




Easily move your data from Kafka to Redshift to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time. Check out our 1-minute demo below to see the seamless integration in action!
Are you struggling to move data from Kafka to Redshift without hitting roadblocks or spending hours on setup? This article walks you through the simplest ways to stream your data seamlessly, whether you prefer a hands-on approach with Kafka Connect or want to set up a real-time pipeline in minutes using Hevo. Let’s get your data where it needs to be, fast and hassle-free.
Table of Contents
Use Cases of Connecting Kafka with Redshift
- Customer Behavior Tracking: Data from customer interactions (e.g., web, mobile app usage) can be streamed via Kafka and loaded into Redshift for behavioral analysis.
- Real-Time Data Analytics: Streaming data from Kafka to Redshift enables businesses to perform real-time analytics on live data, such as tracking user activity, monitoring transactions, or analyzing sensor data.
- Centralized Data Warehousing: Kafka ingests data from multiple distributed systems (IoT devices, apps, databases), and Redshift acts as the centralized data warehouse where this data is stored for reporting and analysis.
Hevo offers a faster way to move data from databases or SaaS applications like Kafka into Redshift to be visualized in a BI tool. Hevo is fully automated and hence does not require you to code.
Check out some of the cool features of Hevo:
- Completely Automated: The Hevo platform can be set up in just a few minutes and requires minimal maintenance.
- Real-time Data Transfer: Hevo provides real-time data migration, so you can have analysis-ready data always.
- 100% Complete & Accurate Data Transfer: Hevo’s robust infrastructure ensures reliable data transfer with zero data loss.
Choose Hevo and see what Whatfix says, with secure integration from 5 sources and 2 months saved in engineering time, Hevo helped boost their data accuracy by 1.2x.
Sign up here for a 14-day free trial!Prerequisites
- We will use the Kafka Connect Amazon Redshift Sink connector to export data from Kafka topics to the Redshift database. To run the Kafka Connect Amazon Redshift Sink connector, you need:
- Confluent platform 3.3.0 or above, or Kafka 0.11.0 or above
- Java 1.8
- INSERT access privilege (at least)
Steps to Stream Data from Kafka to Redshift
Here are the steps to stream data from Kafka to Redshift.
Method 1: Best Way to Connect Kafka to Redshift: Using Hevo
Step 1: Configure your Kafka source details
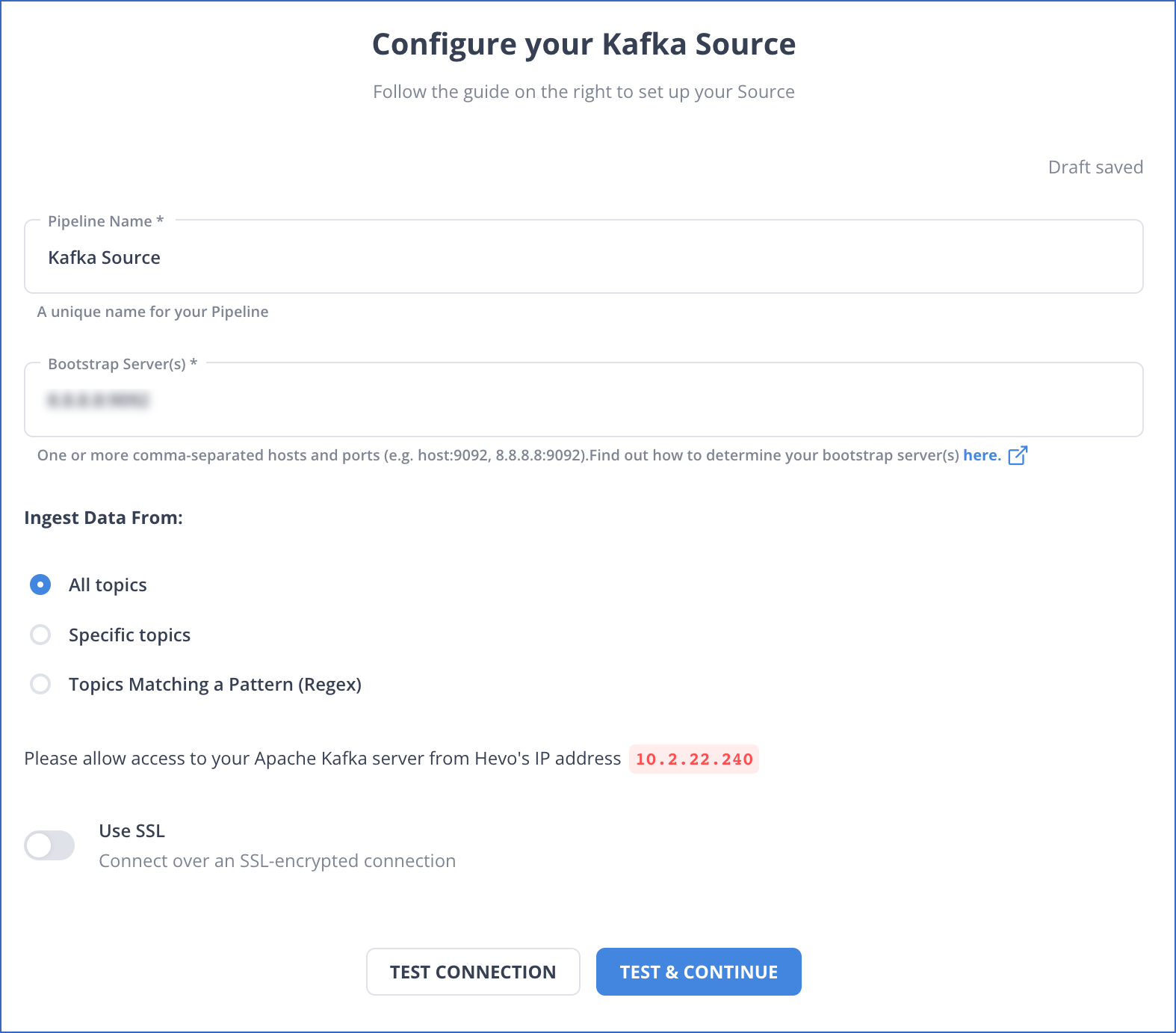
Step 2: Set up your Redshift destination details
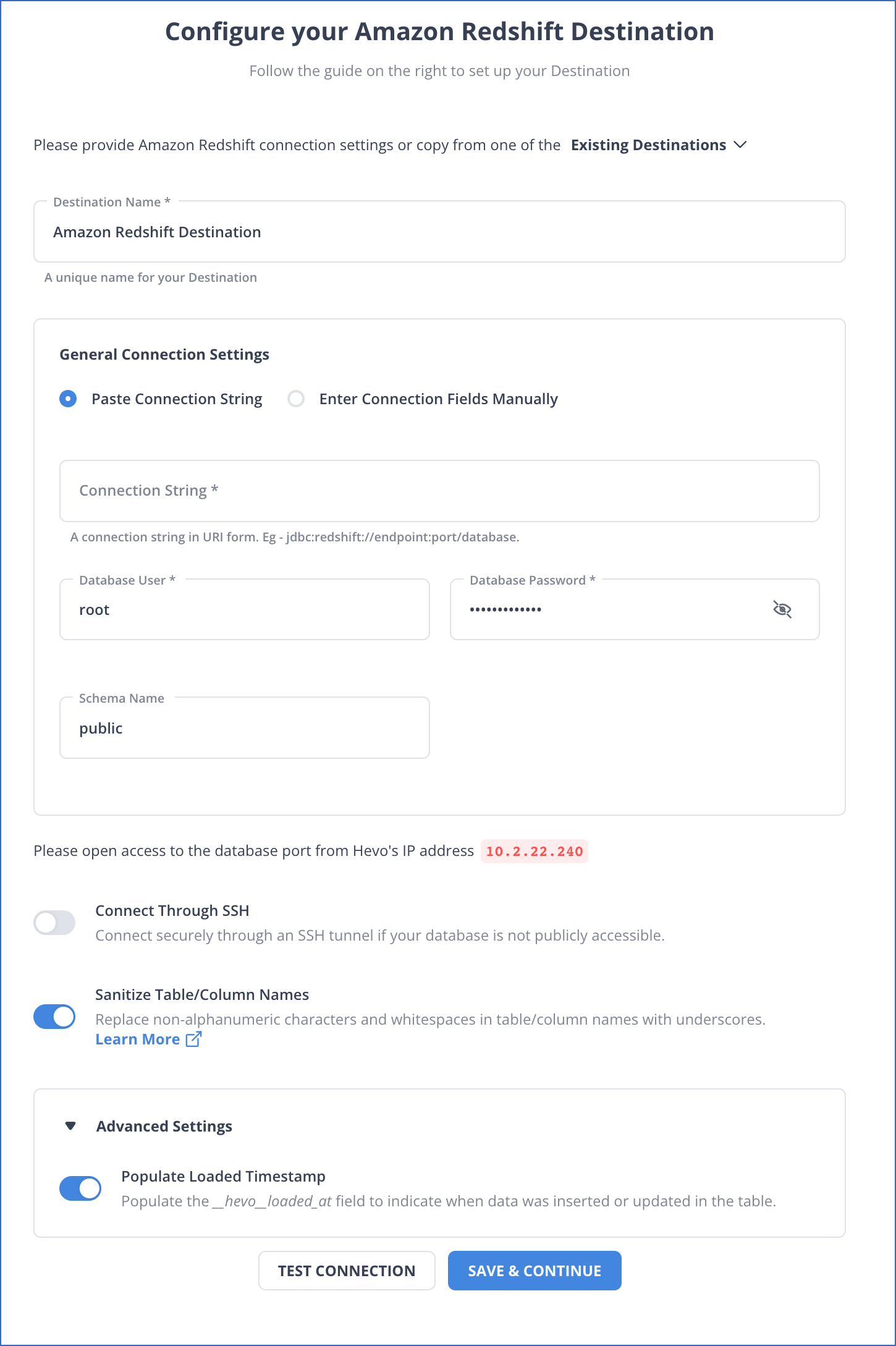
With these simple and straightforward steps, you have successfully connected your source and destination with these two simple steps.
Method 2: Manual method to stream data from Kafka to Redshift
Step 1: Install the Redshift Connector
You can install the latest version of the Redshift connector by running the following command on the Confluent Platform installation directory.
confluent-hub install confluentinc/kafka-connect-aws-redshift:latestStep 2: Install the Redshift JDBC Driver
The connector needs a JDBC driver to connect to Redshift. The JDBC 4.0 driver JAR file that comes with the AWS SDK needs to be placed on each Connect worker node. Download the Redshift JDBC Driver here and place the JAR file into this directory:
share/confluent-hub-components/confluentinc-kafka-connect-aws-redshift/libNow, restart all of the Connect worker nodes.
Step 3: Create an Amazon Redshift Instance
Ensure you have the necessary permissions to create and manage Redshift instances, then log into the AWS Management Console, navigate to Redshift, go to Clusters, select “Quick Launch Cluster,” set the Master User Password, and click “Launch Cluster” to have your cluster ready in a few minutes.
Step 4: Load the Connector
Create a properties file for your Amazon Redshift Sink Connector.
name=redshift-sink
confluent.topic.bootstrap.servers=localhost:9092
confluent.topic.replication.factor=1
connector.class=io.confluent.connect.aws.redshift.RedshiftSinkConnector
tasks.max=1
topics=orders
aws.redshift.domain=< Required Configuration >
aws.redshift.port=< Required Configuration >
aws.redshift.database=< Required Configuration >
aws.redshift.user=< Required Configuration >
aws.redshift.password=< Required Configuration >
pk.mode=kafka
auto.create=trueEnter your cluster configuration parameters as they are in your Cluster Details and load the Redshift sink connector.
confluent local services connect connector load redshift-sink --config redshift-sink.propertiesIf you don’t use CLI, use the following command:
<path-to-confluent>/bin/connect-standalone
<path-to-confluent>/etc/schema-registry/connect-avro-standalone.properties
redshift-sink.propertiesYour output will look like this:
{
"name": "redshift-sink",
"config": {
"confluent.topic.bootstrap.servers": "localhost:9092",
"connector.class": "io.confluent.connect.aws.redshift.RedshiftSinkConnector",
"tasks.max": "1",
"topics": "orders",
"aws.redshift.domain": "cluster-name.cluster-id.region.redshift.amazonaws.com",
"aws.redshift.port": "5439",
"aws.redshift.database": "dev",
"aws.redshift.user": "awsuser",
"aws.redshift.password": "your-password",
"auto.create": "true",
"pk.mode": "kafka",
"name": "redshift-sink"
},
"tasks": [],
"type": "sink"
}Step 5: Produce a Record in Kafka
Produce a record in the orders topic:
./bin/kafka-avro-console-producer
--broker-list localhost:9092 --topic orders
--property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"id","type":"int"},{"name":"product", "type": "string"}, {"name":"quantity", "type": "int"}, {"name":"price", "type": "float"}]}'Enter the following record in the terminal and click Enter:
{"id": 999, "product": "foo", "quantity": 100, "price": 50}Go to Query Editor and execute queries on ‘orders’.
SELECT * from orders;
Limitations of the Manual Method
- Complex Setup and Configuration: Setting up the connection between Kafka and Redshift requires custom coding, manual data pipelines, and management of various components.
- Latency and Real-Time Data Challenges: Redshift is optimized for batch loading, whereas Kafka is designed for real-time streaming. Without specialized tools (e.g., Kafka Connect, Hevo), manually loading data in real-time to Redshift can introduce latency.
- Error Handling and Data Loss: Manual integration lacks robust error-handling mechanisms. If a data stream fails during transmission from Kafka to Redshift, it can result in incomplete or lost data.
- Scalability Issues: Scaling Kafka consumers, data processors, and Redshift clusters in response to growing data volumes is difficult when managed manually.
Conclusion
You have seen how you can use the Kafka Connect Redshift Sink Connector to stream data from Kafka to Redshift. But if you are looking for an automatic tool that will free you from all the hassle, try Hevo Data.
Hevo is a No-Code Data Pipeline as a service. You can instantly start moving your data in real-time from any source to Redshift or other data destinations. Even if your data changes in the future in the form of new tables, columns, or data types, Hevo manages the schema. It is easy to set up, requires minimal maintenance, and is extremely secure.
Sign up for a 14-day free trial with Hevo and experience seamless integration to Redshift.
FAQ on Kafka Redshift
How do you connect Kafka to Redshift?
Use Kafka Connect with the Redshift Sink Connector to stream data from Kafka to Redshift.
Alternatively, write a custom consumer in Python or Java to consume Kafka data and load it into Redshift using JDBC.
What is the difference between Redshift and Kafka?
Redshift is a data warehouse used for analytics, while Kafka is a distributed streaming platform for real-time data pipelines.
How do you send data from Kafka to the database?
To send data from Kafka to a database, use a Kafka Sink Connector (e.g., JDBC Sink Connector) to consume messages from Kafka topics and write them to the target database. Configure and deploy the connector via Kafka Connect to automate the data flow.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link

