboard. On the top bar, click on the “Settings” tab.
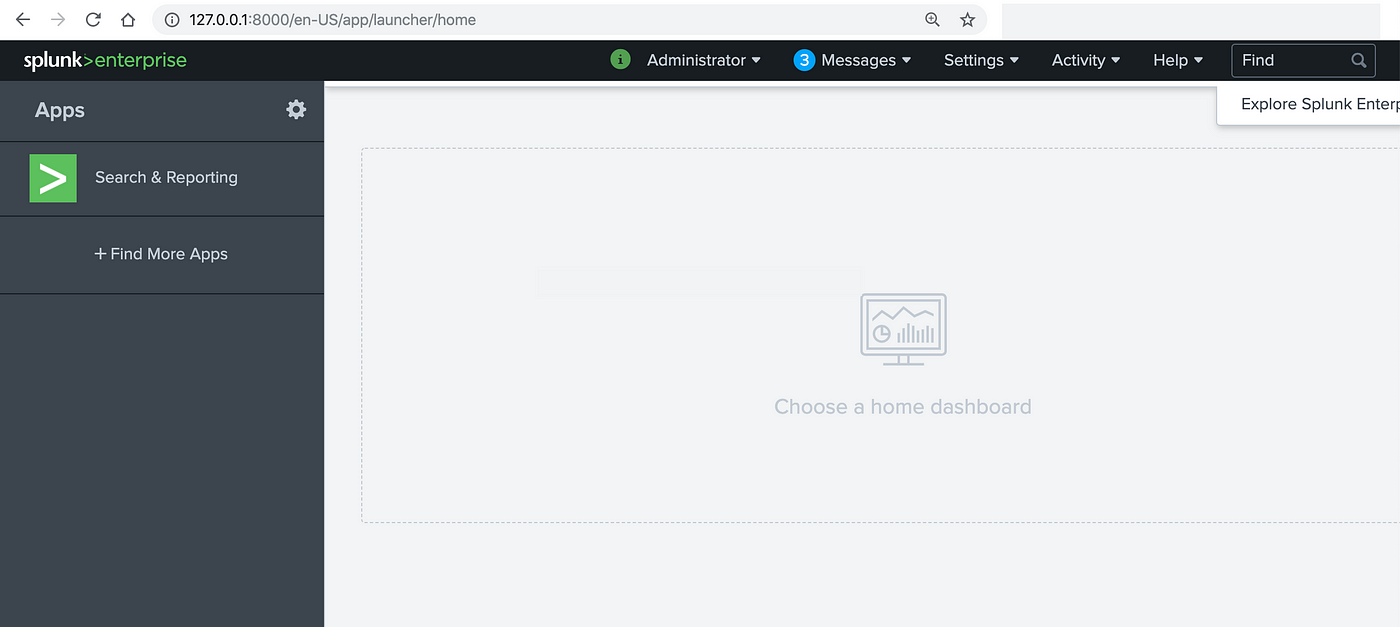
- Step 4: Now, select the “Add Data” option.
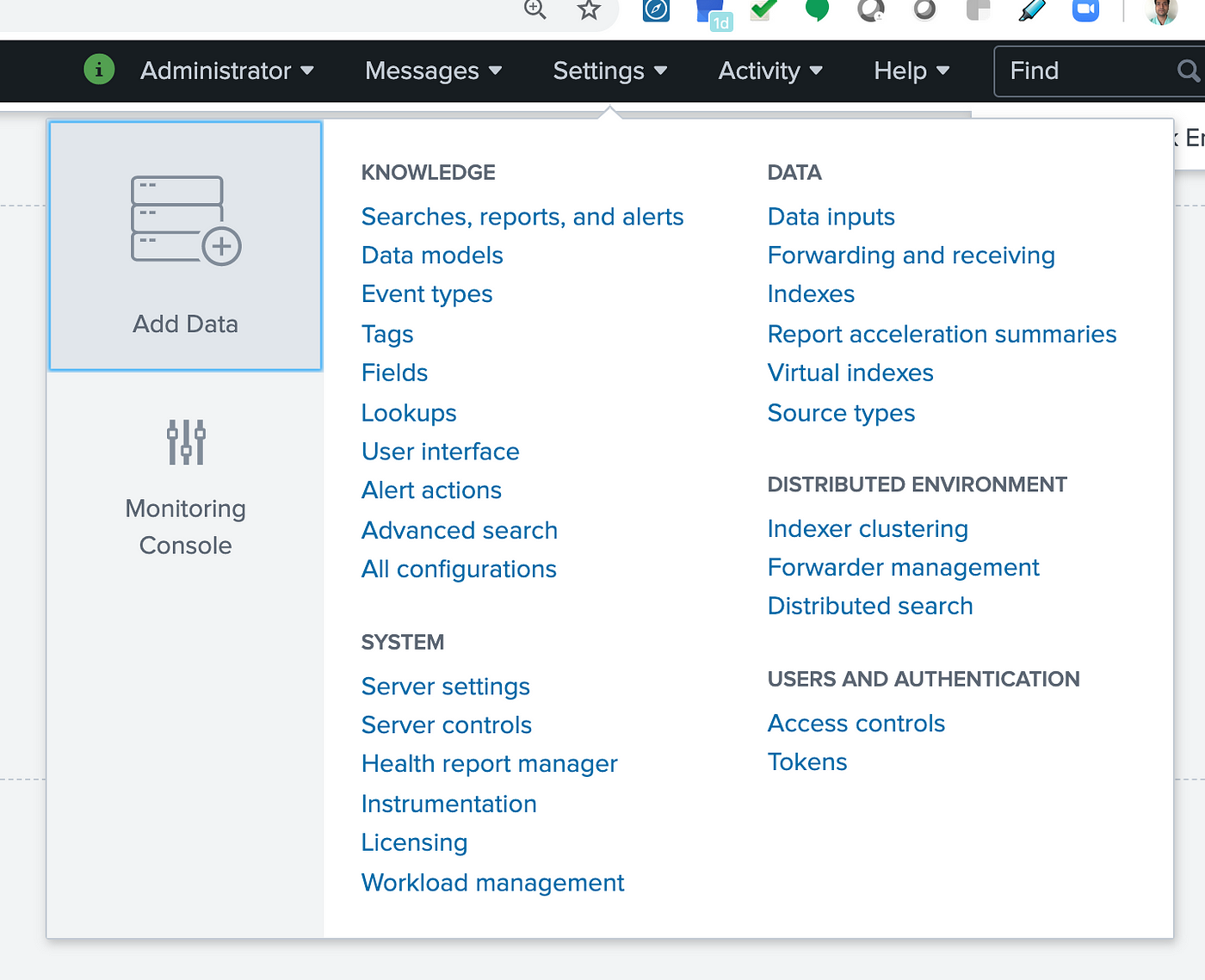
- Step 5: In the next window that appears, select the “Upload” option.
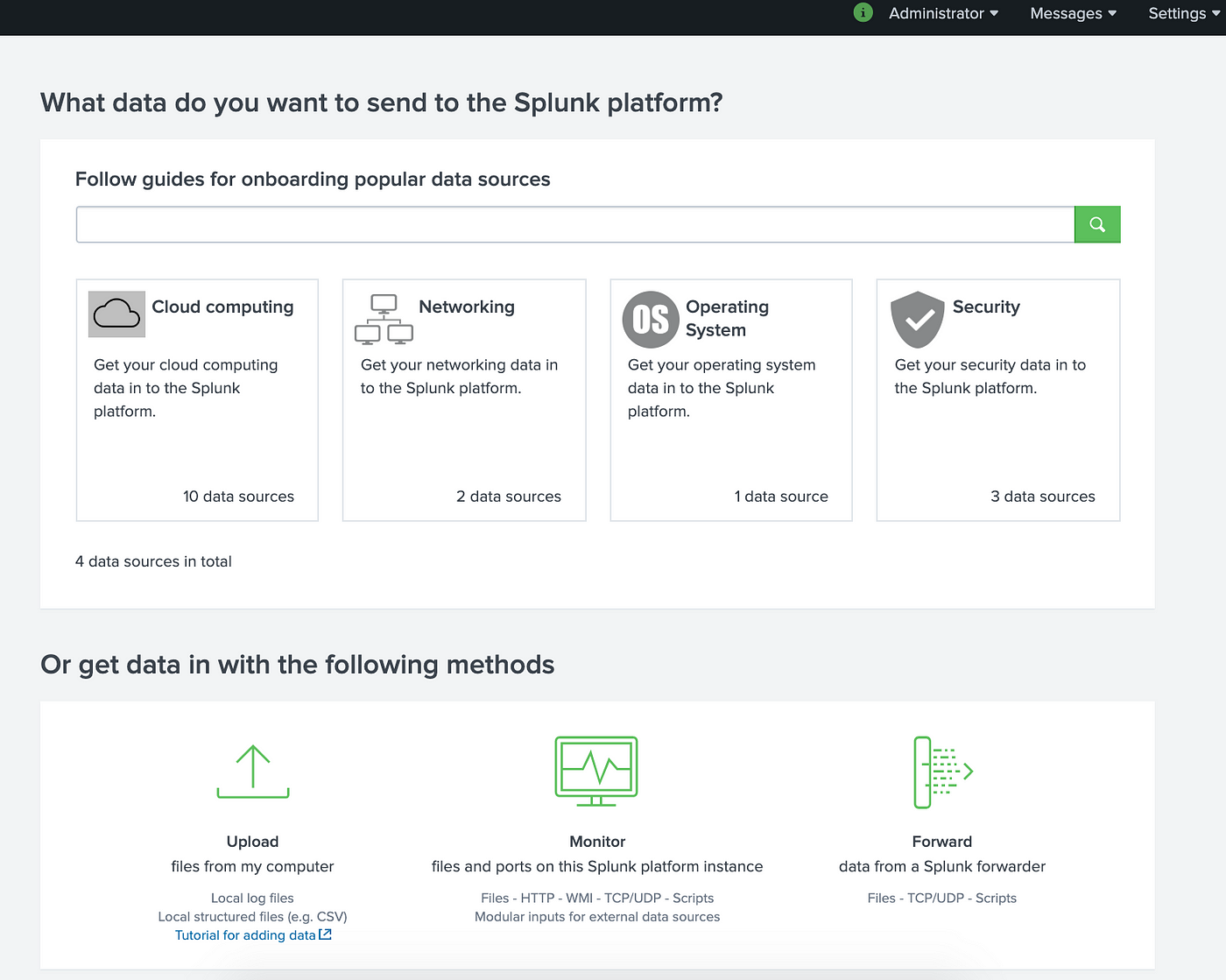
- Step 6: In the Select Source window that appears, select the file that is to be uploaded. In this example, this sample data file has been uploaded.
https://docs.splunk.com/Documentation/Splunk/8.0.1/SearchTutorial/Systemrequirements#Download_the_tutorial_data_files
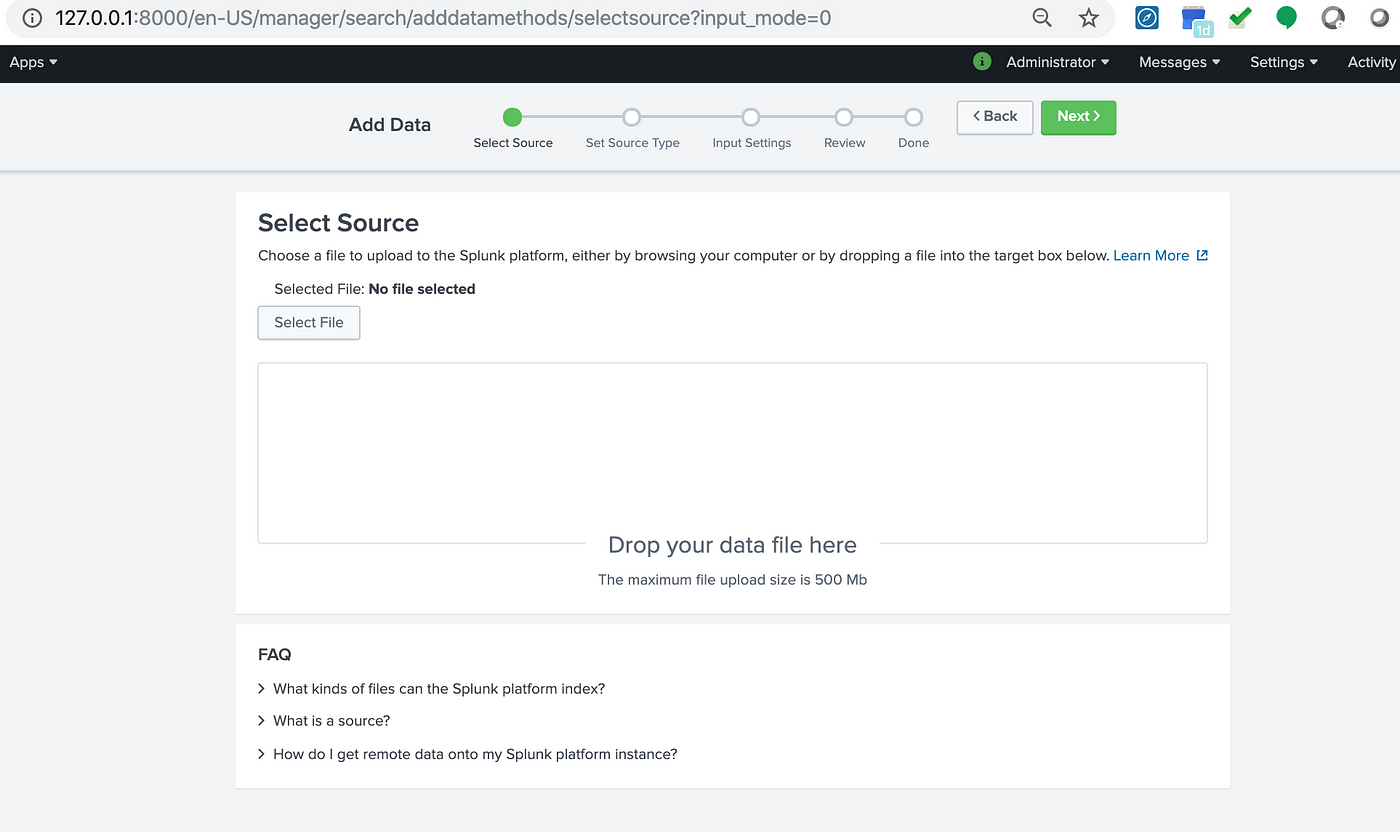
- Step 7: It allows you to configure the data input settings so that data is indexed according to the settings you specify.
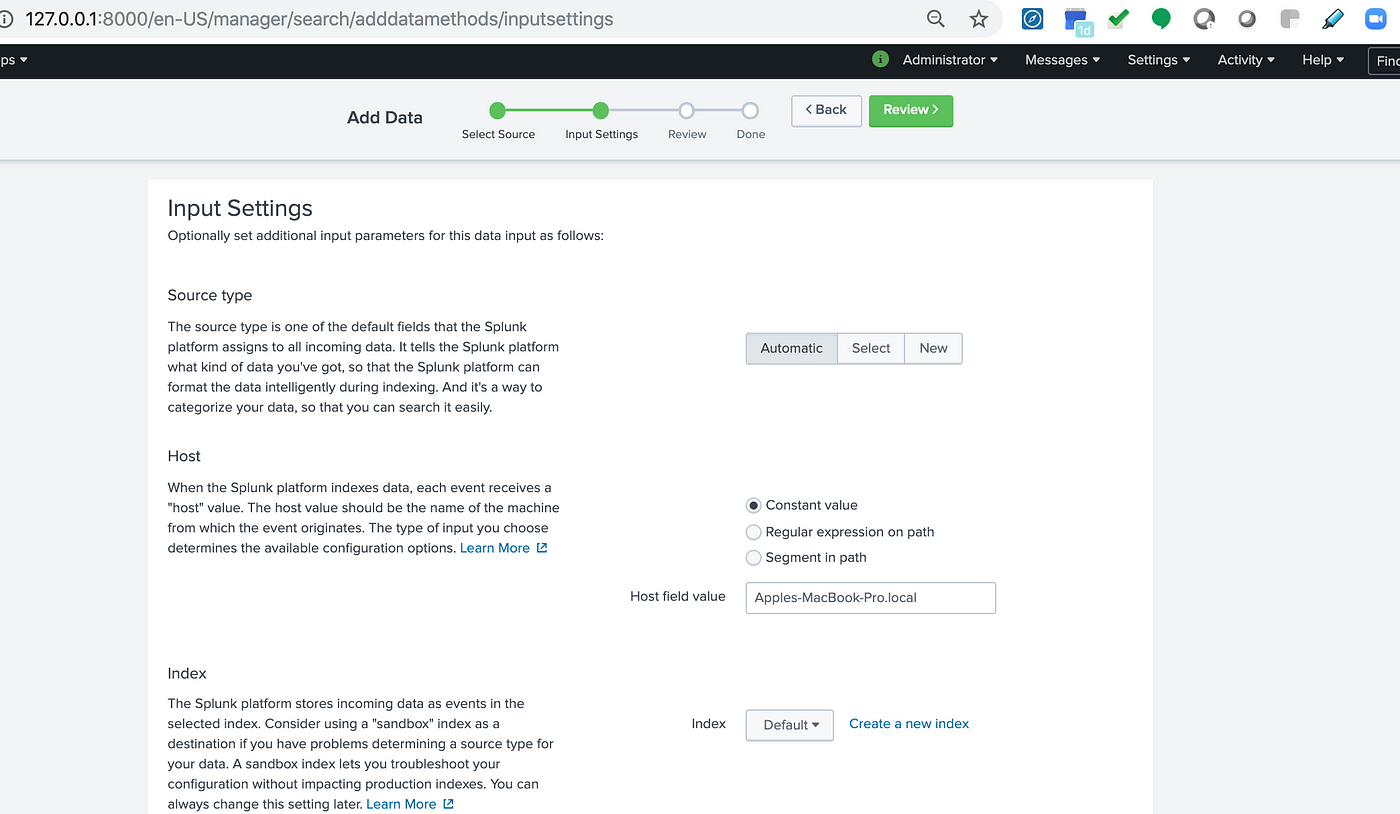
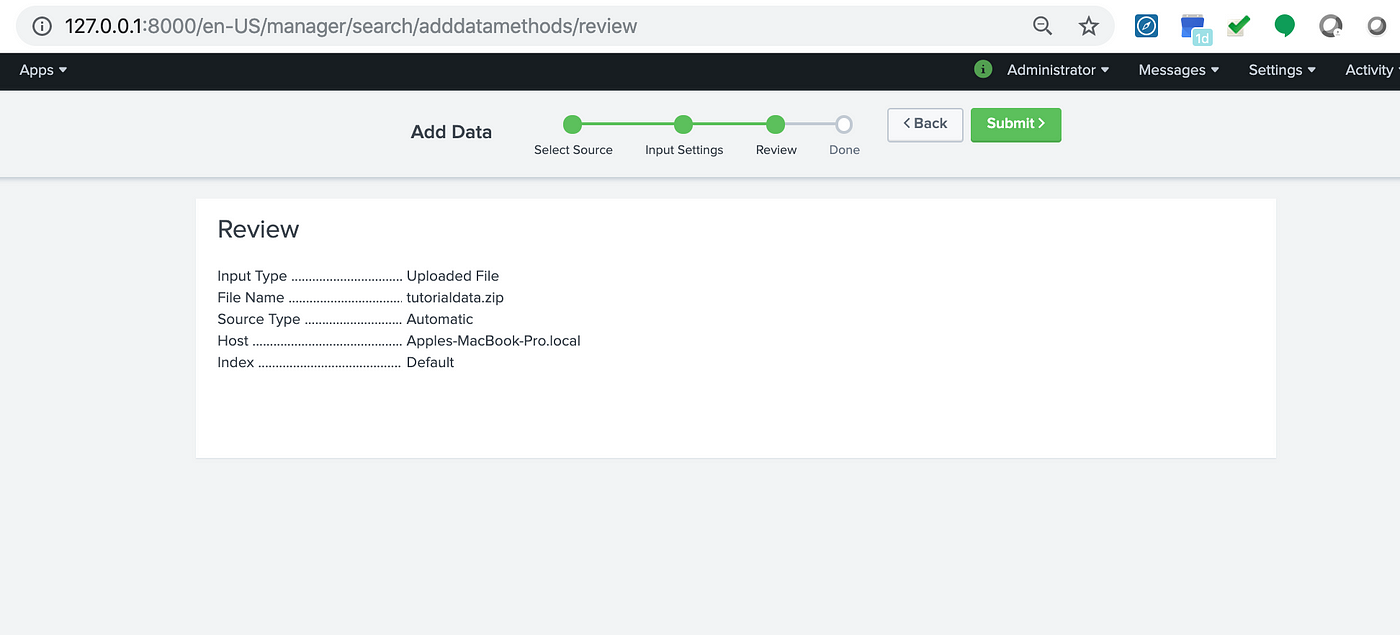
- Step 8: The Review Page appears. You can check through all the actions. Then, click on the “Submit” button.
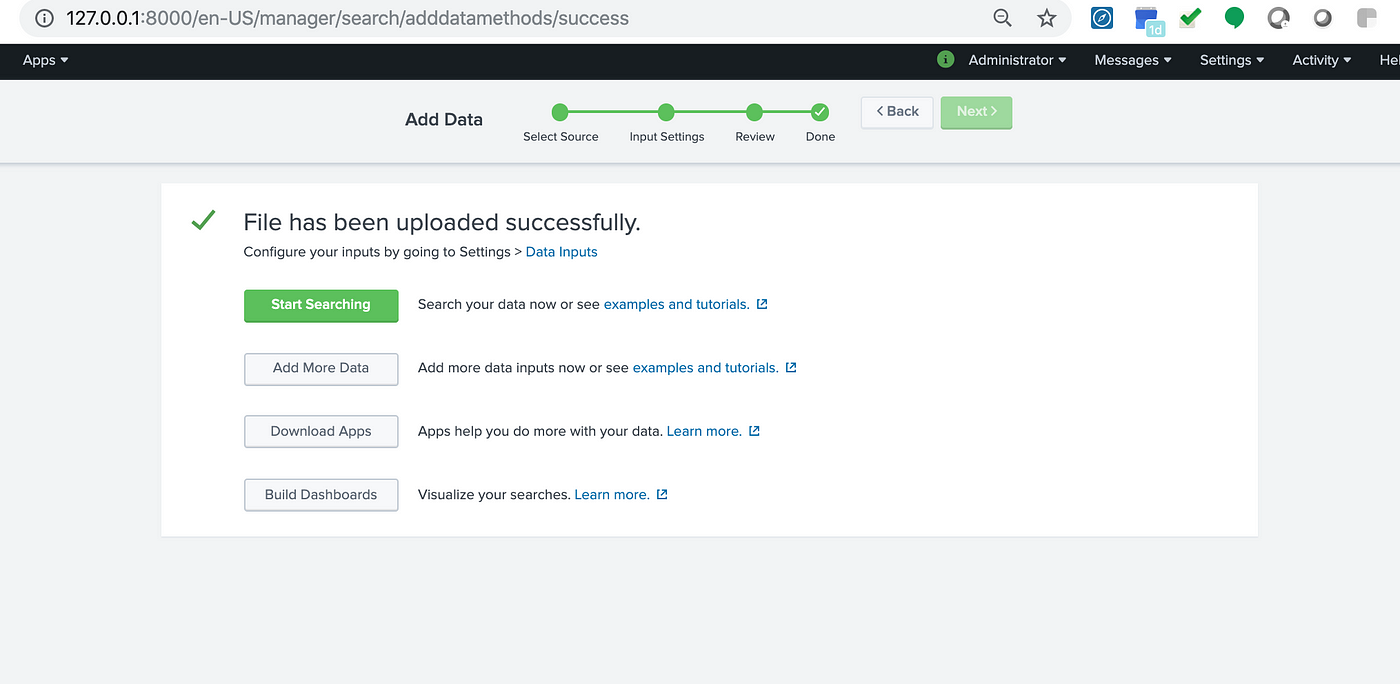
The file will now be uploaded.
Conclusion
In this article, you have learned about Splunk Data Ingestion Methods. This article also provided information on Splunk, its key features, data ingestion, input types and data sources supported by Splunk, 3 Splunk Data Ingestion Methods and a demo that showcases an example on the Splunk Data Ingestion Methods.
Hevo Data, a No-code Data Pipeline provides you with a consistent and reliable solution to manage data transfer between a variety of sources and a wide variety of Desired Destinations with a few clicks.
Hevo Data with its strong integration with 150+ Data Sources (including 60+ Free Sources) allows you to not only export data from your desired data sources & load it to the destination of your choice but also transform & enrich your data to make it analysis-ready. Hevo also allows the integration of data from non-native sources using Hevo’s in-built REST API & Webhooks Connector. You can then focus on your key business needs and perform insightful analysis using BI tools.
Want to give Hevo a try? Explore Hevo’s 14-day free trial and experience the feature-rich Hevo suite first hand. You may also have a look at the amazing price, which will assist you in selecting the best plan for your requirements.
Share your experience of understanding Splunk Data Ingestion Methods in the comment section below! We would love to hear your thoughts on Splunk Data Ingestion Methods.
FAQs
1) What are the different types of data ingestion methods?
The main data ingestion methods include batch ingestion, where data is collected and processed in set intervals, and streaming ingestion, where data is processed in real-time as it’s generated. Additionally, API-based ingestion allows direct data collection via APIs from various sources.
2) How is data ingested into Splunk?
Data is ingested into Splunk through various methods, including file monitoring, forwarders, and APIs. Splunk can also pull data from external sources like databases, cloud services, or syslogs, and process it in real-time or in batches for indexing and analysis.
3) Which Splunk component stores ingested data?
The indexer component in Splunk stores ingested data. It indexes the data and makes it searchable, enabling efficient retrieval for analysis and visualization.
4) which component is used to collect and send data over the splunk instance?
The component used to collect and send data over a Splunk instance is a Splunk Forwarder. It’s a lightweight agent installed on the source machine that collects logs and transmits them to the Splunk indexer for processing and storage.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





